Your End-to-End Data Lake Management Solution
HPCC Systems gives you the ability to quickly develop the data your application needs.
Simple. Fast. Accurate. Cost effective.
A platform purpose-built for high-speed data engineering.
HPCC Systems key advantage comes from its lightweight core architecture. Better performance, near real-time results and full-spectrum operational scale — without a massive development team, unnecessary add-ons or increased processing costs.
Discover Cloud Native
Learn how being cloud native can improve your current cloud deployments. Today’s HPCC Systems combines the usability of our bare metal platform with the automation of Kubernetes to make it easy to set up, manage and scale your big data and data lake environments.
Runs on Kubernetes
- Support for Azure Kubernetes Service
- Support for Amazon Elastic Kubernetes Service
New Storage Plane Architecture supports
- Object Stores: AWS Simple Storage Service (S3) and Azure Blob Storage
- Disk Stores: AWS Elastic Block Storage and Azure Files/Azure Disks
Elasticity
- Scaling a cluster without moving the data
- Auto wakeup to enable on demand processing by compute resources
Security
- End to end encryption
- Service Mesh Options (Linkerd and Istio)
- OAuth 2.0 support for Authentication, with built in support for Azure AD
- JWT
Functionality
Seven aspects of HPCC Systems make it easier than alternatives for processing and analyzing big data.
- Processing clusters use commodity hardware and high-speed networking.
- Clusters run on the Linux operating system.
- Supports SOAP, XML, HTTP/HTTPS, REST and JSON.
- Enterprise Services Platform (ESP) enables end-user access to Roxie queries via common web services protocols.
- Thor and Roxie are both fault-resilient, based on replication within the cluster.
- The systems store file part replicas on multiple nodes to protect against disk or node failures.
- Both are designed for resiliency and continued availability in event of hardware failures.
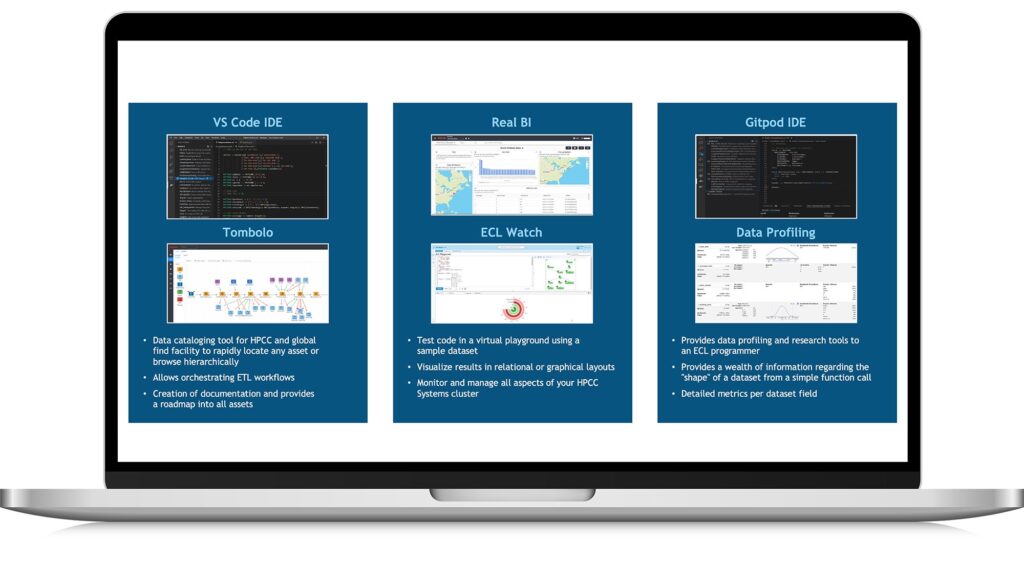
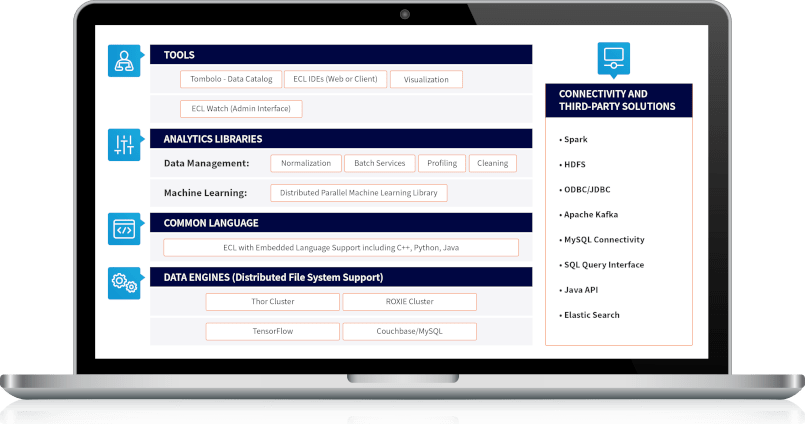
- Administrative tools for environment configuration, job monitoring, system performance management, distributed file system management and more.
- Extension modules for web log analytics, natural language parsing, machine learning, data encryption and more.
Declarative, modular, extensible Enterprise Control Language (ECL) is designed specifically for processing big data.
- Highly efficient — accomplish big data tasks with far less code.
- Flexible — can be used both for complex data processing on a Thor cluster and for query and report processing on a Roxie cluster.
- Graphical IDE for ECL simplifies development, testing and debugging.
- ECL compiler is cluster-aware and automatically optimizes code for parallel processing.
- ECL code compiles into optimized C++ and can be easily extended using C++ libraries.
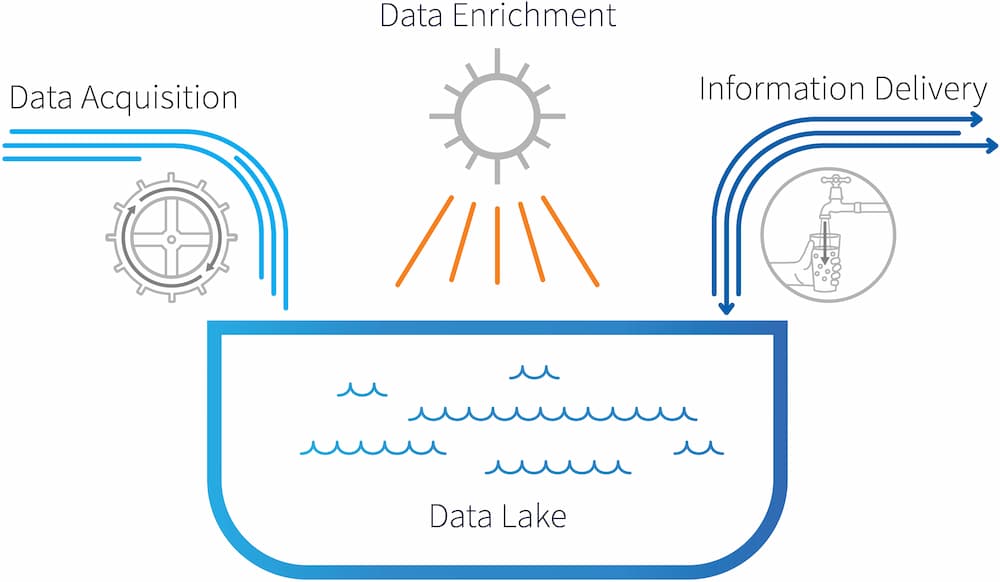
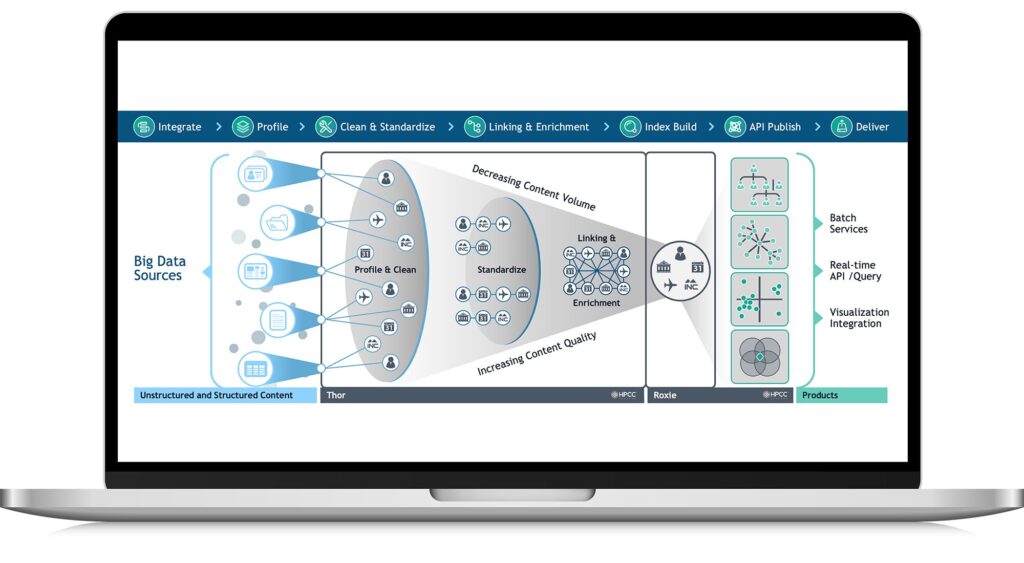
The two main systems, Thor and Roxie, work together to provide an end-to-end solution for big data processing and analytics. Data and indexes to support queries are pre-built on Thor and then deployed to Roxie.
Thor, the Data Refinery Engine, is the ingestion and enrichment engine.
- Thor uses a master-slave topology in which slaves provide localized data storage and processing power, while the master monitors and coordinates the activities of the slave nodes and communicates job status information.
- Middleware components provide name services and other services in support of the distributed job execution environment.
Roxie, the Information Delivery Engine, provides high-performance online processing and data warehouse capabilities.
- Each Roxie node runs a Server process and an Agent process. The Server process handles incoming query requests from users, allocates the processing of the queries to the appropriate Agents across the Roxie cluster, collates the results, and returns the payload to the client.
- Queries may include joins and other complex transformations, and payloads can contain structured or unstructured data.
- Thor DFS is record-oriented and optimized for big data ETL (extract-transform-load). A big data input file containing fixed or variable length records in standard or custom formats is partitioned across the cluster’s DFS, with each node getting approximately the same amount of record data and with no splitting of individual records.
- Roxie DFS is index-based and optimized for concurrent query processing. Based on a custom B+ tree structure, the system enables fast, efficient data retrieval.
- Horizontal scalability from one node to thousands of nodes.
- Thor can process up to billions of records per second.
- Roxie can support thousands of users with sub-second response time, depending on the application.
More about HPCC Systems
Versatile. Flexible. Refined.
An experienced HPCC Systems user explains the benefits and advantages of using HPCC Systems as your big data management solution.

Ready. Set. Go.
Are you ready to get started using HPCC Systems? Visit our Get Started page to explore the power of the HPCC Systems platform, test ECL code in a virtual playground, and learn how to get up and running with our Virtual Machine or create your own cloud cluster. Still want to learn more? Continue reading below.