
The HPCC Systems open source community was recently featured at the 12th International Conference on Internet of Things: Systems, Management and Security (IOTSMS 2025), held in Lyon, France from December 2–5, 2025. This global event brought together professors, researchers, and students to explore cutting-edge innovations in IoT, distributed systems, and security.
One of the highlights was the presentation of the paper “A Modular Architecture for Inter-Fog Environments”, co-authored by Henrique Buzin and Patricia Della Méa Plentz (Federal University of Santa Catarina) in collaboration with Alysson Oliveira and Mauro Marques (LexisNexis® Risk Solutions). The lecture, delivered during a 60-minute session, attracted an audience of computing professionals eager to learn about new approaches to fog computing. This blog highlights the key aspects of the paper presented at the conference.
Why Fog Computing Matters
IoT systems generate massive volumes of data from sensors, cameras, and connected devices. Traditional cloud-centric models often struggle to process this data in real time due to network congestion, high latency, and limited bandwidth.
Fog computing bridges this gap by introducing an intermediate layer between edge devices and the cloud, enabling local processing, data filtering, and aggregation before transmission. This approach is essential for applications requiring immediate responses, such as:
- Smart traffic management – Real-time analysis of traffic flow and congestion.
- Public safety systems – Processing surveillance data locally for faster threat detection.
- Industrial IoT – Monitoring equipment health and preventing downtime through predictive analytics.
However, existing fog architectures often lack:
- Cross-domain interoperability – Seamless communication between different fog environments.
- Protocol flexibility – Support for multiple communication standards like HTTP and CoAP.
- Dynamic scalability – Ability to redistribute workloads across geographically distributed nodes.
The research presented at IOTSMS 2025 addresses these limitations through a modular design that enhances flexibility and performance.
The Proposed Modular Architecture
The architecture organizes fog nodes into three functional layers:
- Protocol Layer – Abstracts communication protocols, enabling devices using HTTP or CoAP to interact seamlessly.
- Processing Layer – Handles internal operations, temporary data storage, and service discovery.
- Service Layer – Executes configurable services tailored to application needs, such as energy consumption analysis or water usage monitoring.
This layered approach provides:
- Scalability – Nodes can be added dynamically to handle increased workloads.
- Interoperability – Protocol abstraction simplifies integration of heterogeneous devices.
- Resilience – Inter-fog communication enables load redistribution during peak demand.
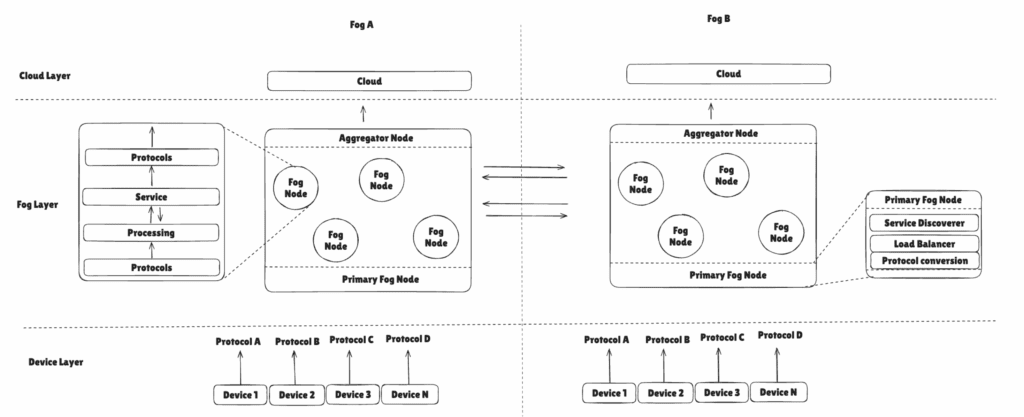
Figure 1: The proposed modular fog computing architecture.
.
Smart City Use Case and Testing
To validate the architecture, the team implemented a smart city scenario using Docker containers to simulate energy and water meters. These edge devices transmitted data via HTTP and CoAP to fog nodes, which processed and consolidated the information before forwarding it to the cloud.
A key innovation introduced by the researchers was the development of a custom interface designed to simplify the creation and management of fog environments. This dashboard allowed users to:
- Configure fog nodes and edge devices.
- Monitor communication ports and data flow.
- Visualize the distribution of workloads across different fog domains.
This interface played a crucial role in managing the complexity of the distributed environment, enabling real-time adjustments and ensuring smooth operation during testing.
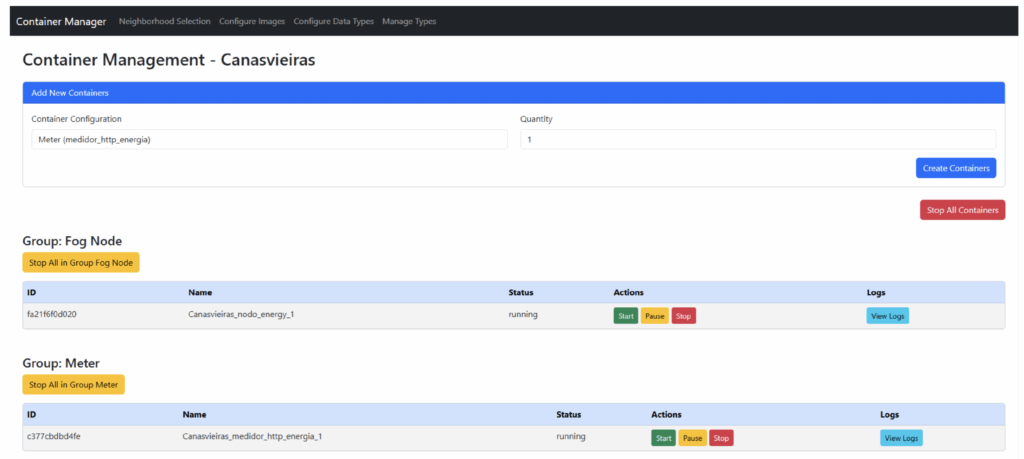
Figure 2: Interface developed for creating and managing fog networks within neighborhoods.
The experimental setup included:
- 70 edge devices (21 HTTP energy meters, 17 CoAP energy meters, 15 HTTP water meters, and 17 CoAP water meters).
- Two fog environments (Fog A and Fog B) with dynamic load balancing.
- An aggregator node for data consolidation.
- HPCC Systems as the cloud layer for large-scale processing.
The HPCC Systems platform played a critical role in the cloud layer, serving as the high-performance computing backbone for this architecture. After fog nodes aggregated and pre-processed data, the consolidated files were transmitted to the HPCC Systems cluster for:
- Batch processing using Thor – Efficiently handling large volumes of daily data collected from multiple fog nodes.
- Real-time querying with Roxie – Supporting fast insights and enabling dashboards for monitoring consumption patterns.
- Data harmonization and transformation – The ECL language was used to map and normalize data fields from heterogeneous sources, ensuring consistency for analytics.
This integration demonstrated how HPCC Systems can complement fog computing by providing scalable, fault-tolerant, and high-speed processing capabilities, essential for smart city applications.
Performance Results
The architecture was evaluated for latency, resource usage, and scalability. Key findings include:
- Average latency from meter to HPCC Systems: ~2.5 seconds.
- Memory footprint per fog node: ~276 MiB.
- Aggregator node reduced network overhead by consolidating data into CSV files for HPCC ingestion.
Once ingested, HPCC Systems enabled complex analytics, such as trend detection and anomaly identification, which would be computationally expensive at the fog layer. This highlights HPCC Systems role in bridging edge intelligence with centralized big data analytics.

Figure 3: Minimum, maximum, and average one-way latencies.
Looking Ahead
The proposed architecture aligns with the OpenFog Reference Architecture principles and sets the stage for future enhancements, including:
- Security integration – Implementing encryption and authentication mechanisms.
- Fault tolerance – Ensuring system continuity during node failures.
- Machine learning capabilities – Leveraging HPCC Systems for predictive analytics and anomaly detection.
By combining fog computing for real-time responsiveness with HPCC Systems for large-scale analytics, this research demonstrates a powerful synergy that can drive next-generation IoT ecosystems and smart city infrastructures.
Please join us in congratulating the authors on this incredible achievement, and stay tuned for a link to the published paper once the conference proceedings are available. In the meantime, if you would like more information about this research, you are welcome to reach out to the corresponding author below.
Meet the Authors
Henrique Buzin (henrique.buzin@hotmail.com) – Graduate student in Computer Science at the Federal University of Santa Catarina, focusing on distributed systems and fog computing.
Patricia Della Méa Plentz – Professor and researcher at the Federal University of Santa Catarina, working on IoT, fog computing, and smart city technologies.
Alysson Oliveira – Software Engineer at LexisNexis Risk Solutions, with expertise in cloud and edge computing architectures.
Mauro Marques – Senior Technical Support Engineer at LexisNexis Risk Solutions, specializing in high-performance computing and data-intensive applications.