Adventures in GraphLand V (Graphland gets a Reality Check)
If you are familiar with other graph systems and have you not read any of my previous blogs please do not read this one. If you do you will rapidly convince yourself that for some inexplicable reason KEL is far more complex than all the other systems. This is not actually true as the early blogs show KEL can play simple just like the other systems; however KEL is also designed to tackle the real world. Today we are going to abandon graphs completely, go back to square one, and ask ourselves the question: “what do we actually know.”
To ask this question I am going to go back to one of our previous datasets (the person dataset) and reproduce it the way it would usually turn up:
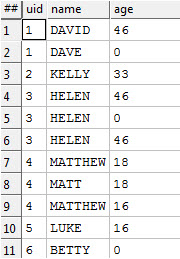
This is a lot like the dataset I showed you last time; still has unique IDs, still has names and still has ages. The difference is that in real world data we cannot assume that there is one, single, unique value for each property that an entity has. There are really four distinct cases you need to think about:
- There is really, one true value for a given property – and someone has handed it to us
- There is really, one true value for a given property – and we have been given multiple possible values for it
- There are really multiple possible values for a given property
- There are really multiple possible values for a given property and we have been given multiple possible values for each of them
#1 is the case we have been dealing with until this point. It is the one that most simple systems will focus upon but outside of sample data it very rarely occurs unless you have created a system to perform significant knowledge engineering before you hand it to the system you intend to use for knowledge engineering. As we have already seen; KEL can work in this mode but it is really designed for the harder problem.
#2 is the case of something like ‘Age’ – each person has a particular age at a given point in time – but not all the reports of that age will (necessarily) be modern and they will thus not all be the same.
#3 and thus #4 speaks to questions such as: “which states have you lived in” or “which music do you like” – a single person could easily have multiple values for that again recorded over a length of time and with different encoding schemes.
So how does all of this relate to our favorite graph language? Way back in the beginning I introduced the ENTITY statement that allowed you to declare which properties a particular entity had. What I did not discuss was the fact that in that same entity declaration you can specify the MODEL (or behaviors) of the individual properties and I did not dig too deeply into some of the ‘weird stuff’ in the results we were getting back. Now is the time to dig in. First a simple piece of KEL –
Person := ENTITY(FLAT(UID,Name,INTEGER age));
USE File_Person(FLAT,Person);
QUERY:Dump
And here is the output (on our new dataset)
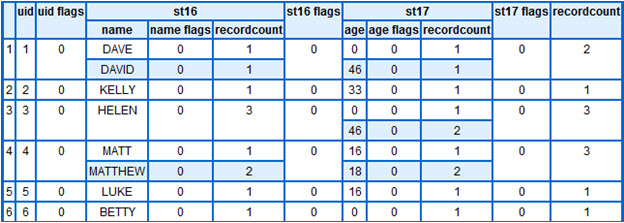
A few things to observe:
- There is still one row for each entity (UID) even though for some of them we have multiple input rows
- Each ‘property value’ (age and name in this case) has its own list of values (child dataset for those of you familiar with ECL).
- Each unique value for a given field is only stored once. Thus in our input dataset UID=3 has three instances of the name ‘HELEN’ but it only appears once; however it has a record count of 3
- Each ‘property value’ has a record count and also the complete entity has a record count (and the end of the row). Thus UID=4 has a record count of 1 for MATT, 2 for MATTHEW and a total count of 3
Whilst you probably think this all makes sense; here is a question for you – according to the data above how many 16 year olds are there in the data? How many 18 year olds?
To find out the KEL answer is remarkably easy:
Person := ENTITY(FLAT(UID,Name,INTEGER age));
USE File_Person(FLAT,Person);
QUERY:Dump
QUERY:Find(_age)
This shows a new KEL capability; inter entity aggregation. Previously when we have seen the {} syntax the UID has always been inside the {}. When the UID is there we are simply projecting and aggregating inside each entity. With the UID removed, we are still projecting and aggregating, but it is the entities themselves we are working with.
So; in the syntax above I am grouping by each value of age and counting the number of entities within each group. Here is the result from our test data:
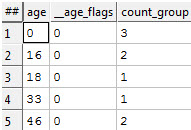
To the specific question; KEL counts UID=4 as being both 16 and 18. UID=1 and UID=3 are both counted as being 46 although both are also counted as being 0.
In KEL a multi-valued property has all of the values (once).
If you use the ‘Find’ query above and pass in 16 you will get back UID=4 and UID=5.
I suspect that by this point; some of you are shaking your head, somehow something is wrong. Somebody cannot have two different ages at the same time!
But suppose we were talking about phone number? Or ‘state lived in’? Suddenly having multiple values for that field would be considered perfectly reasonable.
Of course it comes down to the four groups I mentioned at the beginning; for each field the KEL programmer has the opportunity to express “how many values of this property should there really be?”. By default KEL assumes the data it is handed is correct; we have provided multiple values for age and therefore it has treated it as a multi-valued property!
Is this repairable within KEL? Yes – with logic statements. Here is a rework of the previous code in which the KEL programmer has begun to do the work of computing single values from multiple reports (case #2).
Person := ENTITY(FLAT(UID,Name,INTEGER in_age=age));
USE File_Person(FLAT,Person);
Person: => Age := in_age$Max;
QUERY:Dump
In the first line I have now moved the ingested data into a multi-valued field call in_age. KEL does not enforce this but I recommend using a consistent naming convention for ‘things you are bringing in that you know have the wrong model’.
Now, you should recognize the logic statement in the middle and you may even be able to read it. I want to read it with ‘new eyes’.
Firstly the scope is
Person:
This means all of the values for a given entity are in scope for this logic statement.
Age :=
Is now creating a new single value
in_age$Max
finds the maximum of all the ages within the entity (assuming ages only ever go up; which is true for everyone other than my mother).
The query statement has a new feature – some of the columns are inside extra {}. This means ‘put out a multi-valued property AS a multi-valued property’. The result is:
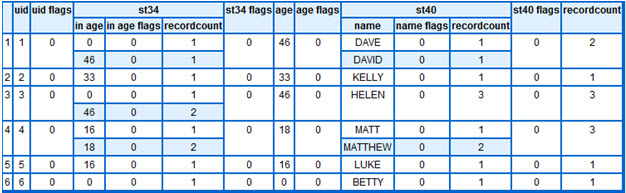
This looks a lot like the previous except we now have an Age column that is single valued per entity and behaves exactly as the nice case we handled in the first four blogs. In the ‘real world’ you would not use the in_age property once you had produced the clean version of it.
We have seen that KEL can handle the clean case like everyone else and it actually has a mechanism to handle the dirty case with full control for the user. Now for some magic: KEL has the ability to handle the dirty case as if it were the clean case: automatically.
Person := ENTITY(FLAT(UID,Name,INTEGER Age),MODEL(*));
USE File_Person(FLAT,Person);
QUERY:Dump
The new piece here is the MODEL statement. MODEL(*) is identical to MODEL(UID,NAME,Age), it means ‘every field is a single valued field.’ If we ingest the data using this model we get this:
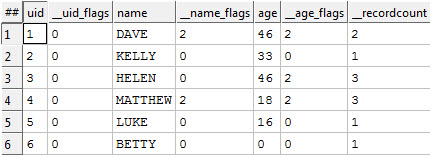
Every field value has been hammered down to one single value and everything can be treated ‘nicely’. The cost of this automated magic is that some data has been ‘scrunched’. If you look at the table above the _name_flags and _age_flags actually tell you when the scrunching has occurred. The ‘2’ values are those places where multiple values were hammered into one. KEL has also generated a ‘SanityCheck’ attribute that will give complete stats about how good (or bad) the automated scrunching was.
Whether or not you want automated scrunching will depend upon your own character and the nature of the data and in particular it can depend upon the nature of the individual fields. This can be captured in the KEL. As an example; suppose we consider it reasonable to have multiple names but only one age.
Person := ENTITY(FLAT(UID,Name,INTEGER Age),MODEL(UID,{Name},Age));
USE File_Person(FLAT,Person);
QUERY:Dump
Producing
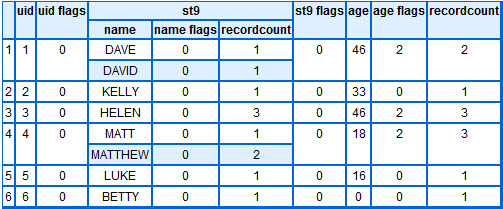
Using this mechanism you can force ‘nice world’ and then selectively improve the conversion as you see fit.
For some the foregoing might have been a little dull, for others it was probably a little scary. I am, however, unrepentant. On many systems GraphLand would be a fantasy world of amazing things largely detached from the reality of large scale Big Data analytics. GraphLand is not designed to be a fantasy world; it is designed to bring large scale graph analytics to reality.
Adventures in Graphland Series
Part I – Adventures in GraphLand
Part II – Adventures in GraphLand (The Wayward Chicken)
Part III – Adventures in GraphLand III (The Underground Network)
Part IV – Adventures in GraphLand IV (The Subgraph Matching Problem)
Part V – Adventures in GraphLand (Graphland gets a Reality Check)
Part VI – Adventures in GraphLand (Coprophagy)