Enhanced Interpretability in Question/Answering Systems
Deep learning has become one of the most popular methods in Artificial Intelligence (AI) to solve challenging tasks in many areas and has shown outstanding performance. However, the lack of interpretability of deep learning models has raised a wide discussion in the research community. In this research project, Jingqing Zhang aims to improve the interpretability of deep learning models in question answering systems.
Desiderata of Interpretability: Mind the Gap
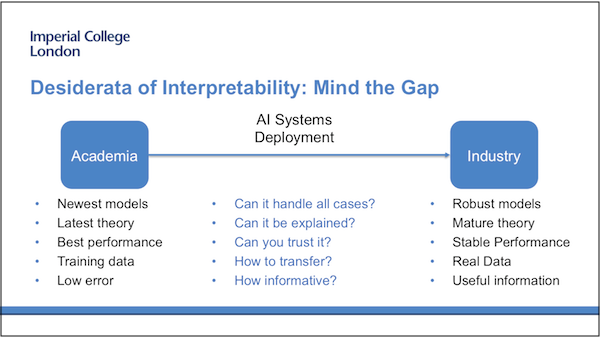
Researchers in AI always target the deployment of the latest and best models in real scenarios to solve real problems. But Jingqing feels there is a clear gap between academia and industry. For example, the real-time data in industry is more complicated and larger-scale than that in the lab and the models trained based on the limited dataset may not be able to handle all cases in the real world.
This research project aims to prove that this gap can be partially filled by improving the interpretability of deep learning models so they can be trusted in real scenarios more effectively. More specifically, the interpretability should include causality, informativeness and transparency. In other words, the deep learning model should be able to provide:
- Logical chains on which its prediction is based.
- Internal information for human judgement.
- Well proved and explained model design.
Question answering
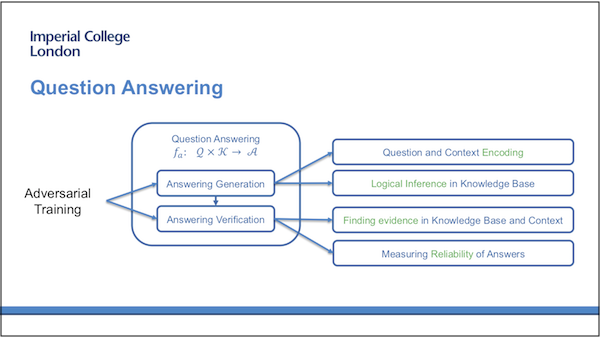
The question answering should be composed of two parts:
- Answering generation. Focusing on using generative models to generate a proper answer to a question given background knowledge, which can be in the form of either plain text or structured knowledge graph.
- Answering verification. In this part, the model is designed to find supportive information in the background knowledge and measure the reliability of the answers. The information should support the correct answers and also oppose the incorrect answers if applicable.
These two parts should work together in an adversarial manner so that the first part can generate reasonable answers and the second part can explain these answers.
Methodology
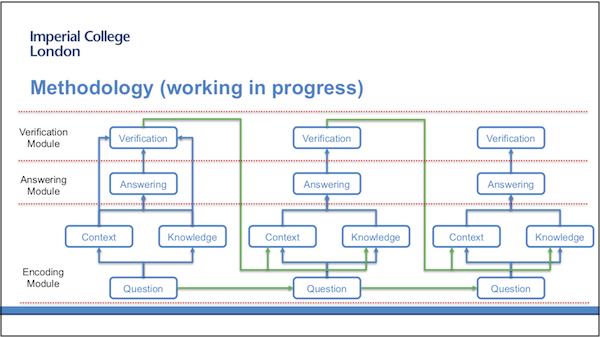
The design of the new model is still in the early stages. There are at least three modules that will be included in this research project:
- The encoding module encodes the question itself and the background knowledge.
- The answering module generates answers accordingly.
- The verification module finally verifies if the generated answer is reasonable and provides feedback to the next step of the recurrent process.
Data Collection

To establish a complete research cycle, Jingqing is also trying to collect a new dataset for question answering which will be used to test the new model. To achieve the goal of enhancing the interpretability of deep learning models, the dataset should be challenging enough. More specifically, the domain of the data naturally needs clear causality, requires good interpretability of AI models, and has a mature knowledge base. The powerful processing capability of HPCC Systems will play an essential role in the data collection and data cleaning processes.
Jingqing Zhang works at the Imperial College Data Science Institute in London. He has contributed to several research projects during his HPCC Systems sponsored Masters and PhD studies, having published a number of academic papers:
- Integrating Semantic Knowledge to Tackle Zero-shot Text Classification
- Dest-ResNet: a Deep Spatiotemporal Residual Network for Hotspot Traffic Speed Prediction
- Deep Sequence Learning with Auxiliary Information for Traffic Prediction
- Learning Text to Image Synthesis with Textual Data Augmentation
- The Deep Poincare Map: A Novel Approach for Left Ventricle Segmentation
Jingqing Zhang’s supervisor is Professor YiKe Guo, Professor of Computing Science and founding Director of the Data Science Institute at Imperial College, London.
In 2017, Professor Guo spoke in the October edition of Elsevier Connect about using machine learning and NLP to create meaningful summaries of articles via neural networks. Jingqing Zhang contributed to this research project while studying for his Masters degree.