Data Lake Curation and Automation with Tombolo
Data Lake Curation
Data Lake technology allows for the rapid development of data-centric applications, providing for the acquisition, incremental analysis, and presentation of data to users. At the same time, it supports the continued evolution of the Data Lake by rapid development, potentially with many participants. Data Lakes allow for easy addition of new data sources and analytic algorithms, deeper integration and AI capabilities, and integration of multiple types of data, with continuous value enhancement for customers. For more details on Data Lake Technology, please see: Data Lake White Paper
It is easy, however, for a Data Lake to grow out of control if appropriate measures are not put in place. When this happens, Data Engineers’ productivity can plummet, resulting in delays in customer commitments, higher expenses, operational issues, and reduced competitiveness. Crossing of this threshold from productive Data Lake to festering Data Swamp can occur suddenly and without warning. The critical threshold is reached when the complexity of the Data Lake exceeds the capability of key personnel to hold the pattern of the Data Lake in their head. At that point, errors begin to occur when making changes, the pace of innovation slows, the ability to add new personnel is impaired, and schedules start to slip.
The goal of Data Lake Curation is to prevent such an event and allow the Data Lake to continue evolving rapidly as its complexity increases, and as more personnel begin to participate. Curation provides a map of the Data Lake. It tracks the usage and meaning of each Data Lake asset, such as files, and analytic processes. It gives a picture of how all the various pieces fit together. It also provides a central repository for all of the Data Lake’s documentation.
Tombolo 1.0
The Tombolo Data Lake Curation System 1.0 is the first open-source Data Lake Curation system for the HPCC Systems Platform. It allows creation of documentation along with the data and analyses that provides a roadmap into all aspects (assets) of the Data Lake: Data Files, Data Providers and Consumers, Data Ingestion and Analytics, and User Queries. Its global find facility allows users to rapidly locate any asset, or browse hierarchically to get the lay-of-the-land.
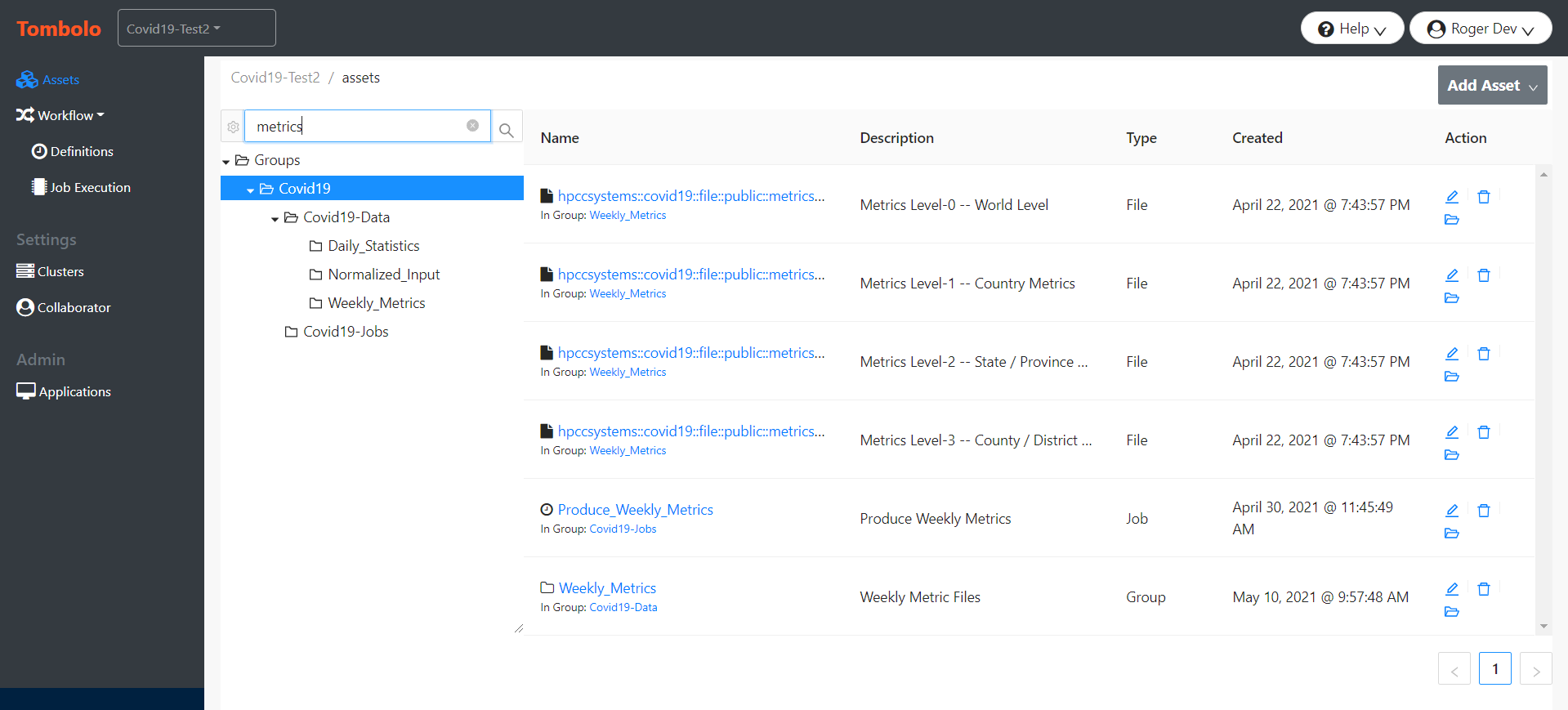
and allows navigation either to the item, or the containing group.
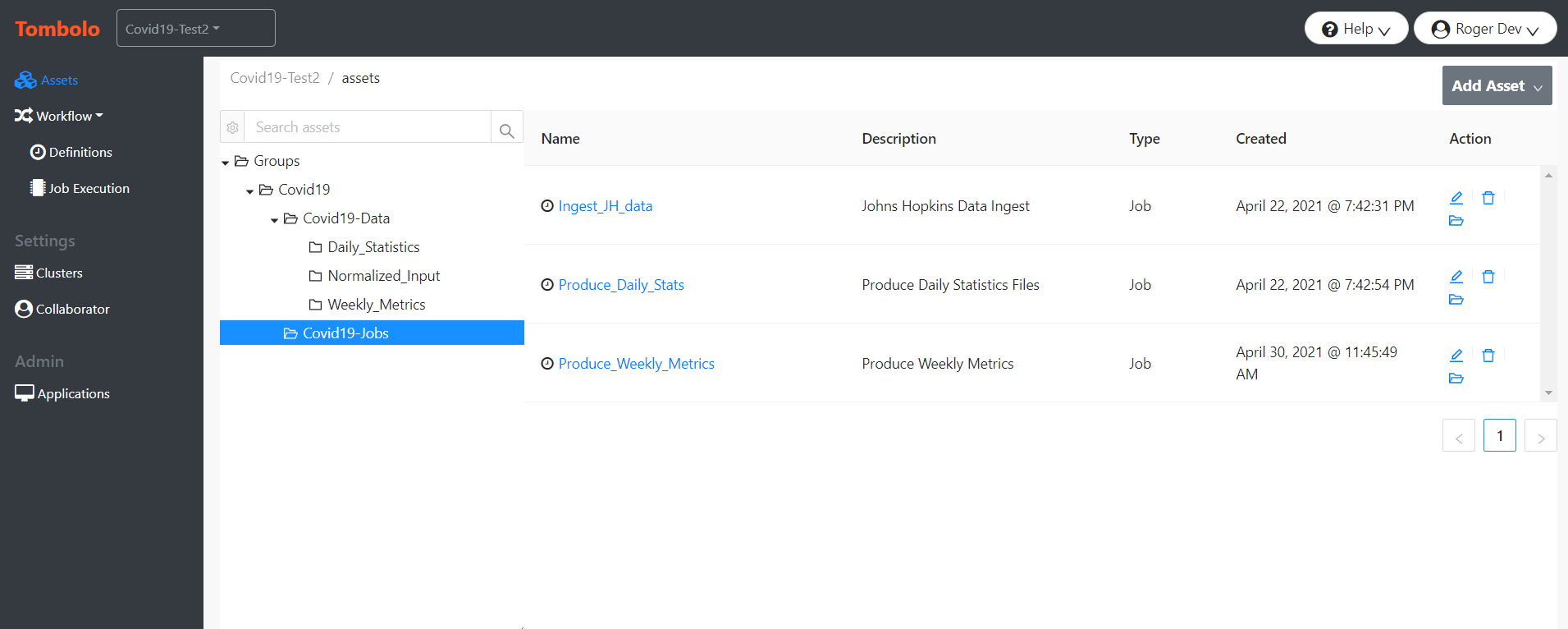
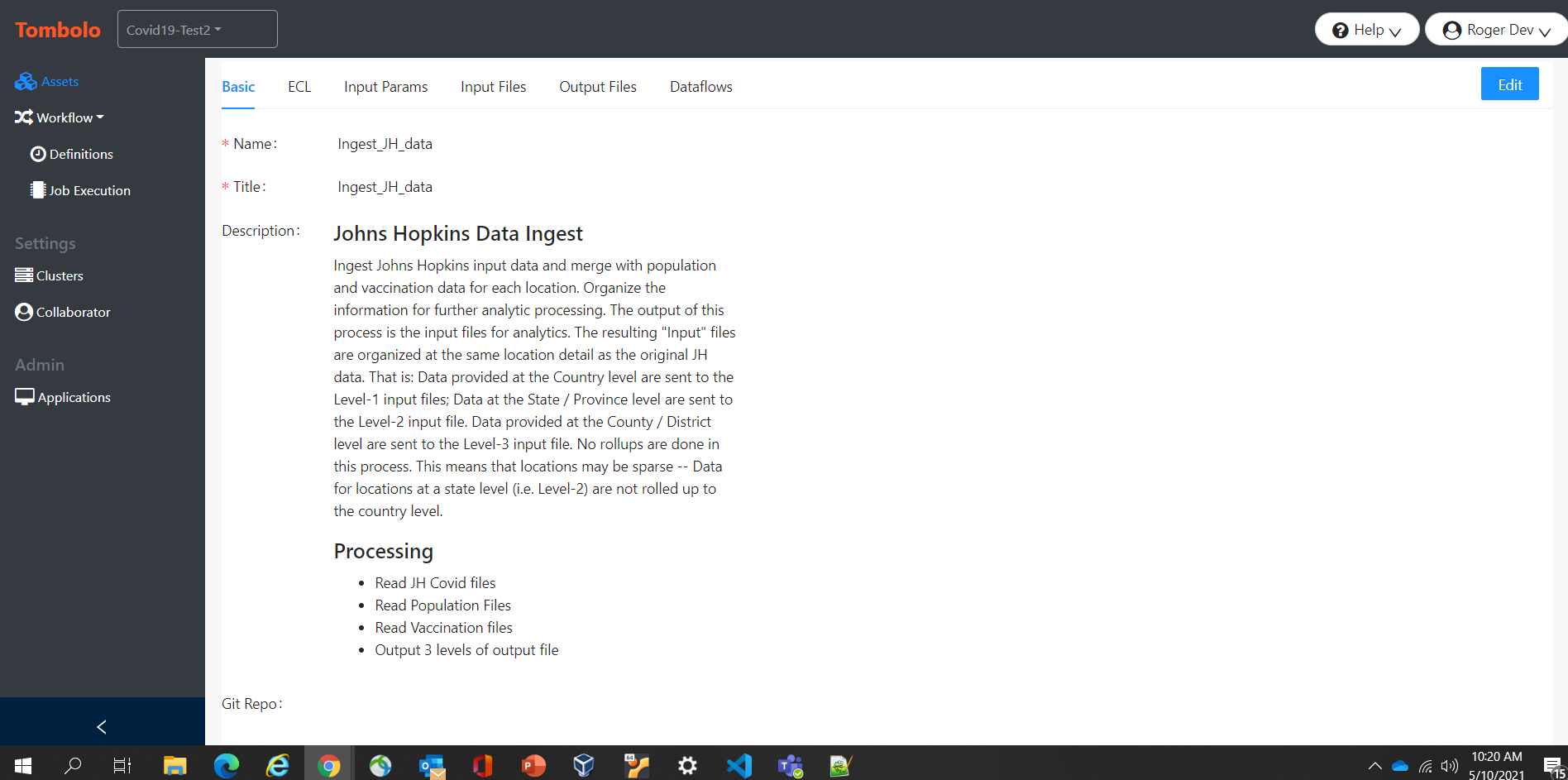
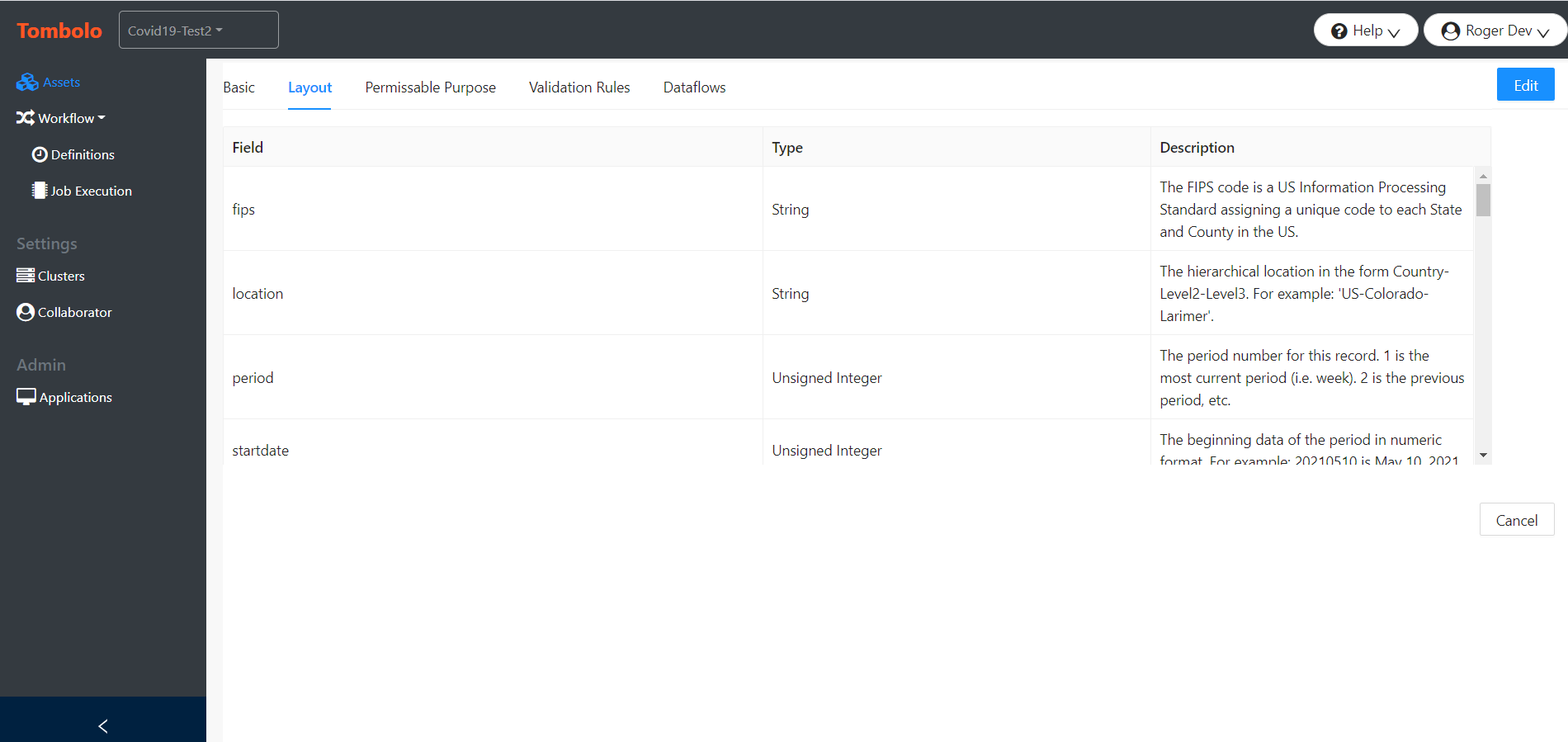
Tombolo can be used to design a new Data Lake or new portion of an existing Data Lake, or can automatically import information from an existing HPCC Systems Data Lake. In a design capacity, a developer can lay out the files, processes, and queries that will comprise the Data Lake, and later, when the files have been obtained, or analytics have been written, the “design” items can be attached to their real counterparts within the Data Lake. When that occurs, any available information from the Data Lake is automatically imported into Tombolo, and made available as part of the documentation. This information includes the data definitions, processing code, and the relationships between files and processing jobs or queries. In an add-on capacity, Tombolo can attach to an existing Data Lake and import all of the assets directly.
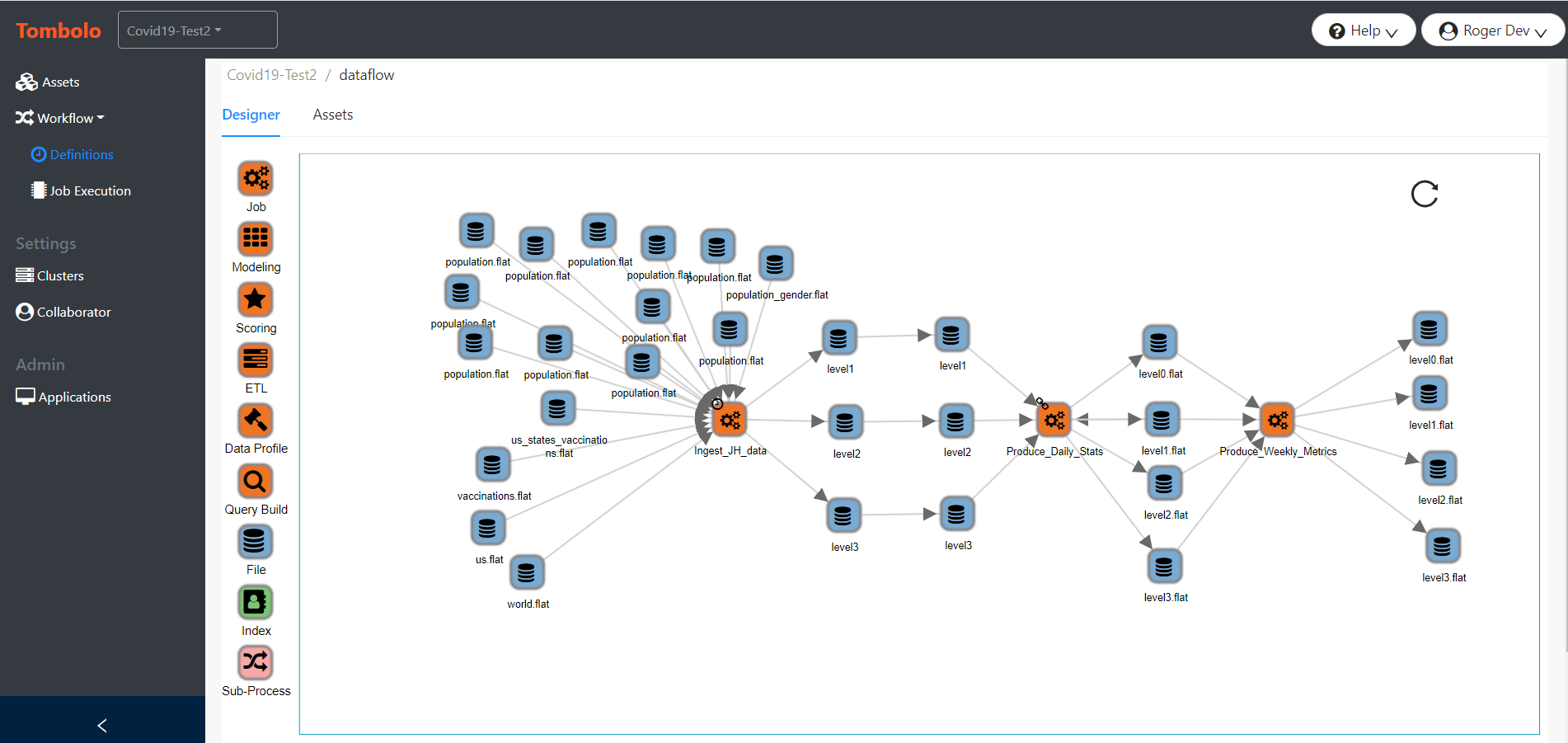
Tombolo provides a graphical way to map the workflows that keep the data lake running. Like the asset management capacity, Workflows can be developed in either a design or add-on function. They also have the ability to import data directly from the Data Lake. When a process (e.g. job) is added to the workflow, any input and output files are also pulled into the workflow and attached with arrows to the job icon. This greatly simplifies the task of keeping workflow diagrams up to date. Pressing the refresh button will automatically refresh the diagram, adding any new files or relations.
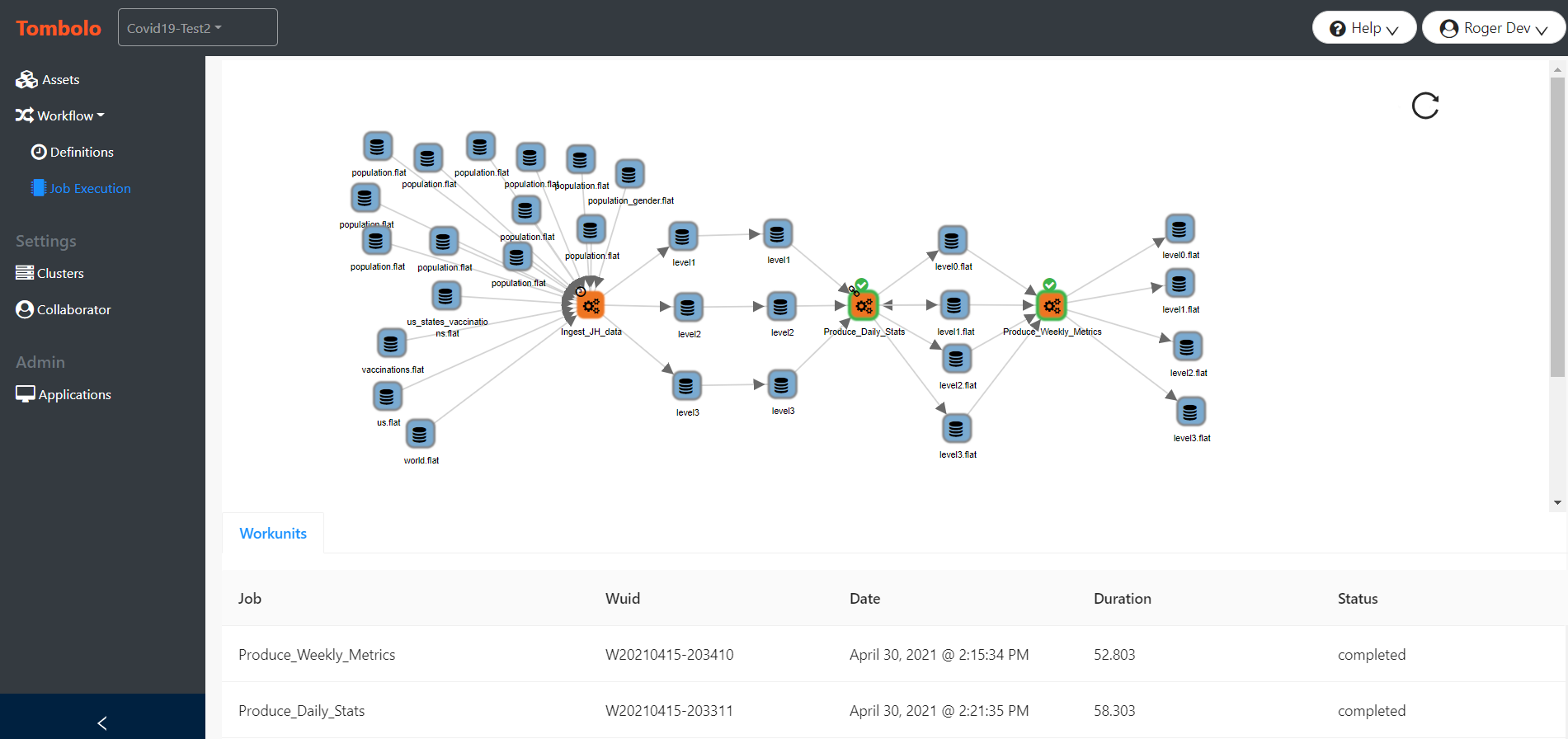
Another important Tombolo capability is Automation. This allows workflows to be created from within Tombolo by scheduling job executions. Jobs can be scheduled on a recurring time basis, scheduled upon the completion of another job, or manually executed from within Tombolo. This allows entire workflows to be built from within Tombolo without coding. Once these workflows are built and attached to the Data Lake, Tombolo monitors the execution of each workflow and notifies designated users if there was a failure. This automation capacity is expected to expand further in future releases of Tombolo, ultimately providing a complete Data Engineering workbench for HPCC Systems Data Lakes.
The current version of Tombolo provides limited governance support, allowing tracking of privacy, proprietary, and contractual constraints on the uses of data assets as well as provider / consumer relationship information. Future versions will significantly enhance these abilities, evolving Tombolo to become a full-featured Data Lake Governance system.
Tombolo has built-in multi-tenant support. Different groups of users (tenants) can be given access to different partitions of a Data Lake, or separate Data Lakes. Each Data Lake may encompass multiple HPCC-Systems clusters. Tombolo’s Access Control currently allows three levels of access for each tenant: read-only, read-write, or tenant administrator. Future versions will allow much more sophisticated access control, including constraint-based permissions.
The Tombolo Vision
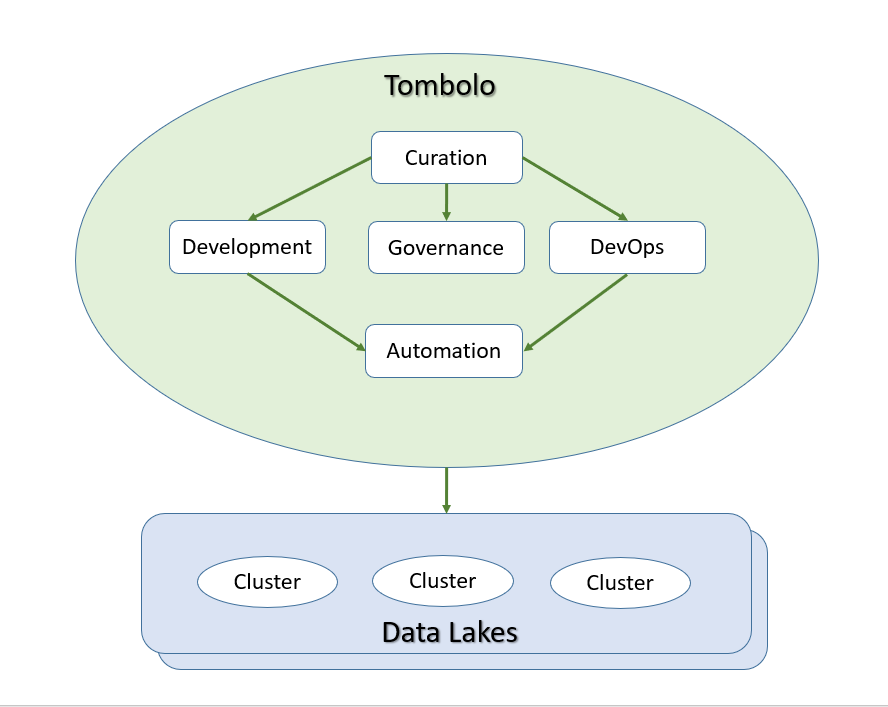
The vision for Tombolo is to become the central console for Data Lake developers and operators, providing all of the facilities needed for designing, developing, automating, documenting, and governing Data Lakes. The Tombolo vision encompasses a number of capabilities:
- Curation — Tracking, Documenting, and providing visibility into all aspects of the Data Lake.
- Development — Serving as an integration platform for developer tools.
- Automation — Setting up and tracking work-flows for various applications, from Data Ingestion to Customer Delivery
- DevOps — Automating the process of moving data and code from development / QA to Production
- Governance — Tracking of data restrictions (e.g. legislative, contractual, proprietary) at the source and propagating these restrictions to all derived data throughout the life-cycle. Detecting issues requiring governance review and inserting review requirements into the DevOps process.
Source Code and Installation
The Tombolo source code and installation instructions are available here.