ChatGPT & the False Alarms of Singularity
I have been working in the area of practical Natural Language Processing (NLP) for almost 40 years and have seen the AI singularity being predicted at regular intervals over the past decades. Each generation seems to find something that will finally wipe out humankind. When I first learned of ChatGPT and studied the technology behind it, I knew that this was no different. And even though I fought with colleagues over this when it first came out, I was right, and they are starting to come around.
Eliza : The First ChatGPT
For those not familiar with the history of natural language processing, there was a program back in 1964 from MIT that was the ChatGPT of its day. The program was called “ELIZA” and it was patterned after a Rogerian Psychotherapist. Subjects would sit a computer screen or teletype machine and converse with a computer program. When it first came out, the public was abuzz with thoughts of intelligent computers taking over the world. The singularity had arrived.
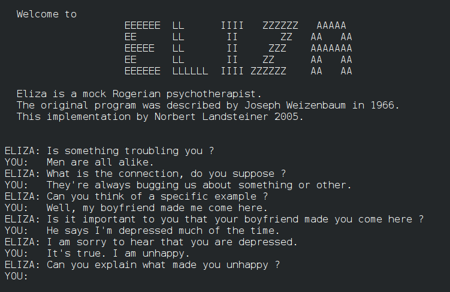
Eliza in 1966 was as impressive then as ChatGPT is today. It elicited scary thoughts that computers someday would be more intelligent than humans and make humans obsolete. Even though the Eliza’s publicity was not as extensive in the 1960s as ChatGPT is today, the public fear of computers taking over the world was just as real.
Eventually it was realized that Eliza was a computer version of a parlor trick and the worries of singularity died down. As the public became more familiar with computers, eventually working with them on a daily basis, the level of “impressive” changed as well.
Machine Learning and Neural Networks
The next coming of the singularity was when Machine Learning (ML) and Neural Networks (NN) became more mainstream. Computers could learn on their own without programmers specifically coding their tasks and soon computers would take over the world. Instead of writing programs, ML and NN could be given millions of texts, images, or sounds and could learn and classify data on its own.
In the 1990s, the foundation of machine learning and neural networks were laid down. Next some successes in NLP would appear in the 2000s and 2010s in the areas of machine translation and speech recognition that eventually would become mainstream. Statistical methods took over NLP and linguistic and world knowledge we, for the most part abandoned and left in the dustbin of history.
ChatGPT
In the early 2020s, ChatGPT was released and impressed the public in the same way that Eliza impressed the public back some 60 years prior. ChatGPT reached a million users in record time and the public was abuzz once again with computers and the singularity.
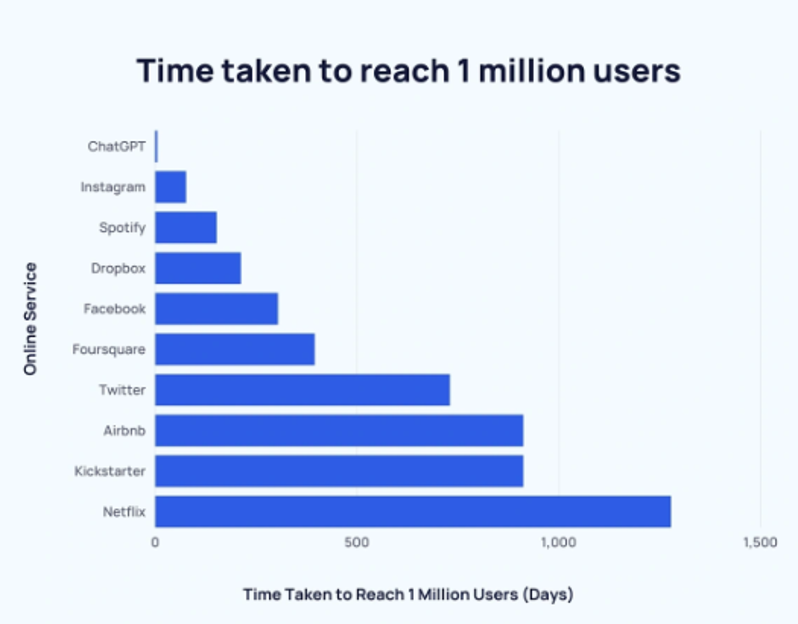
The entire world was conversing with ChatGPT and many thought it to be sentient. It looked like computers finally took that step to being 100% conversant with us humans and it would replace journalists, writers, artists, and even musicians. ChatGPT passed college entrance exams, wrote music, played chess and even wrote computer code all on its own. The ChatGPT users base got to a million users in days instead of months or years and the frenzy caught fire around the world.
With all this, the headlines of doom started to appear:
- Will ChatGPT Replace Your Job?
- 300 million jobs could be affected by latest wave of AI, says Goldman Sachs
- Fears of the Singularity
Some prominent people even called for a moratorium on AI for six months before we somehow crossed the line. This is a direct result of the fear that ChatGPT instilled into the public because if its ability to generate such complex and grammatical responses to typed in statements, it appeared that computer intelligence had arrived.
Once again the end of humankind and the singularity had reared it ugly head. But as I told some of my colleagues at the time: the faster they rise, the harder they fall.
Large Language Models
In reality, very few people “understand” Large Language Models (LLM). Having watched many videos on ChatGPT, I found these two to be some of the clearest and easiest to understand. The videos are 7 and 8 minutes long and should be watched before reading the rest of this article:
After playing with ChatGPT, it is hard for people to believe that it is no different from the “guess the next word” on one’s smartphone. But Large Language (LLM) Models like ChatGPT are literally making a statistic prediction of each word that follows after receiving the text from human input.
Sophisticated techniques used in LLMs like prediction network and attention networks were necessary in order to build statistical models what would respond in a grammatical and believable fashion.
The Librarian Analogy
You can imagine that a Large Language Model is like the ultimate librarian who has read all the text in the world but cannot understand it. If you ask a question, or make a request, the librarian uses their vast knowledge of the texts that exists to give you reply by finding the most likely words to say to you. The librarian does not have to understand any word. They just spit out their response by what is most statistically likely, given all the text in the world. You know that the librarian does not understand the meaning of the text, they can only do their best by finding text that is the mostly likely to follow your query or demand.
Each time you ask the question, the librarian will travel a different path to give the response. This is called “temperature”. Temperature is used to help randomize the statistical path for the response. The more random, the more “hallucinatory” the librarian becomes. Given that the librarian does not use morals or a knowledge base of world facts, the answers can produce very confident lies.
When you put the temperature to “zero” you get a google-like response which simply repeats what other humans have written somewhere on the internet. If you let it be more “creative”, ChatGPT will begin to write text that communicates information that is factually wrong (like each time I asked it to write my bio and each time it said I was born in a different country other than the United States).
Momentum of Machine Learning
Those who have been in machine learning for decades have convinced themselves that eventually, some technique or algorithm will make computers become sentient. This in itself keeps AI from advancing in that we keep going down one road thinking it will solve all the problems when in reality, there are limitations to the technology.
When professors and professionals alike dedicate so much of their lives to something, it is hard for them to see the limitations of the technology they are working with. They live in a bubble of that technology, making incremental improvements and talking of how this technology is “the one” to bring about computer intelligence.
For almost two decades, machine learning, neural networks, and ChatGPT have been claiming that eventually, some “breakthrough” will happen, and computers will become intelligent. This is felt so-much-so by the academic community, that a moratorium on AI in general was called for before it went “too far”. But those more seasoned linguists such as Noam Chomsky were quick to point out that ChatGPT was just a more sophisticated version of older chat bots and there was nothing to fear because the systems are statistical and not knowledge-based.
Academia and Industry Differ
Academia still has people claiming that breakthroughs for LLM are just around the corner and so is the singularity. The industry has quickly seen the truth and immediately backed off the technology to allow the focus to be on trying to find truly useful and lucrative projects. Some like the Khan Academy is using ChatGPT technology as tutors. I tried it and it works quite well. Industry is going in this direction and I’m sure there will be a place for such technologies.
Every Generation Promises Singularity
I remember back in the 1980s when I was in college, I came up with an idea of creating an NLP system that could understand the text you gave it. It was a simple left-to-right parser that would understand each word. I was in my 20s, and I was sure I could solve NLP. After publishing a paper on a Data-Independent Interface for Databases, I came up with the “READER” parser. It was just an idea but at that time, I was certain I solved NLP. I obviously did not.
Every generation of computer scientists enter AI as if they will conquer the world and create the singularity or the ultimate AI system. It is part of the arrogance and ignorance of the younger generation. Sometimes this attitude indeed produces something revolutionary, but the idea of true computer intelligence is a very hard problem and despite decades of generations in the modern computer age having a crack at it, it is still far off.
Having talked recently to young students in college, there is still an attitude that Large Language Models are going to “crack” in the computer intelligence barrier. Just as the younger generation claims new technologies will be the answer, it often takes them longer to come off their pedestals and fall back to reality.
Hype Train Hurts Progress
Another big problem is the over-hyping of AI in almost every advertisement for big data. They always end with the claim that AI and machine learning will solve big problems. They aren’t doing anything intrinsically wrong. It is more that they are using AI to impress the general public and management by insinuating that AI will solve all of the very important problems. Then in turn, some companies see and hear this hype and task their engineers to use these latest techniques in their systems without having any idea of the limitations of the technology.
I have discussed this problem with university professors and industry colleagues, and they all agree that the hype is much bigger than the reality. In fact, some managers around the world have instructed their software engineers to use these AI techniques such as machine learning, neural networks, and now Large Language Models but they are almost always misunderstood and wrongly applied to problems they cannot, in the end solve.
Temperature Change Reveals ChatGPT’s True Self
Another problem is the industry’s inability to recognize that statistics are not the way computer intelligence will find its answers, even though they’ve been pushing AI as being ubiquitous and more powerful than it really is. You’ve seen commercials for data companies who have been pushing “AI” as a key selling point to their services. Yet, when one pulls back the curtain on the realities, it turns out not so much to be AI, but more a statistical analysis of a client’s data.
If you set the temperature to zero, you get google search. If you set the temperature high, you get hallucinations. Microsoft invested 10 billion dollars to find this fact out very quickly. It turned out to be a shortcut to what Google had been doing without ChatGPT which was to point to existing information on the internet about a subject and summarizing it.
ChatGPT literally is no different than autocomplete that is on a smart phone. The response or story or summarization is calculated word for word as to what word comes next. Yes, the innards of Large Language Models have clever ways of making them model the language in a way that allows for them to produce perfectly grammatical sentences, but in the end, it is still just an autocomplete on steroids. And like with autocomplete, we quickly see that it is not “understanding” what you have said but is simply reacting in the most “probable” way it can to what you have typed.
True Intelligence in Computers is Human-Like
In the last two years, I have talked to a number of veterans in the machine learning world who are now looking outside of Machine Learning, Neural Networks, and even LLM for answers to the limitation of such technologies.
Having talked about limitations of natural language processing and the impossibility of computers learning the true meaning of words using only statistics, people are now looking in a different direction. ChatGPT which has read almost the entirety of English text ever written, can still not show that it understands the meaning of any word or phrase. It can certainly repeat text that can explain the meaning of something, but deep inside it’s neural networks, it has not created a node for “grandmother” and all the characteristics of grandmother which it accesses in the same way people understand “grandmother”. It was always a question if that truly existed but experiments with monkey’s have shown in fact that it may be very well true that we have one neuron in our brain for “grandmother” (See: https://www.livescience.com/grandmother-neurons-discovery.html).
In my talk at Clemson University in August of 2022, I came up with a new test for intelligent machines. Instead of being able to mimic human conversation exactly as a human, I suggested that intelligent programs should be required to show that they understand text in the same way humans understand text. This is a big department from the Turing Test which in effect was a mimicry test.
Furthermore, I suggested that a computer language such as NLP++ allows for creating the first intelligent programs given it can encode the way in which humans understand and mimic the way in which human beings process and understand text. I coined the term “digital human reader”.
I also suggested that computers, like humans, have to memorize or learn the meaning of arbitrary symbols that humans use in language in order for them to do any task in an equivocal manner as humans. I call this the fifth linguistic revolution: the transfer of linguistic and human knowledge to computers. It is then and only then when computers can start to understand language and use human language in a way that we truly deem “intelligent”.

Intelligence and Human Language Run Hand in Hand
It is important to understand that human language and human knowledge have walked hand-in-hand for thousands of years for us to get to the point we are today in human intelligence. We spend almost one third of our life learning language and the knowledge of the world using our language in order to reach a certain level of “intelligence”. It is only logical to assume that for computer to do the same, they too will have to be taught linguistic and human knowledge exactly as humans. NLP++ is one language that is allowing us to do exactly that.
Computers need to know the meaning of the arbitrary words and symbols and world knowledge in order to show that they can make decisions about language in the same way we humans can. For example, a program written in NLP++ can show a step-by-step answer as to why it assigned a particular code in a medical text and if it is doing it wrong, it can be corrected in a principled way instead of hoping for training results to somehow “magically” remedy the problem.
In the end, we humans correlate intelligent computers as having the ability to talk and interact with computers just like humans that understand the “world” around them. It always comes down to language.
ChatGPT and Trust
What will large language models do and be for us? They certainly are not intelligent and are completely based on statistics and they certainly cannot be trusted. And therein lies the problem. For any advanced programs to be trusted, we have to be able to trace every step of what they are doing and why. We cannot allow black boxes that make life-and-death decisions. Blackboxes cannot be trusted for such decisions.
But if a computer program can show clearly what it is doing and why, then it can eventually build trust with tasks that were formally done by humans. A good example of this is self-driving cars. Self driving cars like Tesla are driven by software and they give instant feedback as to what the software is seeing in real time. This gives humans confidence because it shows that the computer program is seeing the same things a human is seeing.
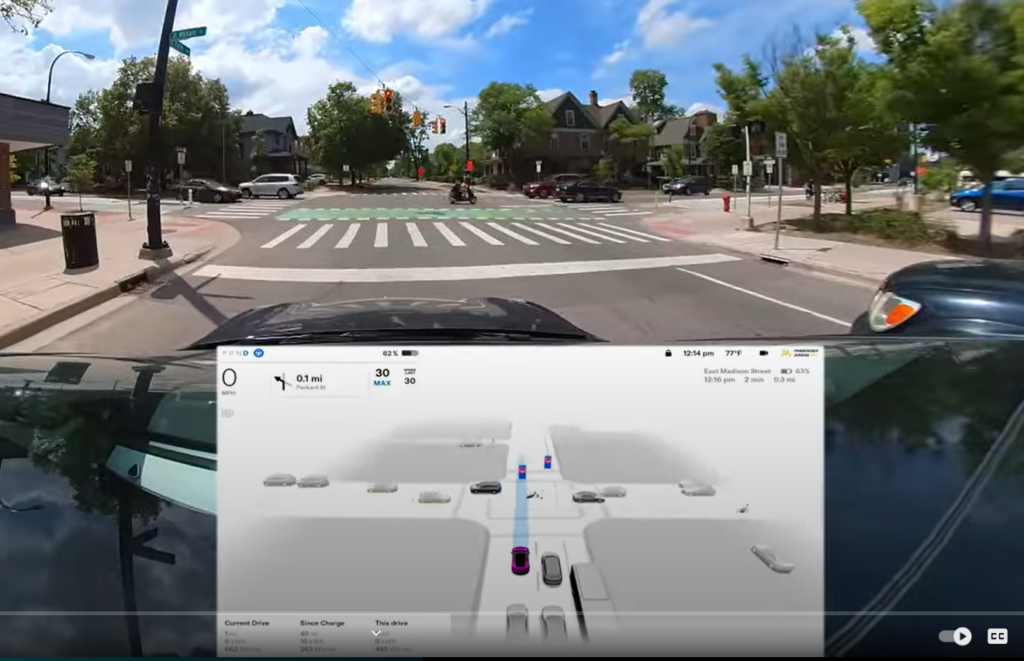
ChatGPT deals with text and the most it can do is to provide links to text written by humans so that humans can verify its response. The problem is that with many NLP tasks such as assigning medical codes or extracting information, statistical methods like Machine Learning or Neural Networks, cannot provide any meaningful feedback to the human user.
A computer language such as NLP++ is now being seriously considered by the computer industry as a way to write intelligent programs that can be trusted because they can explain their answers to humans much in the way that computer vision systems can display their “view” of the world to human drivers. Dictionaries, parts of speech (nouns, verbs, adjectives, etc.), world knowledge about a subject (knowledge of the human body), and logical decisions all can be encoded in one computer language that can be made to gain the trust of humans by being able to explain its logic.
ChatGPT and the Future
There are certainly uses for technology like ChatGPT and other large language models that will find their way into our everyday lives but in very specific and non-critical places. But ChatGPT certainly will not be found in operating rooms, legal briefings, and classrooms where “trust” is paramount.
HPCC Systems and NLP++
Given big data is a fact of life and often the bread and butter of many industries, LexisNexis Risk Solutions open source technology HPCC Systems is now fully integrated with NLP++. Already integrated with the outstanding packages for Machine Learning and Neural Networks, HPCC Systems now seamlessly can integrate linguistic and knowledge-based NLP with big data. Any NLP task that has been implemented in NLP++ can now run those analyzers across big data on bare metal or on the cloud.
Where humans have been assigning codes or reading text and extracting information, we now can start the process of building linguistic and world knowledge to do specific tasks that up until now, could not be handled by statistical methods including ChatGPT.
About the Author

David de Hilster is a Consulting Software Engineer on the HPCC Systems Development team and has been a computer scientist in the area of artificial intelligence and natural language processing (NLP) working for research institutions and groups in private industry and aerospace for more than 30 years. He earned both a B.S. in Mathematics and a M.A. in Linguistics from The Ohio State University. David has been with LexisNexis Risk Solutions Group since 2015 and his top responsibility is the ECL IDE, which he has been contributing to since 2016. David is one of the co-authors of the computer language NLP++, including its IDE VisualText for human language called NLP++ and VisualText.
David can frequently be found contributing to Facebook groups on natural language processing. In his spare time, David is active in several scientific endeavors and is an accomplished author, artist and filmmaker.