Adventures in GraphLand III (The Underground Network)
If you have digested my blog on The Wayward Chicken then as you gaze out upon GraphLand you should no longer be thinking of a land of clearings connect via a maze of pathways. Rather we have a modern industrial landscape; every node is a factory with a rail link to the neighboring factories. Raw goods (data) regularly travel towards each node to be processed into a more refined good which may in turn become the raw material for a neighboring factory. Conceptually, (though not factually) the process happens for every node synchronously until everything is complete. Only then are orders serviced and that process usually just amounts to assembling the parts already made (quite possibly all within a single factory).
Our scene readily maps onto pure graph theory which would like us to believe the world consists of nodes and edges (balls and sticks) and that everything can be mapped onto this model. In truth it can; but it requires a shift of mind that I hope will repulse you as much as it does me.
In our opening data model we had people and relationships between people and all our data fitted nicely into the model. How do I add the concept of ‘Vehicles’ to GraphLand? To stick with my stick and ball model I now have to give every node an extra property the ‘Type’ which would be ‘Person’ or ‘Vehicle’. I then have to add vehicle properties to my node (which will be null for people). I now have to adjust all of my processing logic to ensure I am filtering (at process time) down the types of entity I am interested in.
In fairness there are benefits to this ‘model’; it is a data model which by definition can handle anything. The cost is that the logic around how to process the entity types has to be pushed down into the queries and worse all of the resolution and checking happens at run time. To return to our analogy; every factory could process different things a different way and at different times and we need to enter each factory to find out what it does. This could actually be a motivator behind the Wayward Chicken programming method.
The KEL model, and thus GraphLand, behaves very differently. In our first blog I introduced Entities and Associations and then used the term interchangeably with nodes and edges. This is not strictly correct. Within KEL you can define multiple entity types and multiple types of associations inter or intra entity. You can think of this as having multiple layers of factories burrowing underground with various pipes and tubes carrying goods from layer to layer. Within a single layer everything is homogenous and synchronous and the transport between layers is also homogenous and synchronous but the result is that complex heterogeneous queries can be achieved.
Enough theory – let’s get to the data. 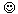
First with apologies to all car buffs out there; here is the Bayliss interpretation of all interesting facts about our vehicles.
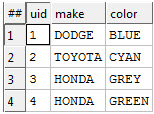
Secondly, relationships file between people and vehicles. Note this file contains information regarding two different types of relationship between Person and Vehicle, Owns and Drives. The ‘per’ column is the entity ID for the person, the ‘veh’ column is the entity ID for the Vehicle.
These can be declared and used within GraphLand as easily as before:

It should be noted that if I personally were doing this I would have split my relationship file into two and imported one as an association ‘owns’ and one as ‘drives’; I would then have had rather nicer association names, compile time checking and nicer queries. However, for the sake of showing off some KEL features, I am bringing in the associations with the types intact and we will validate them at query time.
We may remember from our previous blog that associations for a given entity are now accessible as if they were child records of each entity. Thus the PerVeh association now exists for people and for vehicles.
This simple query provides a list of people with the vehicles they drive or own:
QUERY:Dump1 <= Person{UID,Name, PerVeh.Veh{UID,Make,Colour}};
Produces
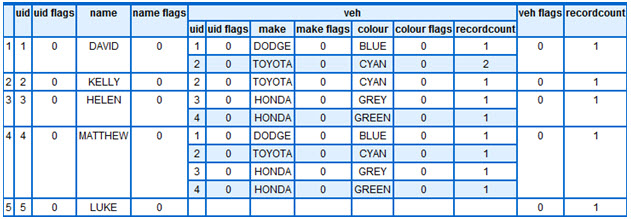
Of course we do not really want to use KEL simply to dump out data we already had. What we really want is to compute new information. So here is a question for you: “How many vehicles is each person in the list the sole owner of?”
I would imagine that most of you started:
COUNT(PerVeh.Veh(< Ouch, this is going to hurt> ))
You actually can make it work that way; but it is much better if you decompose the problem. The first question one should ask is: “Which vehicles have only one owner?” This becomes very simple:
Vehicle: => nOwners := COUNT(PerVeh(Type='OWNS'));
Within our underground network of vehicles it is very easy to count the number of people relationships. The new thing is that the associations can have values (such as type) and they can be part of filters too.
Then within our surface entity (people) it becomes fairly easy to compute the number of vehicles a person is the sole owner of:
Person: => nWholeOwned := COUNT(PerVeh.Veh(Person.PerVeh.Type='OWNS',nOwners=1)):
The COUNT and the nOwners=1 should be familiar. The slight ugliness is the checking that we are dealing with ownership rather than simply driving; you may remember my saying I didn’t like late-typing!
We have to check Type=’OWNS’; the problem is that the filter is in the scope of the vehicle which doesn’t have a Type attribute. KEL allows you to pull data from anywhere on the path to a data element; but you have to state the place in the path you are pulling the data from. Hence: Person.PerVeh.Type=’OWNS’.
As an aside: KEL is a language under development, we do have an issue open to allow a rather prettier form:
Person: => nWholeOwned := COUNT(PerVeh(Type='OWNS').Veh(nOwners=1));
Which works if a filter is resolvable before the full path is known.
Putting this all together we have:
Person := ENTITY(FLAT(UID,Name,INTEGER Age));
USE File_Person(FLAT,Person);
Vehicle := ENTITY(FLAT(UID,Make,Colour=Color));
PerVeh := ASSOCIATION(FLAT(STRING Type,Person Per,Vehicle Veh));
USE File_Veh(FLAT,Vehicle);
USE File_PerVeh(FLAT,PerVeh);
Vehicle: => nOwners := COUNT(PerVeh(Type='OWNS'));
Person: => nWholeOwned := COUNT(PerVeh.Veh(Person.PerVeh.Type='OWNS',nOwners=1));
QUERY:Dump <= Vehicle{Make,Colour, nOwners, PerVeh.Per{Vehicle.PerVeh.Type,UID,Name}}; QUERY:Dump1 <= Person{UID,Name, nWholeOwned, PerVeh.Veh{UID,Make,Colour}};
Dump (a dump of vehicles with people as the children) yields:

Notice the use of the path walking syntax to annotate the child person records with the information from the link.
Dump1 is then rather simpler:

There is much more fun we can have with this data as we inch into some queries that are necessarily second order. First though I want to tackle the sub-graph matching problem; or rather point out that we have actually tackled it already.
Adventures in Graphland Series
Part I - Adventures in GraphLand
Part II - Adventures in GraphLand (The Wayward Chicken)
Part III - Adventures in GraphLand III (The Underground Network)
Part IV - Adventures in GraphLand IV (The Subgraph Matching Problem)
Part V - Adventures in GraphLand (Graphland gets a Reality Check)
Part VI - Adventures in GraphLand (Coprophagy)