Deep learning using HPCC Systems and TensorFlow
Jingqing Zhang is a PhD student studying at the Data Science Institute at Imperial College, London. He is currently working on a project which involves leveraging an HPCC Systems cluster with TensorFlowTM. This PhD project, funded via the HPCC Systems Academic Program, is led by Professor Yi-Ke Guo who is the Director of the Data Science Institute.
Our collaboration with Imperial College, London goes back to 2015 when we launched a contest to find a PhD student to work on a project focused on deep learning for text analysis using TensorFlow, while leveraging the strengths of HPCC Systems. Jingqing Zhang’s project is the result of this contest and I am following his progress as he works towards his goal.
The main aim of Jingqing’s PhD project is to use information gathered from academic abstracts to create a reference of individual topics in a Wikipedia type format. But it also needs to be quick and easy to use, giving users the information they want.

HPCC Systems is perfectly placed to handle the data processing side and delivery of the data. The idea is to use a Thor cluster for the data cleaning, normalization and linking and a Roxie cluster for the fast delivery of the data to the user. TensorFlow fits snugly in the middle of this workflow, providing the modeling based mainly on recurrent neural networks.
Quite a bit of preparation work has been going on in the last year because Jingqing needed to spend time becoming familiar with deep neural networks (especially sequence based methods). Flavio Villanustre and I visited him recently and we were delighted to congratulate him on achieving a distinction in his Masters degree in Research in Advanced Computing.

His Masters degree focused on four courses, machine learning and mathematics, computational optimisation, deep learning and dynamic systems and intelligent data and probabilistic inference. Jingqing completed three research projects involving deep learning and using machine learning methods. The four courses provided an overview on how deep learning and machine learning methods have evolved. The three research projects explored novel deep learning architectures to achieve better performance on time series and multi-modality problems. This experience provides the basis of the techniques and models he will use to complete his HPCC Systems/TensorFlow PhD research project.
This project is at an interesting stage right now. Jingqing is at the point where he needs an HPCC Systems cluster to use in his initial experiments. We have been working with him to setup an AWS test cluster he can use with TensorFlow.
So this was the perfect opportunity to meet with Jingqing again and properly introduce him to some of our HPCC Systems colleagues, who have been collaborating with him over the last few weeks. While the cluster is ready now, there are a few initial questions that need resolving about the hardware such as whether the nodes on the cluster have a GPU. Jingqing already has quite of bit of experience with TensorFlow and tells us how it always uses all the resources it can find and how he’d like to be able to control that by having access to the GPU on all the nodes. He’s also been having a bit of trouble getting his embedded Python3 code to run.
This is the point where I can tell this is going to be a good meeting. There is a lot of great experience around the table. John Holt leads our machine learning project and has been instrumental, alongside Timothy Humphrey, in getting Jingqing’s test system up and running. Jake Smith is our expert on all things Thor related and we also have Mark Kelly on the line who brings his experience of system configuration to the table.
Screen sharing doesn’t seem to want to work today, so Jake jumps in to support John’s comments using his laptop and then it’s heads together and they are off! It’s clear that Jingqing fits in so very well with this group. Initial coding issues are quickly resolved and then the conversation moves on to the integration process and how that might work.
At lunch, Jake had mentioned to me that he was interested to hear what the plan was for integrating TensorFlow into the HPCC Systems workflow. He mentions this now because, so far, all the talk has been about Thor and the cleaning and processing of the data. (Jingqing tells us how he spent a great portion of his time on that for his masters projects last year.) Jake goes on to mention how Jingqing might want to use Roxie to distribute the queries to the models and give a fast response. It’s not completely clear how all this will work. This is all part of the experimentation that will happen as part of this project. But the exchange is very positive and there’s lots to take from it judging from the approving looks and chin stroking going on!
This project is going to run for the next 3 years, so I wanted to get an idea of the stages involved in achieving the final goal. Jingqing tells me that he needs to get a data set, prepare it and perform some analysis on that dataset. He needs to try some models first to verify whether they work for the purpose he has in mind and once he is happy, make them more robust.
He also needs to decide on the structure of the pages in terms of what should be included and what may need to be done to make it user friendly. At our last meeting, Professor Guo mentioned that providing this type of abstract data would be incredibly useful to academics who are carrying out their own research in a specific area and want to know about related current and recent work. Jingqing adds to this mentioning that he wants to not only provide the latest information but also some historical information and a brief summary for users that have different needs. Each page will also need to include citations for any sources referred to within the text. He is also thinking about how the update process would work to include new information as it becomes available. In short, there are a number of challenges involved in this project.
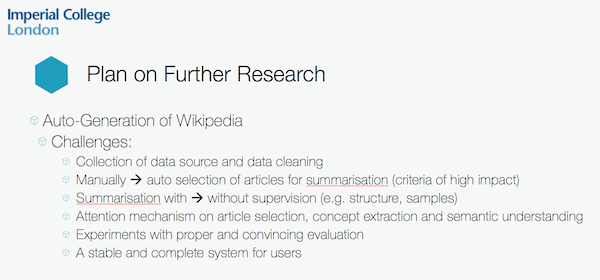
But right now, Jingqing plans to use the cluster we have provided to evaluate how efficiently HPCC Systems works with TensorFlow. He’s going to work on a couple of proof of concepts using some simple cases. He already has some time series data from one of his Masters research projects that he will use as a first test.
He’s wondering what will come out of this process and so are we! It will be interesting for us to see how Jingqing uses an HPCC Systems cluster with TensorFlow and whether his research throws up challenges that we can resolve at the platform level to help him and our open source community.
We plan to meet again early next year. I’m intrigued to see what he will discover from his initial tests, what we can learn from his use of HPCC Systems with TensorFlow and how this project evolves over time.
For details about using TensorFlow with HPCC Systems, read Richard Chapman’s earlier blogpost on Embedding TensorFlow operations in ECL.
Find out more about the three research projects Jingqing completed as part of his Masters degree: