Adventures in GraphLand (Part I)
Well over a decade ago, I had the privilege of being one of the first programmers to use ECL. A new language at a new level of abstraction allowed us to think about data absent of process. We were no longer working in the realm of time and method, but in the realm of data. We wanted a name for this place that our minds could now wander; so we called it ‘Dataland’. Since then, many hundreds of programmers have found their way through Dataland; usually heading onto our bigger, stronger but possibly less romantic environments. A few linger to test out new ideas, new platform features or better ways to do things we have done in the past; but ultimately the dream of being able to play with data is no longer a dream: It is the reality for hundreds of people every day.
The question naturally arises, at least to those of us with very short attention spans, what if we could abstract ourselves a level further? What if we could leave behind the world of tables and joins and instead operate in a world where the knowledge just ‘was’? Where questions could be asked and answered; knowledge derived and, somehow, all the data just fell into line? That is the promise of KEL the Knowledge Engineering Language being produced by Eric Blood, Sr Consulting Software Engineer, and his team.
Once again, I am in the privileged position of being among the first programmers to use KEL. As I was hammering out some of my first programs, often with the cursing and mutterings of someone that is well beyond laceration edge, I realized that the language was changing the way I thought about the data. This was not just a way to navigate Dataland faster; I was entering a new place: GraphLand.
Most of my early travails in Dataland have been lost in the sands of time, a stream of adrenaline or the fog of amnesia. As the situation is now (slightly) more leisurely, I thought it might be worth recording some of my early adventures in GraphLand with the hope of paving the way for those that follow.
Naturally big data gets exciting because it is big and real-world; Jo Prichard, Sr Architect and Data Scientist, is exploring some big and very interesting datasets housed within LexisNexis, as we speak. I have given myself a rather different task; I am creating and using a micro-dataset so that I can hand-compute, test and visualize exactly what is happening. My experience is that things that are understood in microcosm can then be intuited at scale.
Sadly, before GraphLand can be truly explored, a bridge needs to be built from Dataland to GraphLand. Much like the cooking shows, where they suddenly announce: “here is one I prepared earlier”, many writings on graph systems assume that somehow the graph magically sprung forth into existence. In contrast, I aim to spend the rest of this blog describing one such bridge (albeit a simple one).
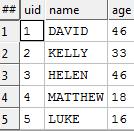
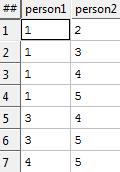
We are going to start with two datasets; one a simple table of people, and the other one a table indicating relationships between them. In our Dataland model we have given all of our entities unique identifiers (indeed, a huge amount of the work done in Dataland is precisely to manufacture these unique identifiers). For this micro-dataset I have allocated nice small numbers by hand.
People:
Relationships:
Within KEL I now need to do two things; tell KEL what my GraphLand entities will look like; and tell KEL where in Dataland to find them. For such a simple data model the first is almost trivial:
Person := ENTITY(FLAT(UID,Name,INTEGER Age)); Relationship := ASSOCIATION(FLAT(Person who, Person whoelse));
We declare that there are people, with three properties, a unique ID, a name and an age. We then declare that relationships are associations between two people. That’s the GraphLand model done. For the people; telling KEL where to find the Dataland version of the file is equally easy:
USE File_Person(FLAT,Person);
File_Person is the Dataland attribute containing my microfile; and we are telling KEL to extract people from it. The slightly harder case is the relationships. In my Dataland file I have one record for a relationship between two people. In GraphLand I want to represent the fact that either person can be the primary (who) person in that relationship. This is handled in the USE statement:
USE File_Relat(FLAT,Relationship(who=person1,whoelse=person2)
,Relationship(who=person2,whoelse=person1));
You can pull multiple entities and associations from a single record of a file. Some of our more complex records (such as a vehicle sale) might have half a dozen entities and relationships in one record, although the precise nature of the linkages is normally encapsulated entirely within people’s minds or within labels upon fields. This implicitstructure in dataland is rendered explicit as the Dataland data is bridged into Graphland. Having brought the data in it, it is usually worth ensuring that nothing got lost; the easiest way is to get GraphLand to do a datadump.
QUERY:Dump <= Person,Relationship;
Produces
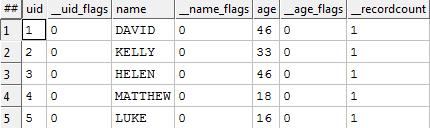
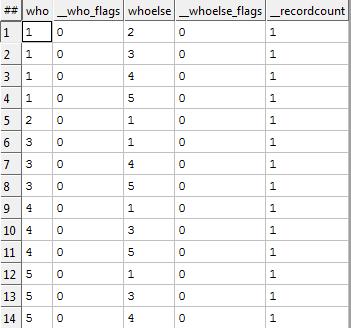
If you look at the data; not much has changed (this is good). Each field has gained an __flags column. As things get more complex, KEL will start to use those flags to capture meta-data information about each field value that is computed. There is also a __recordcount to tell us how many Dataland records attest each fact. The final thing to notice is that we have twice as many relationships due to our use of the two USE statements. Logically I should now declare success and finish this entry; however I don’t want to leave without giving some small inkling of why we would bother to have done all this work. So here is a modified version of the KEL query, in which I use the relationships to give myself a record in which my relations are listed.
QUERY:Dump1 <= Person{UID,Name,Age,{Relationship.whoelse.Name}};
Produces:
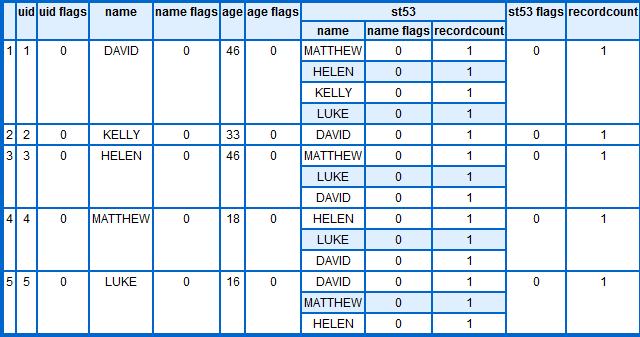
For those of you back in the land of tables and joins, producing the table above from the raw data requires two joins and a project (minimum). Here in the GraphLand things are rather different.
Adventures in Graphland Series
Part I – Adventures in GraphLand
Part II – Adventures in GraphLand (The Wayward Chicken)
Part III – Adventures in GraphLand III (The Underground Network)
Part IV – Adventures in GraphLand IV (The Subgraph Matching Problem)
Part V – Adventures in GraphLand (Graphland gets a Reality Check)
Part VI – Adventures in GraphLand (Coprophagy)