The Hidden World of Unicode – From Text to Emojis
When we use our smart phones, we are used to texting each other using our own native language, often a second language (more and more people are multi-lingual), and something newer than text: emojis. Not only do smart phones have to deal with all this, servers, databases, text processors, and even machine learning have to be able to navigate this strange world of modern text.
This is a world that most programmers don’t have to worry about much. With today’s UTF8 standard: data is data. But how can that be? And what is the magic behind the curtain of what is commonly referred to in the computer business as Unicode?
Dilemma
In the beginning, computers only dealt with American English. With one byte (8 bits of 1s and 0s), we could store up to 256 different characters. That was fine. Some early computers only dealt with all capitalized letters like my first computer, the TSR-80 from 1978.

But as more and more countries adopted the computer, computers had to deal with more and more characters and when the smart phone came into use, there were emojis and the number of characters quickly grew past the 256 limit. If 2 bytes were used, one could store up to over 65,000 characters. But in today’s modern world of text, such a system brings up various dilemmas that are created if we used 2 bytes for all characters.
Since the majority of Indo-European languages use the first 128 characters, using two bytes for every character would not only unnecessarily increase the size of files, but also slow down the processing of that text. The second dilemma is if you don’t use two bytes, how can you mix characters that need one, two, three bytes or more?

UTF8
The answer came in July of 1992 when Dave Prosser of Unix System Laboratories submitted a proposal for a faster more efficient implementation for character storage and reading. The X/Open committee OxJIG was looking for a better encoding for a universal multi-byte character set. There was a draft for such a character set back in 1989 but the character set was not satisfactory on performance ground and other concerns. Dave’s system was ingenious and one of the forgotten inventions in the computer world that is used now by billions of people world-wide every day without knowing it.
Prosser’s idea was to come up with 5 or more unique codes that would start each 8 byte sequence. If the byte started with a zero, it was a one byte character which is represent the oldest and more used characters for computers. For two bytes, the first byte started with a “110”, for three bytes, “1110”, and four bytes, “11110”. The following extra bytes would all be marked by “10”. There were five codes in total: “0”, “10”, “110”, “1110”, and “11110” making it clear how many bytes were needed for a particular character. The rest of the bits were left for encoding a specific character. Text files could handle thousands of Chinese characters and still efficiently encode the standard character set.
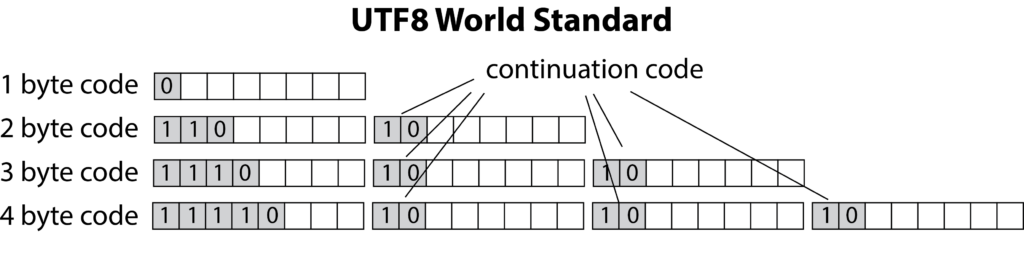
Dilemma Solved
This was not only an efficient use of space, performance wise, it was extremely fast to read. It solved the two main dilemmas. First, the majority of text which fell into the range of one byte, only wasted on bit per byte (8 bits). Second, it allowed for mixed length byte characters in the same text. This has become even more important given the introduction of emojis into our daily lives.

Programming UTF8
Most heavy-duty programs that deal with characters such as texting apps and word editors use the programming language C++ or Java. Fortunately, there is a Unicode Package for both that is standardized to deal with the multitude of languages used today. The package is ICU package or “International Component for Unicode” package. This package allows programmers to manipulate text without having to worry about what language is being used.
Capitalization, word comparison, and search need to know about each language. Some languages have different forms of the same letter such as capitalization or letters with accent marks. This means that if someone is editing text in Kurdish, when the user wants to capitalize the letters in an editor, the programmer need only call a function string_to_upper which will change all the characters in the selected string into upper case. The ICU package knows how to deal with each language.
The package also deals with date and time format for each language as well which is an added bonus for programmers.
Unicode and HPCC Systems
Here at LexisNexis Risk, the HPCC Systems supercomputing platform has a plugin for dealing with Unicode string manipulation that uses the C++ ICU package. Also, the NLP++ plugin that allows for calling NLP analyzers within the supercomputing language ECL, it too will use the ICU package (at the time of writing this article, it was being implemented).
HAIL UTF8!
So, the next time you are texting someone in one or more languages and inserting emojis into the text, you now know how the brilliant system of UTF8 invented by Dave Prosser has made this all possible!
*************************

David de Hilster is a Consulting Software Engineer on the HPCC Systems Development team and has been a computer scientist in the area of artificial intelligence and natural language processing (NLP) working for research institutions and groups in private industry and aerospace for more than 30 years. He earned both a B.S. in Mathematics and a M.A. in Linguistics from The Ohio State University. David has been with LexisNexis Risk Solutions Group since 2015 and his top responsibility is the ECL IDE, which he has been contributing to since 2016. David is one of the co-authors of the computer language NLP++, including its IDE VisualText for human language called NLP++ and VisualText.
David can frequently be found contributing to Facebook groups on natural language processing. In his spare time, David is active in several scientific endeavors and is an accomplished author, artist and filmmaker.