Roxie Query Performance Part 2 of 2

Updates in HPCC Systems Boost Roxie Query Performance
In the previous post in this two-part series, we looked at how information available in Roxie logs can be used to determine what part of a query was consuming the most time.
In this post, we’ll cover other updates to Roxie index format now available starting in v9.2.x that can help reduce query times. But before we do, it would be helpful to reexamine how a Roxie index works. A Roxie index is implemented as a b-tree using fixed size nodes on the disk (usually 8KB). There is a single branch node at the root of the tree which is searched first. That provides a mapping between the keyed data and details of which node to search next. The search process then repeats on the second-level branch nodes until you get to a leaf node with the actual data. This process is illustrated in the diagram below.
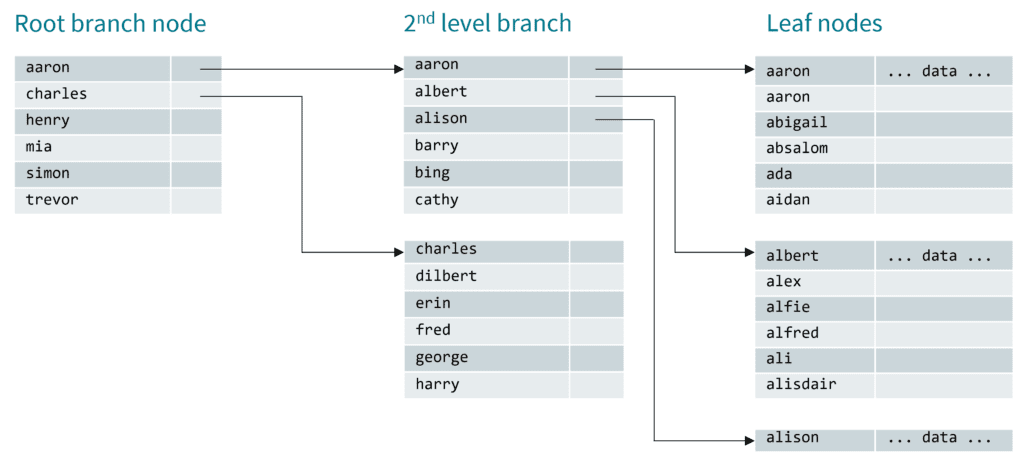
The number of branch nodes to be searched before reaching the leaf node varies with the size of the data; the root node may be sufficient for a smaller index. Larger datasets generally require 2 or 3 levels of branch nodes before the leaf node is reached.
Please note: the number of branch levels will depend on the size of the keyed data. Nodes have a fixed size, so the larger each key entry is, the fewer entries can fit into each branch node. Fewer entries in each branch node means that more layers are needed in the tree.
This is one reason why it is important to define indexes carefully. Data that is never used in a keyed filter should always be in the payload of an index. If a payload field is incorrectly included in the keyed portion, it will be included in all the branch nodes. This additional data reduces the number of entries each node can hold and increases the number of branch nodes. An easy way to potentially improve search performance is to move incorrectly keyed fields to the payload to remove levels from the search tree. This is because while branch nodes only consist of about 1 percent of the data used in a query, they are accessed up to 100 times more often than a leaf node.
So, after making sure that the index data is correctly identified as keyed or payload data, what else can be done to the index to further improve Roxie performance? Possibilities include:
- Reducing the time that it takes to find an entry within a node.
- Reducing the time it takes to read a node from disk.
- Reducing the time to decompress and process it so it is ready to be searched.
- Improving the compression.
- Reducing the number of levels that need to be searched.
- Improving the number of nodes that can be held in memory.
After modelling the index read process we concluded that raising the number of nodes stored in memory would have the most impact on Roxie query performance.
The index nodes currently expand by a factor of about 5 when they are read into memory. Reducing this expansion would mean more nodes could be held in their expanded form. If there was an index format with a similar level of compression that could be searched without decompressing that would be ideal. HPCC Systems developed such a solution, and the example below illustrates how it works.
Suppose a data node in a query contains 8 names stored in a seven-character string field. In the Roxie index format that is exactly what the node contents would look like – a list of seven-character strings.
| a | b | e | l | |||
| a | b | i | g | a | i | l |
| a | b | s | a | l | o | m |
| b | a | r | r | y | ||
| b | a | r | t | y | ||
| b | i | l | l | |||
| b | r | i | a | n | ||
| b | r | i | a | n | y |
In the updated Roxie index format, the new key representation looks like this.
opt(2)
'a' count=3
match("b")
opt(3)
'e' match("l") sp(3)
'i' match("gail")
's' match("alom")
'b' count=5
opt(3)
'a' count=2
match("r")
opt(2)
'r' match("y") sp(2)
't' match("y") sp(2)
'i' match(3, "ill") sp(3)
'r' match(3, "ian")
opt(2)
' ' sp(1)
'y' sp(1)
In this index format, the first character has two options – it can be an “a” or “b.” If an “a”, then it must be followed by a “b”, but there are three options for the third letter. If the third letter is an “e” then the next character must be an “l” and the rest of the field should be space padded.
What if the query is searching for the name “ben”? If we use the index format above, we will skip the three items starting with “a” before attempting to match the second character, “e”. The first two “b” items have “a” as the second letter, so they are skipped. And as “e” comes before “I” alphabetically and the next name in the index uses “I” as its second letter, “ben” won’t be found in the list of names. The query could then be concluded without having to check the remaining names on the list for a match to “ben.”
The latest version of Roxie contains other optimizations that help reduce the index size for common use cases, including:
- Compressing repeated spaces/zeros.
- Compressing ranges of options e.g., 0…9, A…Z
- Common up sub trees that happen to be identical.
- Compressing the “next-node” links.
- Compressing common characters.
With these optimizations, Roxie can now search compressed keyed data in about the same time as uncompressed data. The new compressed index format also seems to compress data better than the old format; branch nodes using the new index format take up about half the space on disk and a third to a fifth of the space when stored in memory. Better compression means fewer branch nodes in each level – which means the level above needs fewer entries.
HPCC Systems also applied this new compressed index format to leaf nodes. The data from leaf nodes is split into two, with the keyed portion using the same compression technique as the branch nodes, but a different compression technique for the payload. After evaluating various compression schemes including column compression, compressing single rows and blocks of rows, using custom dictionaries, and row compression that didn’t need expansion to memory, we settled on LZ4 compression– offering good compression and very fast expansion.
The impact of the new index format will depend heavily on the content and structure of the indexes. In some preliminary testing we have seen a 25 percent reduction in the size of the indexes and a 25 percent reduction in the time to read from those indexes. To take advantage of the more efficient query capabilities added to Roxie, users should upgrade to version 9.2.x or greater as soon as possible. And when you do, we’d love to hear from our user community about how their query times have improved. We encourage HPCC Systems users to reach out to us at info@hpccsystems.com and let us know!
About the Author

Gavin Halliday
SVP and Head of Platform Engineering, LexisNexis Risk Solutions
As the SVP and Head of Platform Engineering, Gavin is the lead for open-source platform development. He has been with LexisNexis Risk Solutions for more than 30 years and is one of the original architects of the HPCC System platform. He has worked on many parts of the system over the years and is the lead developer of the HPCC Systems ECL code generator.