Executing Multiple Workflow Items in Parallel

Nathan Halliday joined the HPCC Systems intern program to work on this project which will provide an enhanced usability experience for ECL developers. Implementing this feature will make query run times shorter and may also provide the additional benefit of allowing users to write queries that perform several related tasks concurrently.
The aim of Nathan’s project is to restructure the workflow engine to create a graph of tasks that can be used to track which tasks have been executed and which tasks should be executed next. Part of this work is to ensure that there are no multi-threading issues in the workflow engine. The plan is to support ROXIE and Thor by the end of Nathan’s internship.
In this blog, Nathan demonstrates the nature of the problem to be solved, the tasks involved and provides detailed information showing how his contribution to HPCC Systems provides a more flexible and contemporary approach to the workflow process.
******
All ECL queries pass through the workflow engine. Various ECL tokens (language features) cause the query to be broken up into workflow items. The items are linked through a dependency graph, which is created by the code generator during the compilation process. At run-time, the workflow engine is responsible for ensuring that these items are executed in the correct order.
Currently, the workflow items are always executed sequentially, but there are many situations where it could be beneficial to run unconnected items in parallel.

The darker blue lines in this image show the workflow items that could be run concurrently, shortening the total length of the query.
This blog explores the changes that need to be made to the workflow engine, in order to achieve this. As a result, ECL users can hope to see an improvement in the running time of each workunit.
How the Current Workflow Works
To determine which changes should be implemented, I studied the current workflow process.
What is the workflow?
When a query gets compiled, the actions described in ECL get translated into workflow items. These items contain the activity graphs that are processed during the query (e.g. sorting, deduping).
The purpose of breaking up a query into workflow items is to enable scheduling and to provide features like persists. If you are interested learning more about why this is useful, look at the workflow section of this guide to Understanding Workunits available on the HPCC Systems GitHub Repository. This resource also gives a detailed description of the workflow in relation to other workunit elements, such as activity graphs.
To ensure that the workflow items get performed in the correct order, items have dependencies, which should be executed first.
How does the current workflow engine work?
Here is an example of some of the xml generated when a query is compiled:

Each workflow item has a state, type, mode, unique workflow id (wfid) and dependencies.
The workflow engine walks the workflow items to find any items that are ready to be executed, i.e. any that have the state set as reqd (required). Typically, these items are any explicit actions in the query. If a required workflow item has dependencies on other child workflow items, then those children are executed first. Once all dependencies have executed successfully the parent workflow item is executed. The engine is recursive because child workflow items can also have their own dependencies.
Since there is only one thread performing workflow items, the engine is sequential.
It is worth mentioning that the definition of executing an item means to perform the generated code associated with its workflow id:
switch (wfid) {
case 2U: {
ctx->executeGraph("graph1",false,0,NULL);
ctx->setResultString(0,1U,5U,"Done!");
}
break;
}
Specialised workflow items
There are several varieties of workflow items, for example, sequential, wait, independent etc. The workflow engine uses modes and types to implement these which are encoded by the following enumeration:
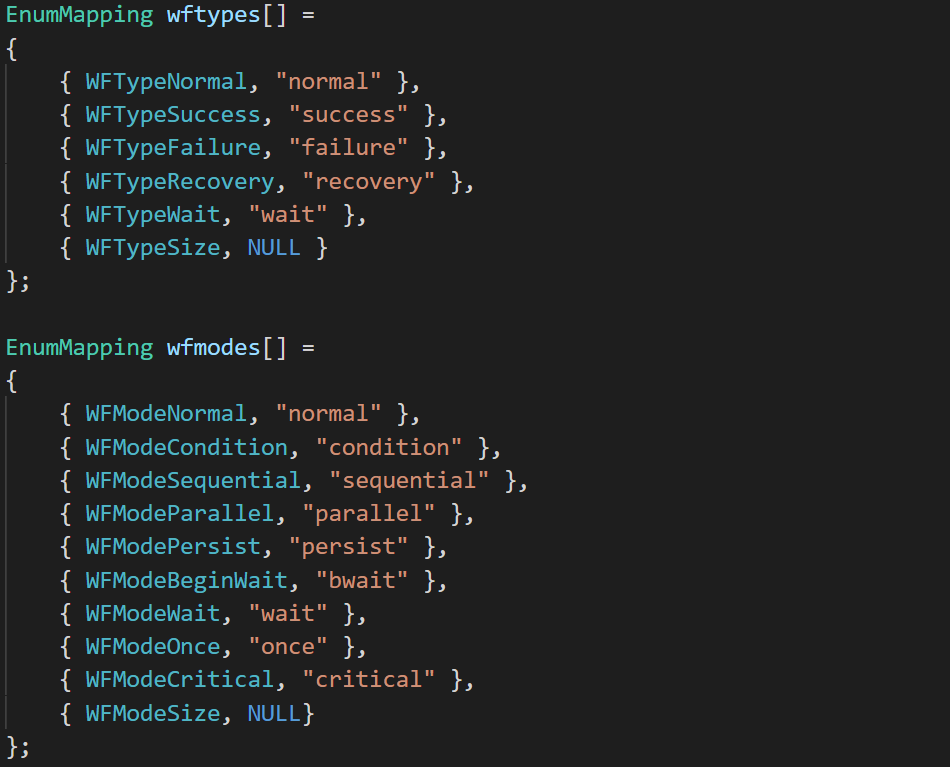
ECL programmers are given control over “Workflow Services” (ONCE, PERSIST, RECOVERY, SUCCESS…), to enable them to develop queries that are more efficient and more robust against exceptions. Likewise, programmers can use the ECL functions SEQUENTIAL, ORDERED and PARALLEL to specify whether items must be performed in a certain order.
Each mode affects the way workflow items should be executed. The implementation for each, in the parallel engine, is detailed below.
What Needs to Change?
Understanding how the current workflow process works highlights the potential for making the planned improvements. Here is an analysis of the changes required.
Successor relationships
Currently, the workflow engine automatically implements most of the running modes by virtue of only executing one item at once. In a parallel engine, this must be managed more actively.
The relationship shown below between Item 2 and its dependency, Item 1, is two-directional. It specifies that:
- To execute Item 2, you must first execute the dependency (Item 1)
- When Item 1 finishes, any successors (including item 2) may now be ready to execute. Item 2 is a dependent successor of Item 1, because the relationship corresponds to a dependency.
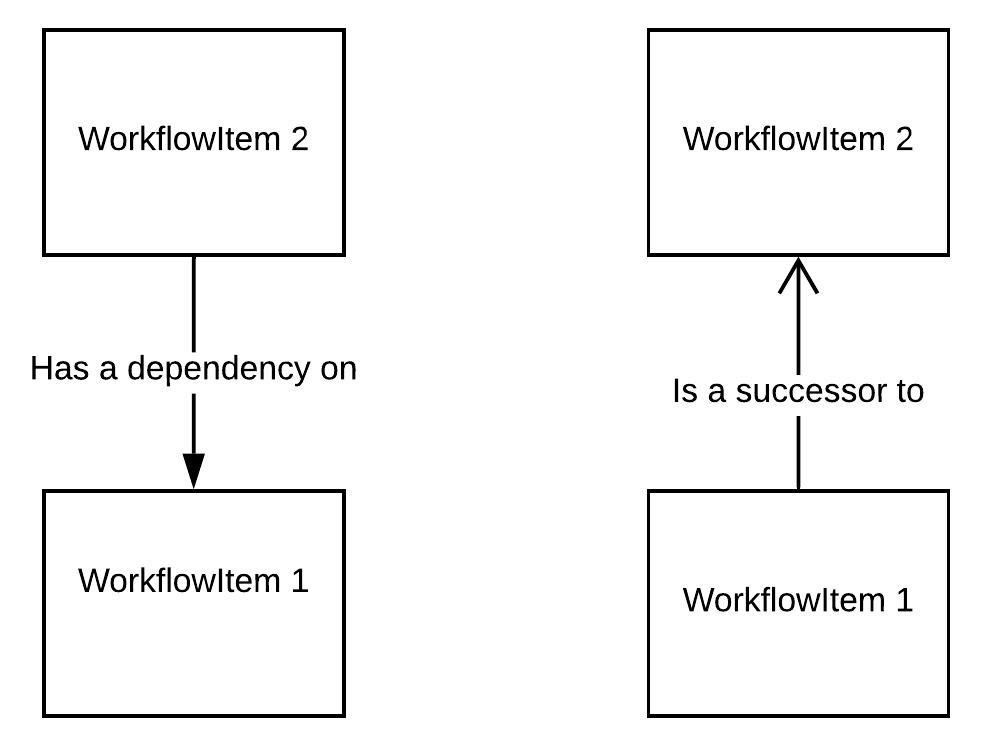
Relation 1 is used predominantly by the existing engine. We can use relation 2 as a basis for the parallel engine.
Running in parallel
For queries to run in parallel at the level of the workflow, tasks should be performed whenever they are ready. After an item executes, all items that were depending on it should be updated. The role of updating an item is to decrease the number of dependencies it has left. This ensures that as soon as an item has no remaining dependencies, it will be added to the item queue and processed.
An ECL query always generates at least one item with zero successors, called the parent item, which is the item to execute last. For the purposes of the following explanation, any item with a dependency is called a parent, and dependencies are called children”
In the sequential engine, parents have control over when their children execute. In the parallel engine, children execute first and then decide whether their parents are ready to execute. It is a challenge to determine whether the next item is ready or not, because child items don’t currently store any information about their parents.
To extract this information, I have created a function called markDependencies() which is recursive and traverses (depth-first) through each item’s dependencies. The root call for this function is on the parent item, which is consistent with the behaviour of the sequential engine.
The function markDependencies() achieves a number of useful tasks (by initialising item flags and creating new relationships between them):
- Each item, stores the wfid of its successors in a list.
- The dependency count for each item is set so that when its children are performed, the count is decremented until it reaches zero.
- Sequential/Ordered items create logical relationships between their children, so that they execute in the right order.
- Success/Failure/Recovery contingencies are initialized with an inactive state.
- Condition items are prepared, so that just one of the dependencies (trueresult or falseresult) will be executed.
- Persist items are prepared so that they only execute if the persist is out of date.
To execute the workflow items, I have implemented a thread pool. Parallel threads (up to the number of logical processors), will wait for items to be added to an item queue. Once new items are added to the queue, the corresponding number of threads are alerted by a semaphore, causing each to pop an item to process. At the completion of each item, the thread will update all of its successors.
The item queue is initialised with any items that are active and have no dependencies.
Examples of active and inactive items are shown below.
Key
During the development process, I have found it useful to sketch diagrams, to understand the dependency structure of the workflow. This key describes the important data about items that determines the order of the workflow. Runtime Workflow items are extra items that are created by the parallel engine in order to co-ordinate this information.
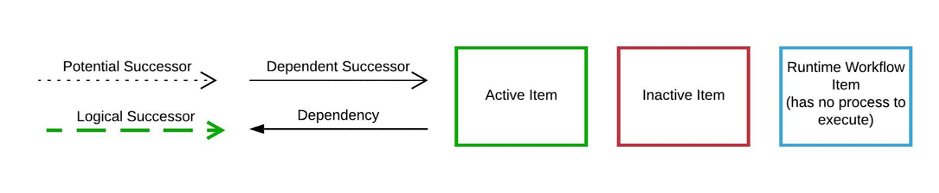
Logical successors, which haven’t been mentioned yet, are a second type of successor. Logical successors have no dependency on their predecessor but must execute afterwards.

Logical successors are used for ORDERED, SEQUENTIAL, IF, SUCCESS/FAILURE, as well as other items.
There are scenarios where an item will execute before its logical predecessor. This isn’t common, but may occur when several items share the same logical successor.
All diagrams in the following sections compare the sequential workflow (on the left) to the parallel workflow (on the right).
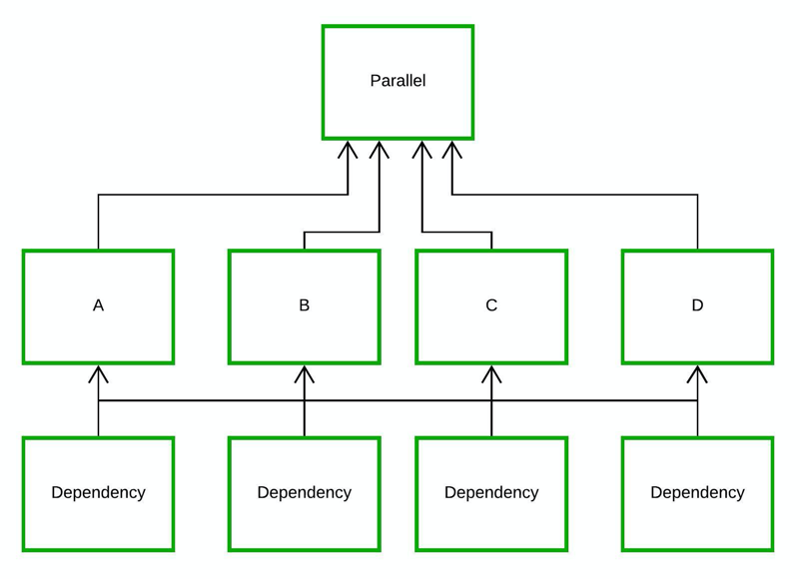
Parallel
This diagram shows how the old and new engines use the relationships between items in opposite directions. This is the change from using relation 1 to relation 2.
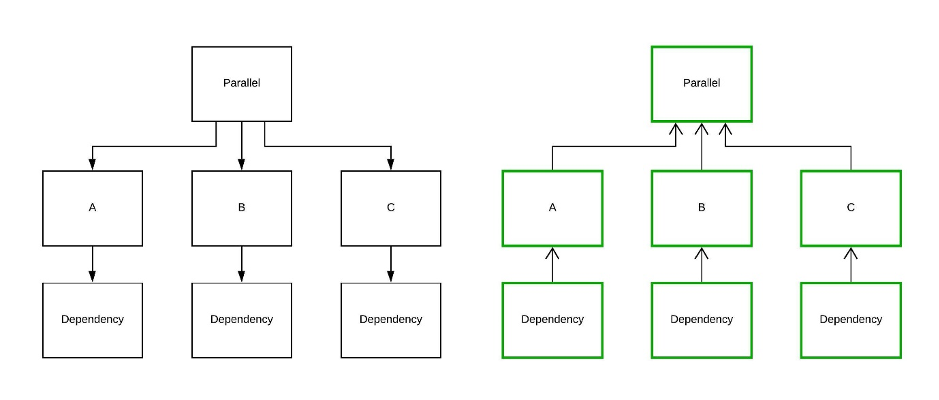
The lower three items can be added to the initial task queue because they have no dependencies. Parallel threads will execute them, and update the respective successors (A, B and C). Next, the workflow items A, B and C will be added to the task queue and popped by idle threads. The engine will finish once the parent item “Parallel” is executed, since there are no items left.
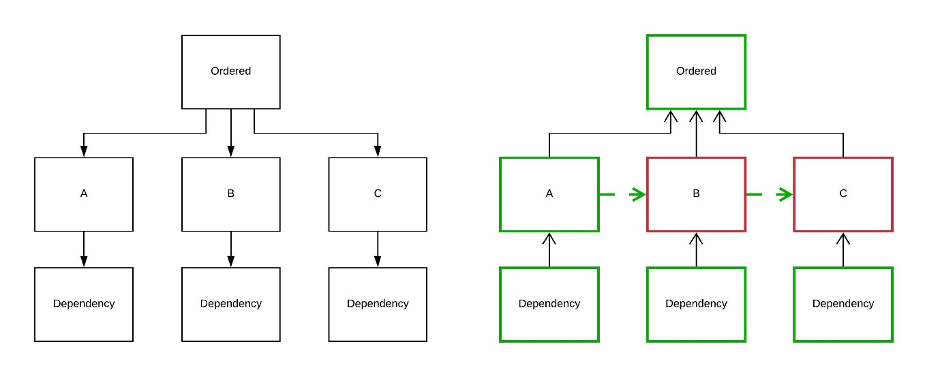
Ordered
This diagram shows the initial state of items when the ORDERED function is used. The rule is that dependencies A, B and C must be executed in that order. To implement this, item A “activates” item B upon completion, which then “activates” item C. This means B is a logical successor to A, and not a dependent successor.
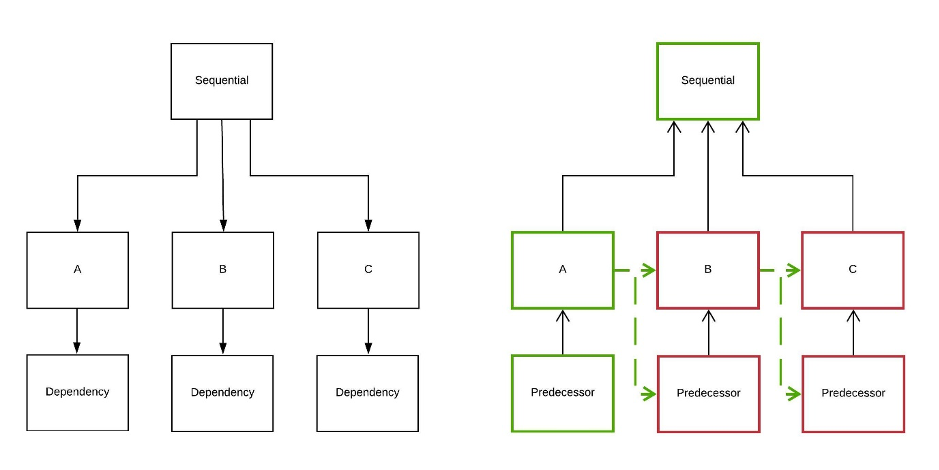
Sequential
The actions in a SEQUENTIAL actionlist have the most constrained ordering requirements. In addition to the constraints of ORDERED, any dependencies to an action can only be started once the previous action has finished. Item A has both B and its dependency as logical successors (shown by the green arrows).
Contingency
ECL programmers may already know that when SUCCESS and FAILURE are used, the contingent action executes only if the previous item fails or succeeds. In this example, the FAILURE clause begins in the “Inactive” state, and only executes if Item A fails.
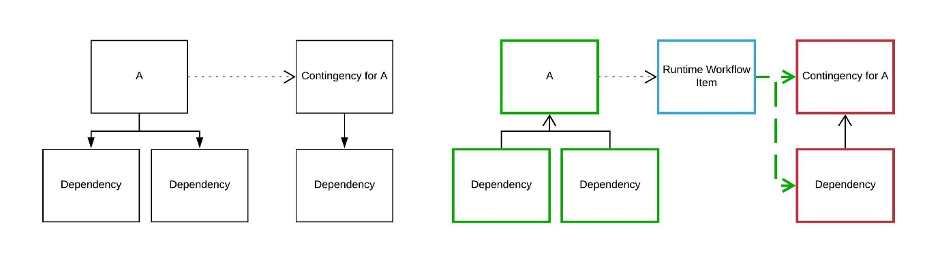
Note: The contingency clause is treated as part of item A. Until the clause finishes, no dependent successors of A are updated.
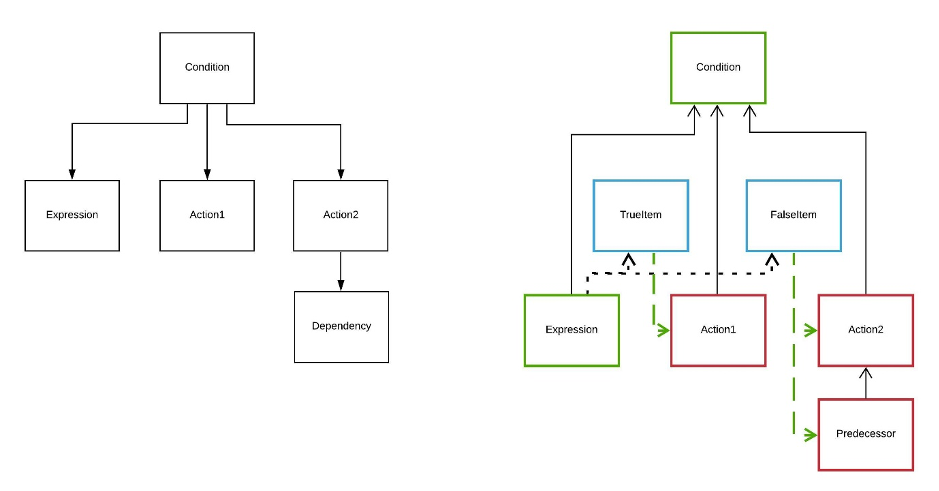
Condition
For Conditional execution in ECL, programmers use the IF function. This function takes three arguments:
- The condition expression
- The trueresult
- The falseresult.
The parallel workflow engine marks both the trueresult and the falseresult as inactive items (along with their dependencies). Once the condition expression is processed, if the result is true, the trueresult item and dependencies are activated. Otherwise, the falseresult items are activated. Activating the items allows them to be added to the item queue once they are ready.
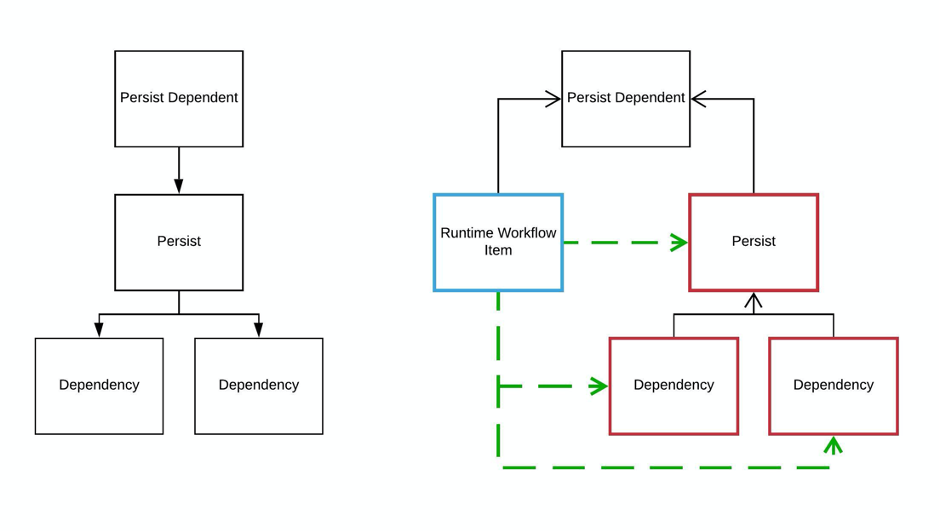
Persist
The diagram below shows the steps taken to implement the workflow service of persists. The assumption is that the persist is up to date. If it is not, then the branch will be activated and processed. This diagram is a simplification of the workflow structure that is generated by the code generator.
Statistic published with the query
For some large queries, the use of parallel threads becomes increasingly significant, since a greater number of items can be executed simultaneously.
This simple workflow can complete in one quarter of the sequential time:
Alongside the parallel engine, the query will publish a statistic upon completion of each workunit, detailing the maximum number of items that were executed concurrently.
Discourteous Examples (Diagrams I had left over!)
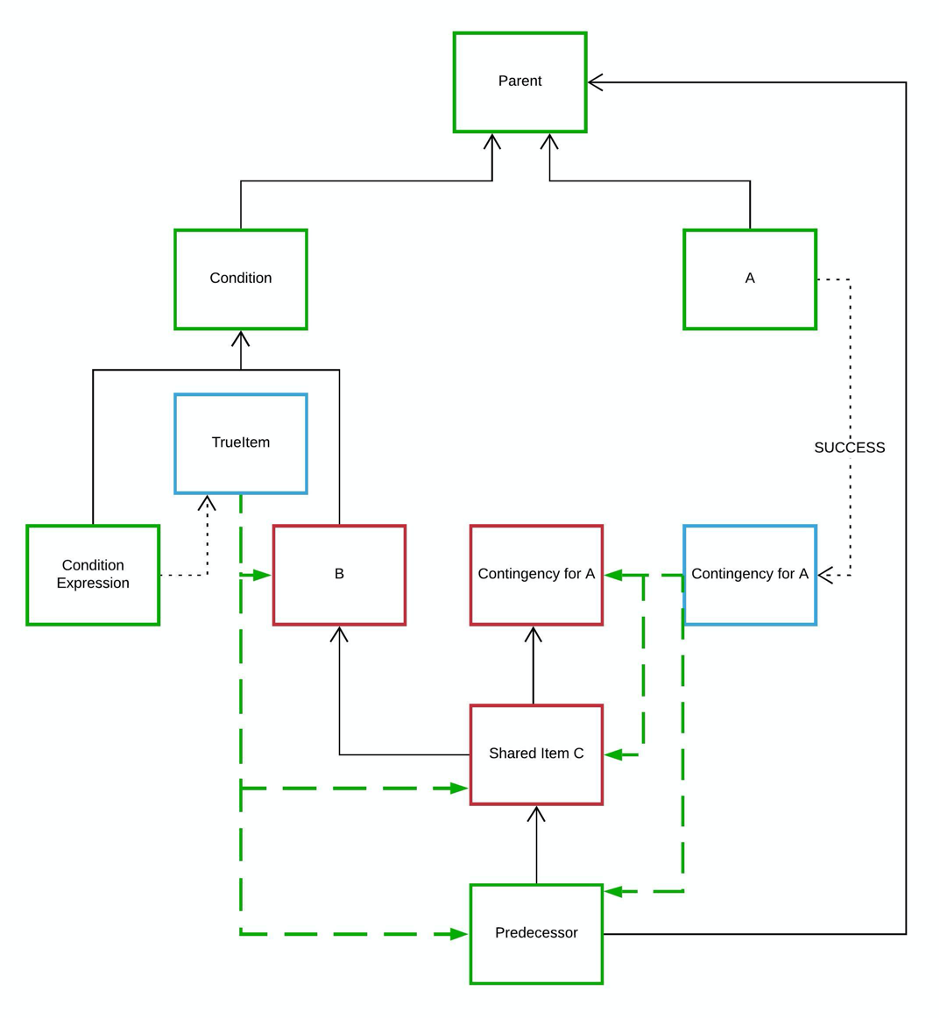
Next is a workflow with more complicated dependencies. The workflow was created to demonstrate the possibility that a dependency could be shared between several logical predecessors. Recognising this was significant for developing the logic that adds items to the queue.
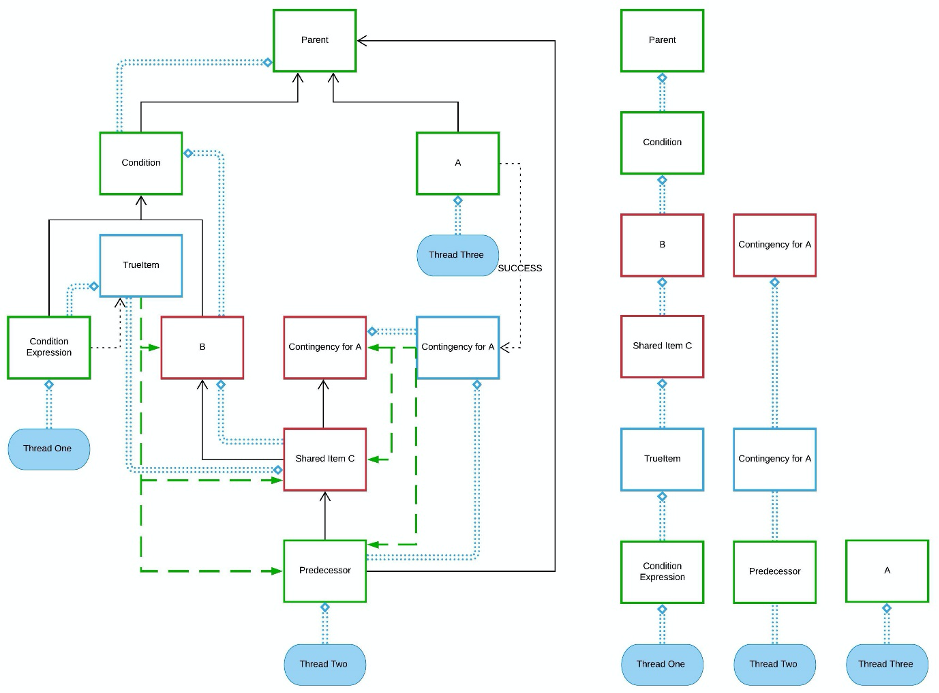
The image below shows one way three threads could execute this workflow in parallel. Each thread starts by popping an item from the initial item queue, but this is not always true.
The diagram could be improved by minimising the number of lines that cross and by being as consistent as possible with the spacing between items.
Several years ago, Gavin Halliday made an ECL query to test the code generator and I found this during my search for existing workflow tests. I went to the trouble of mapping it out into this convoluted diagram, but I should have known better!
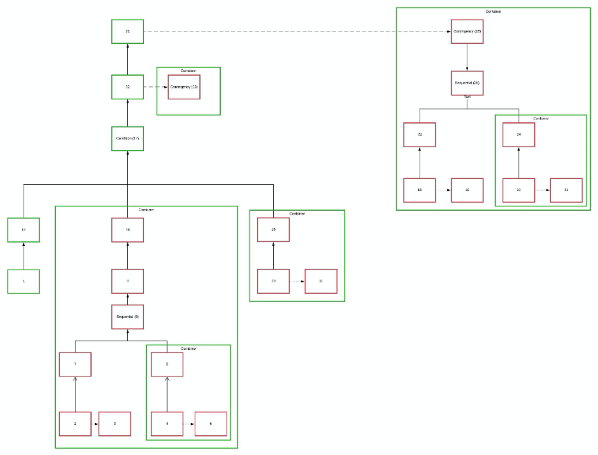
Complications
The workflow engine is made more intricate by having to:
- Co-ordinate when the parallel threads stop
- Catch any failed workflow items and perform the failure contingencies in the correct order.
- Protect shared resources such as the task queue from race conditions.
Some of the details of how I tackle these issues are described in my personal blog.
Reflections
I have found this project conceptually engaging, because it revolves around being very careful about managing the parallel threads. The project allows the extent of the parallelisation to be managed, by altering the maximum number of parallel threads.
As you have seen, there is strong potential for this project to have an impact on ECL programmers, through shorter query runtimes. It may also allow programmers to take greater freedoms, such as writing queries that perform several related tasks.
About the author
Nathan Halliday has completed his final year as a high school student and will start university later this year, having received an offer to study mathematics.
During his HPCC Systems internship, Nathan was mentored by Gavin Halliday (Lead Architect, LexisNexis Risk Solutions).