Musings on Causality and Machine Learning
Causality
The human brain is, to a large extent, a causality processing engine.
If I tell you that there was an explosion in the next town, what would your first question be?
For most people, it will a variant of one of the following two questions:
“What caused it?”
“Then what happened?”
Both of these are causal questions. The first is the “why” question. The second is a form of “What was the result?”. They are essentially the first two major questions of causality. These two together give us the power of ‘explanation’.
Once you’ve explored these two questions, and understood the causes and effects of the explosion, it would be natural to ask: “What could have been done to prevent it?”.
This is a form of “What if?”, the third major question of Causality. What if something had been different? Would the explosion still have occurred? Would the damage have been reduced? By exploring all of the possible changes to the scenario (that is “interventions” or “counterfactuals”), you might be able to determine if anything could have been done to prevent it.
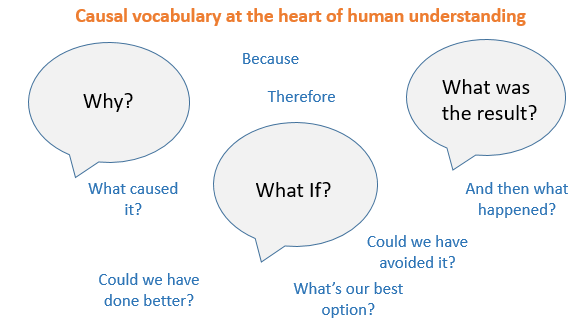
These “what if” questions are a critical component of our mental machinery — more so even than it appears at first glance.
The solution to the question “What should I do next?”, is to explore the “What Ifs” given certain courses of action, and to rate the predicted results. It is clear that we must employ causal models in order to do such an exploration.
Every human endeavor begins with a consideration of a web of causal models and questions of intervention to determine which course of action is likely to yield the best result.
Although our mental machinery appears to be highly tuned to the questions of causality, scientists and mathematicians have had surprisingly little to say on the subject. In 2011 Judea Pearl won the ACM Turing Award, in part for his insightful 2009 book: Causality[1]. In Causality, he documents most of what has ever been learned on the subject. In it, he creates a reference model for discussing causality, and presents the bulk of the work that’s been done in the field. Most importantly, in my mind, he introduces several algorithms for detecting causal relationships. This brings it from the field of philosophy to one of mathematics and engineering. I highly recommend reading it, if I’ve managed to pique your interest.
Professor Pearl sees Causality and Statistics as sister fields of Mathematics. Says Pearl:
“I now take causal relationships to be the fundamental building blocks of both physical reality and of human understanding of that reality, and I regard probabilistic relationships as but the surface phenomena of the causal machinery that underlies and propels our understanding of the world.” (Pearl 2009, position 338)
Causal versus Associative Models
When we peel back the layers of traditional Machine Learning and look at the models it creates, we can see that what is being modeled are the statistical patterns — the joint probabilities — of the historical operation of the system being observed. This allows for making statistical predictions. These are known as Associative Models, and I call these algorithms Associative Machine Learning (aML). The problems that are solved by these models can be stated as: “Given a set of measurements (X), what would have been the most likely value for another set of measurements (Y)?”. One could imagine that if we took the set of all measured features (X and Y) — lets call them U, and we regressed each feature of U on all the other features in U, we would get a model that could predict any feature of U given the remaining features of U. This is effectively the joint probability distribution of U. Restating the aML question in terms of U, we get: “What is the most likely value of feature f given the set of values for Uf (i.e. all the features of U, excluding f)?”
A Causal Model, on the other hand, represents a deeper reality. It is based on the fundamental structure of the underlying system — the web of causes and effects that drive the measured observations. If we were able to learn a Causal Model, we could answer, not only the associative questions answered by Machine Learning today, but also the three causal questions. If we restate these causal questions to match the above, we get: “Which features of U had a direct effect on a given feature f?”, “Which features of U did a given feature of f influence?”, and “If certain features of U had been different, what would have been the result on f?”.
Introduction to Causal Models
Figure 2 below depicts a causal model for the growth rate of trees in an orchard.
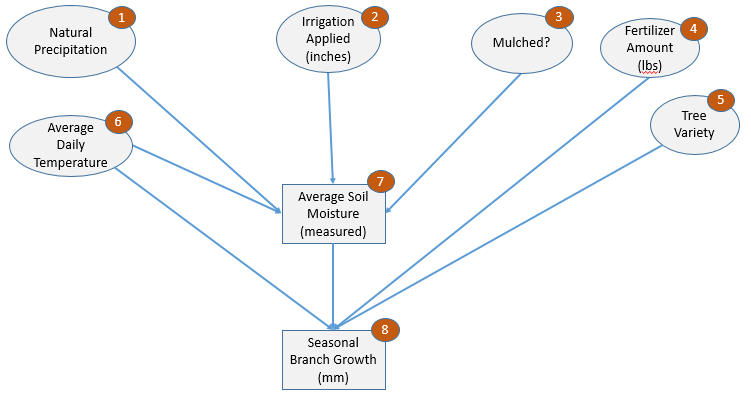
We represent causality as a Directed Semantic Graph. Each oval represents an “exogenous” variable — a variable whose values come from outside the causal model, while each rectangle represents an “endogenous” variable — a variable whose values are determined by the model.
Every link in a Directed Semantic Graph can be thought of as having two names. One in the forward direction (i.e. toward the arrow) and one in the reverse. In a Causal Network, the forward link is called “causes”, while the backward link is called “is-caused-by”. I prefer the labels “affects” and “is-affected- by” because I find it to be a bit more intuitive, and I will use those terms for the remainder of this discussion.
From the diagram it is apparent that growth (8) is-affected-by four factors: Temperature (6), Fertilizer (4), Tree Variety (5), and Moisture (7). Moisture (7), in turn, is-affected-by Precipitation (1), Irrigation (2), Mulching (3), and Temperature (6). Note that Temperature (6) affects growth both indirectly (via Moisture(7)) as well as directly (perhaps via accelerated respiration?).
Note that a Causal Model, like its Correlative counterpart is only an hypothesis.
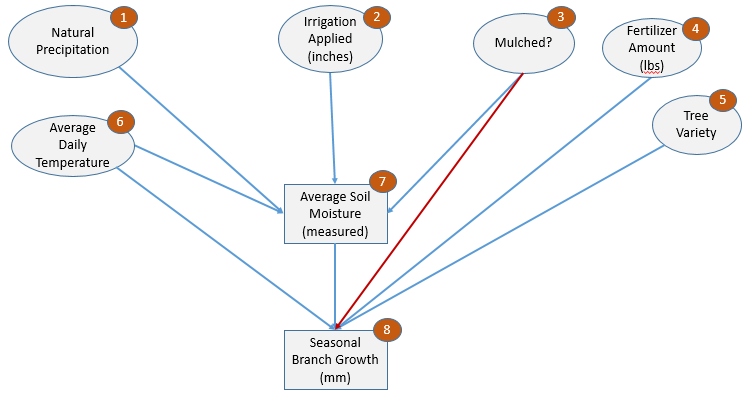
Figure 3 shows a slightly different hypothesis. We’ve added a single line between Mulching (3) and Growth (8) in red. This line says that mulching affects growth not just through retained moisture, but by some other mechanism as well (perhaps weed reduction?). How can we know which model is more correct?
It turns out that there are ways to mathematically evaluate Causal Models. If we can measure the conditional dependency of two variables, given a third variable, then we can determine the correct model. If all of the effect of mulching is based on water retention, then we would expect that Growth (8) would be independent of Mulching (3) when conditioned on Moisture (7). Likewise, if Growth is not independent of Mulching, given Moisture, then there must be some independent influence of Mulching on Growth.
One way of determining such independence is through the information theoretical measurement of conditional mutual information (CMI). I discuss this example to illustrate that causality is mathematically tractable, and not just a philosophical notion.
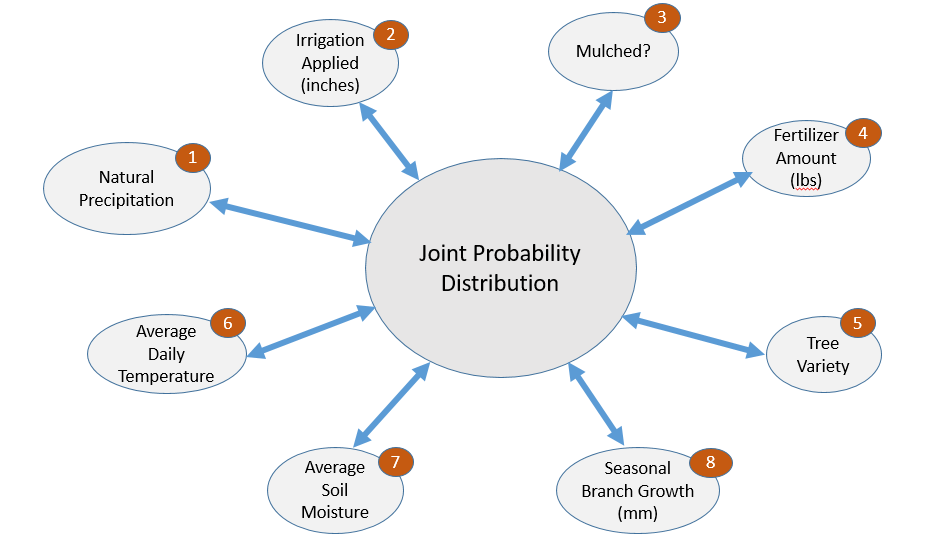
Figure 4, by contrast, illustrates an Associative Model of the same system. Each variable (feature) is tied to the joint distribution of all features. There is no distinction between exogenous and endogenous features.
With the Causal Model in Figure 2, one can ask the counterfactual question: “What would be the effect if I hold the Soil Moisture constant at 60 percent?”. If I ask the same of an Associative Model, the response could reasonably be that Precipitation (1) would decrease. This is the nature of associative models. There is no inherent directionality, nor underlying structure, so if one feature f is held constant, the distribution of all of the other features would have to adjust to reflect those scenarios in which f had been observed to have that value.
Learning Causal Models
Do we have any mechanisms to construct causal models from data? There are some, but at this point, they are brittle, expensive, and unreliable.
The longest standing (and still the only practical) method for understanding causality is the scientific method. Through carefully controlled experiments, the causal network can be painstakingly mapped out. This is not only very expensive, but not suitable for all fields of study.
What of data from Natural History, or Human endeavors such as Economics or Medicine? It is impossible to perform controlled experiments in areas of natural history, impractical to perform controlled experiments on entire economies, and unethical to provide overdoses of medicine to determine the effect. Imagine the impact on our knowledge if we could answer causal questions through analysis of the data.
There are three major methods that I know of that can be used to extract causal information from data. I have implemented and experimented with each of these. I expect that more will be discovered over time.
The good news is that there are any. The bad news is that the causal signals are very weak, and can require far more data and processing power than even Machine Learning. Furthermore each of the algorithms so far have serious limitations that render them mostly impractical. Nonetheless, I summarize the three algorithms here because they prove to us that causal learning is not hopeless, and may spur the imagination.
Mechanism 1 — Conditional Independence
The first mechanism is based on measuring the Independence and Conditional Independence of variables. In information theory, this is measured as Mutual Information (or Conditional Mutual Information). Two random variables that have zero Mutual Information are considered Independent.
A Causal Network such as shown in Figure 2 above is composed of few basic sub-structures tied together. If we can identify sub-structures, and splice them together, then we can build a causal model. Figure 5 below shows some of those sub-structures.
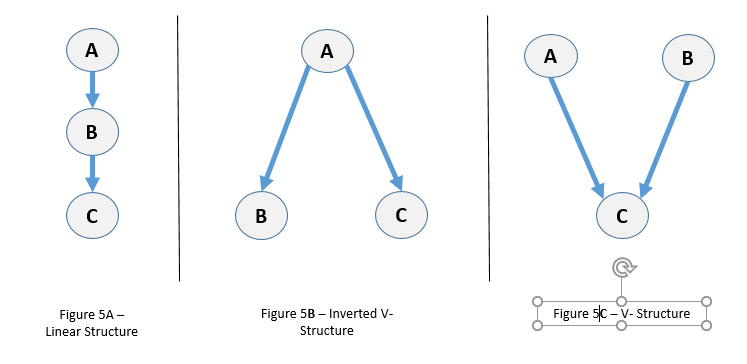
In Figure 5A, we have three events that are sequentially related: A affects B affects C. This is known as a ‘linear’ or ‘chain’ structure. Chain structures have distinct independence characteristics. For example, it must be true that C is independent of A given B. Conversely, it implies that C is not independent of B given A, since some of B’s influence that didn’t come from A would not be blocked by conditioning on A. Therefore it can be determined that the only correct ordering is A -> B -> C.
Figure 5B shows a single event affecting two other events. This is known as an Inverted V-Structure. This case also has a distinctive independence signature. A and B are Dependent, AND A and C are Dependent, AND B and C are Dependent, AND B is independent of C given A.
Figure 5C illustrates a V-structure, the convergence of two causes onto an effect. This can be recognized by the fact that A and B are independent AND A is not independent of B given C. This is not very intuitive, but can be proven (see Pearl 2009 for explanation).
You can see that different causal structures have a unique signatures in terms of independence and conditional independence. An algorithm known as the PC Algorithm after its authors initials, (Pearl 2009, position 1956, chapter 2.5) uses these signatures to identify these structures among data features and stitch them together into a full causal network. This can be shown to work quite well in toy problems, subject to some limitations: 1) There are some networks that can’t be fully mapped because certain structures cannot be differentiated and 2) Determining independence, and especially conditional independence is not easy. It requires a lot of data and computation, and there is no clear cutoff threshold between independence and dependence.
Mechanism 2 — Central Limit Theorem
The second class of methods is based on the Central Limit Theorem. As you additively combine different non-Gaussian random variables, the mixture becomes more Gaussian. Therefore, the variable that is the least Gaussian of two causally related variables is likely to be more causal. One variant of this method, called LINGAM [2] can successfully reconstruct a causal graph from a set of variables and simultaneously parameterize a Linear Structural Equation model that can be used to answer counterfactual (i.e. what if) questions. This will work as long as there is sufficient data, the relationships between the variables are linear, the noise of the variables is non-Gaussian, and the magnitude of an effect is not too weak.
Mechanism 3 — Delay Embedding
The third class of methods is based on Chaos Theory, and Taken’s Theorem, and is applied to time-series data. In this approach we consider that the evolution function of the time-series is approximated by taking a series of N lags of the time series value (e.g. now, 1 day ago, 2 days ago, 3 days ago …) and projecting them into N-dimensional state space. These projections are known as ‘attractors’.
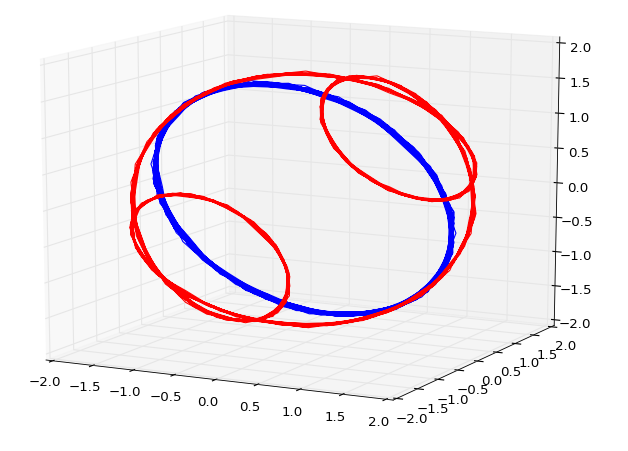
Figure 6 above shows the attractor for a noisy sine wave (blue), and the sum of two noisy sine waves (red). More complex, chaotic time-series may reveal an unexpectedly orderly shape in state space. These are known as ‘strange attractors’. If we take the state space evolutions of two different variables, the most causal will tend to follow a shorter path. This makes sense if you think of the effect variable as combining the effects of the cause variable plus something else. This is illustrated in Figure 6: The red trace is the sum of the blue (sine wave) plus another sine wave (not shown). This path length differential can be detected via random sampling, and used to determine causal order. I have not seen a way to use this method to recover a full model, but it is nonetheless a useful tool in the causality toolkit.
Causal Machine Learning
As you can see from the above, extracting causal information is tenable. We’re not there yet, but it is a very young and very active field or research. All of the above algorithms were developed in the past 20 years. The very language and notation for talking about causality has only recently developed.
There are a number of ways that Causality and Machine Learning can intersect. Perhaps ML can generate a series of models (i.e. hypotheses) that can then be tested to determine the model that is most consistent with a causal model (e.g. based on independencies). Perhaps a series of causally consistent models can be built using Causal methods, and then tested by aML for associational consistency. Or maybe there is a combination of causal and statistical methods that can consider both aspects at once as it builds the model.
I envision an approach that constructs a causal model, using causal discovery methods like those above, but in which the links between features are each determined and specified by a machine-learning model. Note that in a causal model only the direct causes need to be considered when predicting the effect variable.
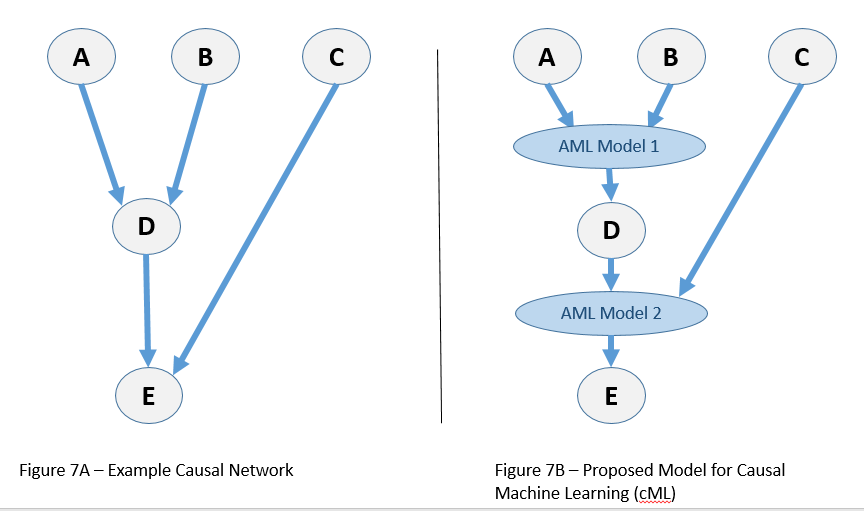
Consider the Causal Model depicted by Figure 7A. Only C and D can have an effect on E. Therefore, an Associative ML (aML) model would be built in which C and D are the independent variables and E the dependent (as shown) in Figure 7B. Likewise, a second aML model would predict D, given A and B. Each aML model would have fewer features to consider, and would therefore be a more compact model. Assuming that the causal model is correct, one could use this model to pose counterfactual questions, such as: “If D were held constant at 5.5, what values would E take?”. This model also provides explanatory value: A and B can effect D, while D and C can affect E. It also, via aML provides the details of these relationships.
I consider cML to be a very important topic for future research. I would be interested in hearing from anyone who is involved in, or has ideas for such research.
Causality and AI
In the quest for generalized AI, it is difficult to imagine a successful model that doesn’t account for the mechanisms of causality that seem to form the core of our understanding about the world. To again quote Professor Pearl:
“Machine-learning systems have made astounding progress at analyzing data patterns, but that is the low-hanging fruit of artificial intelligence. To reach the higher fruit, AI needs a ladder, which we call the Ladder of Causation. Its rungs represent three levels of reasoning.”
“Current machine learning systems can reach higher rungs only in circumscribed domains where the rules are inviolate, such as playing chess. Outside those domains, they are brittle and mistake-prone. But with causal models, a machine can predict the results of actions that haven’t been tried before, reflect on its actions, and transfer its learned skills to new situations.”
“This is a beginning. When researchers combine data with causal reasoning, we expect to see a mini-revolution in AI, with systems that can plan actions without having seen such actions before; that apply what they have learned to new situations; and that can explain their actions in the native human language of cause and effect.” [4]
Conclusion
I hope I’ve managed to spark some new thoughts and ideas. I believe this to be a key area for future research. While the goal of a full cML is beyond today’s reach, it is not difficult to imagine a scenario in which causal models can be partially discovered by machine algorithms, refined by human knowledge, and driven by aML relationships. I will be surprised if practical applications of these methods are not found in the next few years. I hope to find the time to contribute to this promising nascent field. I would like to hear from anyone who has an interest in pursuing such research. (Contact me) To paraphrase one of the worlds most interesting men:
Think causally, my friend!
References
[1] Judea Pearl. “Causality: Models, Reasoning, and Inference”, Cambridge University Press, 2000, 2008, Kindle edition.
[2] S. Shimizu, P. O. Hoyer, A. Hyvärinen, and A. J. Kerminen.
“A linear non-gaussian acyclic model for causal discovery”.
Journal of Machine Learning Research, 7:2003-2030, 2006.
[3] George Sugihara, Robert May, Hao Ye, Chih-hao Hsieh, Ethan Deyle, Michael Fogarty, Stephan Munch, “Detecting Causality in Complex Ecosystems”, Science Vol 338, October 2012.
[4] Judea Pearl and Dana Mackenzie “AI Can’t Reason Why”, Wall Street Journal, May 18, 2018, https://www.wsj.com/articles/ai-cant-reason-why-1526657442