TextVectors — Machine Learning for Textual Data
Have you ever encountered a set of data in which some important information is stored as free-form text? Have you wished you could extract the meaning of that text and utilize it for analysis, inference, or prediction? If so, Text Vectorization may be the tool you are looking for.
Text Vectorization allows for the mathematical treatment of textual information. Words, phrases, sentences, and paragraphs can be organized as points in high-dimensional space such that closeness in space implies closeness of meaning.
The new TextVectors bundle from HPCC Systems supports vectorization for words, phrases, or sentences in a parallelized, high-performance, and user-friendly package.
This allows text to be analyzed numerically and combined into Machine Learning (ML) activities.
This article starts with an exploration of the philosophical basis for Text Vectorization, and the technology behind it. We then present the new HPCC TextVectors bundle, and follow up with an actual case study. Finally, we include a tutorial along with the ECL code needed to run TextVectors on a HPCC Systems cluster.
Background
In 1957, the linguist John Rupert Firth stated: “You shall know a word by the company it keeps.” [1].
We can restate this more rigorously as: “The meaning of a word is closely associated with the distribution of the words that surround it in coherent text”.
At first glance, this seems hard to fathom. We normally think of “meaning” as a deeply philosophical concept that is tied to symbolic association between words and objects in the physical or mental world.
How can meaning be derived from probability distributions among words?
Let’s do a thought experiment:
Let’s start with a large Corpus (i.e. collection of text) such as: every article in Wikipedia. Now we focus in on one particular word that is used in that Corpus.
How about “Dog”?
Now let’s think of another word that is different, yet similar to Dog — “Cat”, and another word that has little relationship to a Dog — “Piston”.
There are a lot of things that can be (and likely have been) said about dogs that can also be applied to cats.
- A dog / cat is an animal.
- Dogs / cats can make good pets.
- Dogs / cats are carnivores.
- I have a companion dog / cat.
- My son was bitten by a dog / cat.
Notice that none of these are likely to be said about a Piston. Piston has it’s own large set of possible sentences in which it occurs.
Now let’s look at some things that can be said about dogs that are unlikely to be said about cats.
- My dog weighs 140 pounds
- When I throw a ball, my dog brings it back to me.
- My dog barks whenever the mailman comes.
- Cocker Spaniels are a medium size dog breed.
Clearly, it would be surprising to find any of those statements in our corpus if you replaced the word dog with cat.
Now imagine that there are two words such that there is no sentence you can construct that would be reasonable for one word, but unreasonable for the other. If you think about that, you would have to conclude that the two words must be synonyms — they have the exact same meaning.
Now, Let’s return to Cat and Dog. We can say that they are similar because there are many contexts in which the two are interchangeable, yet dissimilar because there are also many contexts where only one or the other apply. If we compare Dog to Piston, however, we have to concede that there are few sensible contexts where one could replace Dog or Cat with Piston. This lets us conclude that Dog is closer to Cat than either word is to Piston.
Hopefully, this thought experiment convinces us that John Rupert Firth was onto something.
Let’s introduce another term to ease the philosophical strain. Rather than saying that contextual interchangeability equals “meaning”, let’s call it “contextual meaning”.
Now we can say that “contextual meaning” is very close to the colloquial concept of “meaning”, without needing to argue that there is no aspect of “meaning” that is not captured by this notion.
For the remainder of this article, when I use the term “meaning”, it is a shorthand for “contextual meaning”.
With this behind us, let’s try to understand Text Vectorization.
Text Vectorization
Text Vectorization is a method of encoding (contextual) meaning as a vector (ordered set) of numbers.
It is useful for understanding Text Vectors to think of a vector as the coordinates of a point in N-dimensional space. It takes 2 numbers (i.e. vector of length 2) to specify a coordinate in 2-dimensional space, 3 for 3-dimensional space, and therefore a vector of length N can represent a coordinate in N-dimensional space.
We can then think of each word as occupying a point position in that space, given by its vector.
Note that words can have many shades of meaning: Dog is an animal, but it is also a device that holds logs in position during the milling of logs in a sawmill. It is also a verb meaning to follow or track. So, while dog must end up close to cat, it also may end up close to “sawmill”. Yet cat is not associated with sawmill, so it must end up far from sawmill.
This is where high dimensionality comes in. Cat and dog are close together in some dimensions, while in others, dog and sawmill are close but cat and sawmill are far apart. It is useful, though not strictly correct, to think of the multiple dimensions as potential shades of meaning for words. Words often have many subtle shades of meaning and relationship. Therefore we typically use vectors of length 50 – 500 to allow for such flexibility.
So the trick to creating a vector for a word is that the word should be close to all words with similar meaning and distant from all words with dissimilar meaning.
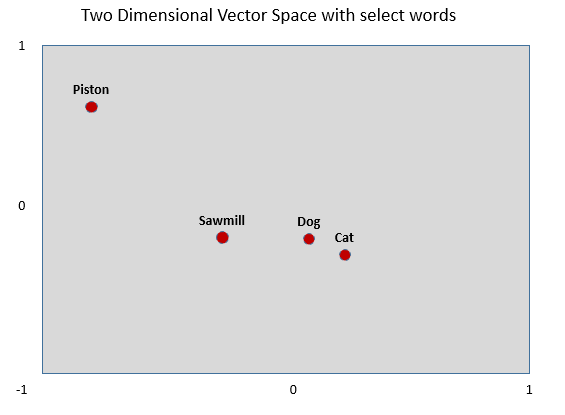
We can think of this as an optimization problem. How do we construct vectors such that words that are found in the same or similar contexts end up close to each other, while words that are never in the same context are far apart?
Fortunately, there are various mathematical ways to do such an optimization. One of the most successful and practical involves the use of Neural Networks. Even within that approach, there are various sub-approaches. I will only illustrate one of these approaches (the one currently employed within the TextVectors bundle). This is known in the field as Continuous-Bag-of-Words or CBOW.
The Continuous Bag of Words (CBOW) algorithm
We start by assigning a number 1-N to each word in the vocabulary. The input to the Neural Network consists of one bit per vocabulary word, with 1 meaning the word is present in a particular context (e.g. sentence), and 0 meaning it is absent.
The output layer also consists of one bit per vocabulary word. This represents the word that is the subject of the context specified in the input layer. For each sample, only one output (the target word) will be 1. All others will be 0.
The middle (i.e. hidden) layer of the Neural Network has one neuron for each dimension in the resulting word vector. Figure 2 below illustrates such a Network.
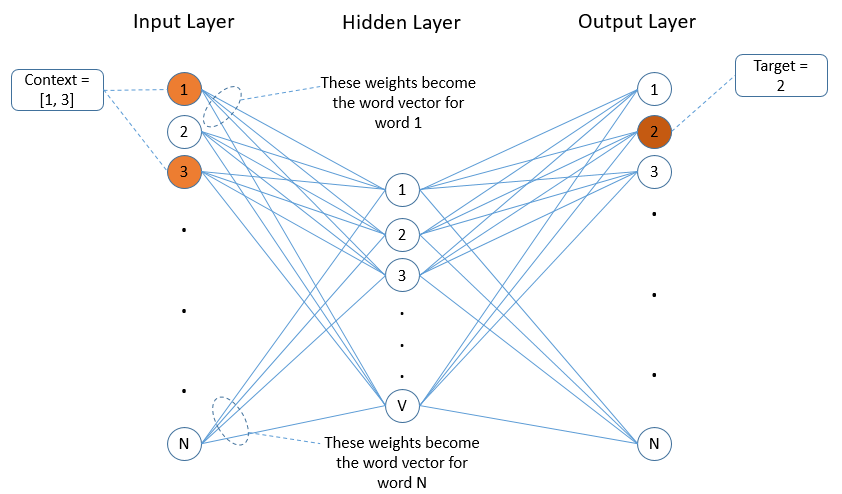
What we will do is train the Neural Net to predict the probability of finding a word in a sentence given the other words in the sentence.
So if I start with a sentence: “a dog is an animal”, I train the Network for each word in the sentence using the context of the other words in the sentence.
So I end up with the following training samples:
- [dog, is, an, animal] -> a
- [a, is, an, animal] -> dog
- [a, dog, an, animal] -> is
- [a, dog, is, animal] -> an
- [a, dog, is, an] -> animal
As I train the NN with these samples, it learns to predict the probability of each word being the missing word (i.e. the target word) given a context. This is one valid embodiment of John Rupert Firth’s statement. “You shall know a word by the company it keeps.”.
Remember though that our goal is not to predict the probability of words, but to form Vectors with the characteristics described above.
How does this help us do that?
In a Neural Net, each layer is only dependent on the layer directly before it. Therefore, for the output layer to reflect the probability of a word being in a given context, the hidden layer needs to contain enough discriminatory information to accurately form the output.
Furthermore, in order for two words to have similar output probabilities for a given context, those words must have similar values in the hidden layer.
So that layer must contain weights that successfully discriminate the closeness of words — that is, they meet the needs of our word vectors. If we extract those weights, we have our vectors!
For those familiar with Deep Learning techniques, this is similar to the trick auto-encoders use to detect representations of the important features of images.
N-Grams
In linguistics, we learn that not all meanings are embedded within single word. It sometimes requires combinations of words to specify a given meaning.
For example the meaning of , “New York Times” is not directly related to the meaning of the words “new”, “york”, or “times”. None of those words individually imply a newspaper, publishing, or journalism.
Additionally, the order of words is frequently important to meaning. There is a big difference between “traffic light” and “light traffic”.
To handle these cases, we treat small phrases as single words. These phrase words are called N-Grams, where N is the number of words that make up the phrase.
A unigram (1-Gram) is a single word; a bigram (2-Gram) is a phrase word made up of two words; a trigram (3-Gram) is a three word phrase, and so on.
Generally, if we train the NN with trigrams, we also train with bigrams and unigrams.
These N-Grams become words in the vocabulary and are treated as any other word. So if we are using bigrams, our sentence “a dog is an animal” becomes “a dog is an animal _a_dog _dog_is _is_an _an_animal”. When the Neural Net is trained, the distribution of the bigrams as well as the unigrams is considered.
Note that for our simple sentence, the use of bigrams will probably not help, since none of the bigrams happened to encode a meaning that is different from that of the individual words. Bigrams would help significantly, however, for the sentence “an irish setter is a dog”. Neither “irish” nor “setter” captures the same meaning as “irish setter”.
Sentence Vectors
So far, we’ve talked about encoding a word’s meaning into a word vector, but how do we deal with the meaning of larger collections of text?
There are several different techniques for doing so.
I will describe the one currently used by the Text Vectors bundle. It is a fairly simple technique compared to others, but has been shown to perform very well and is quite efficient to compute. It is described in this paper [2].
To compute a vector that represents the meaning of a sentence, we just average the normalized vectors of the words in the sentence. It seems overly simplistic, yet works quite well, at least for reasonably sized sentences.
Note that there is no fixed definition of “sentence” used here. It only implies collections of words of size > 1. It could be used for phrases, sentences, or paragraphs.
However, this averaging approach also implies the blurring of the word meanings together to form the sentence meaning. There is a soft limit to how much of this blurring can occur before the meaning is lost. For example, if I tried to encode the meaning of the book Moby Dick by averaging the vectors of all the words in the book, I would lose most, if not all of the book’s meaning. I must confess, however, that even I was never able to comprehend the meaning of that book!
For normal length sentences, however, the technique is hard to beat.
The Text Vectors bundle, currently encompasses word and sentence vectors. Future releases may incorporate other techniques such as paragraph vectors, which are designed to handle longer segments of text.
Uses of Text Vectors
So what can we do with these vectors, once we generate them? New uses are actively being discovered, but here are some basic things you can do:
- We can learn synonyms and related words. Find the words most similar to a given word. This can be used for example to construct custom thesauri. It can be used for search. If I search for “dog breeds”, it can also return text with “canine varieties” that do not use the words “dog” or “breeds”. It can also be used for language translation where a word in one language can easily be matched to words in another language.
- We can map a never seen before sentence to one that we have already classified, and use that mapping to classify the new sentence.
- We can use text vectors directly as features in any Machine Learning mechanism, and mix it with numerical data to train the ML model. This allows unstructured text to be used as inputs to ML.
- We can detect anomalies, for example in surveys or tests by identifying answers that were the least related to the expected answers. If, for example, the question “What is your favorite type of pet” was answered “piston”, one could conclude that that is so far away from other answers that the question must have been misunderstood, or the answer was mistakenly applied to the wrong question.
- One surprising property of word vectors is the ability to solve analogies by doing simple arithmetic on the vectors. For example: Paris is to France as London is to ? can be solved by simply computing: vec(‘Paris”) – vec(“France”) + vec(“London”). That is, if I subtract the meaning of France from the meaning of Paris, I should be left with a concept something akin to “Capital_of”. By adding “London” to the concept of Capitol_of, I should end up very close to the vector for “United Kingdom” as well as the vector for “England”.
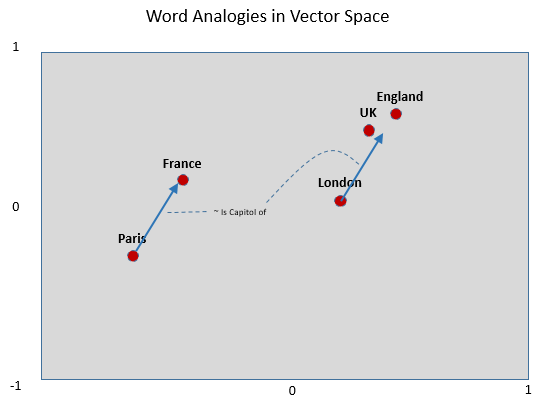
Note that most of these uses requires a large and comprehensive corpus in order to provide sufficient context.
Case Study
We ran a test case using publicly available (anonymous) data on legal violations committed across various states in the U.S. Somewhat surprisingly, very little structured data is available that describes these violations. Any of thousands of court clerks or other personnel within the judicial system can enter a violation description in a way that they find informative at the moment. These are then combined from all of the courts in the state to form an expansive mishmash of descriptions that are hard to correlate.
The problem is exacerbated by a number of factors:
- Many different personnel with different background and focus
- Different types of courts
- Frequent Typos / Misspellings
- Extensive use of non-standardized abbreviations
- Many different ways to describe any violation
- The terse nature of the descriptions are difficult to understand, even for people
In our test sample:
- We observed nearly one million unique violation descriptions
- In a given year, over 300,000 never seen before violation descriptions were observed
- Approximately 16,000 different words (unigrams) were used in the descriptions
Let’s look at some of the results:
- Training of the word and sentence vectors, with 1 million unique sentences (i.e. violation descriptions) takes about 40 minutes on a 20 node HPCC Cluster
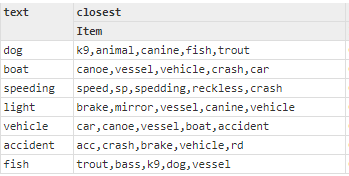
- We selected several words that were commonly encountered and asked for the closest words to those words. See results below. Note that when we asked for the closest words to “dog”, it found: Canine, K9, and Cat. Clearly the vectors successfully encoded meanings, and not just textual manipulations. For “accident”, it found not only a variety of abbreviations for accident, but also “crash” and “scene” which are closely related terms.
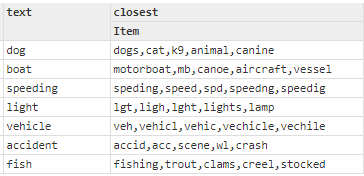
- We limited the vocabulary to a small number of words and asked for the closest words to a set of selected words. In this test, we wanted to see which words were considered close to each target word as well as which ones were most distant. We wanted to verify that all of the words we considered close were found to be closer than those we considered distant. See results below. Note the subtlety of some of the distinctions. Even with very limited contextual information in the violation descriptions, fish and trout were found to be closer to dog than any of the inanimate choices. Notice that car, canoe, vessel, and boat were the closest things to vehicle — all modes of transport.
- We asked for the least closest word among a set of words (i.e. “one of these things is not like the other”). This is the anomaly detection case described above. The choices were: dog, cat, canine, vehicle, terrier, animal, reckless. We asked for the two least similar words, and it identified the two non-animal words as the standouts.

- We asked for the two closest sentences to a given list of sentences that were never seen in the training data.. Note that sentences were almost always mapped to a reasonable result. Some were just permutations of the test sentence. Some used different spellings or abbreviations. Some were genuine semantic translations. For the last entry, we included one of the rare cases where the mapping does not appear reasonable. We believe that this is due to a very unusual violation with very little precedent in the training data. Note the similarity measurement for that entry is much lower than the other entries. This indicates that there were no really close results. This is a handy indicator that there are no close matches. These types of cases can be identified by using a threshold on similarity. That could indicate, for example, that this match should be rejected and manually examined.

- We had a hard time thinking of analogies that would make sense given our Corpus that lacks a lot of descriptive context. Here is one we tried, with somewhat reasonable results.

TextVectors Bundle
The TextVectors Bundle is a fully-parallelized version of the Sent2Vec algorithm described in [2]. It also has several enhancements providing superior results and ease of use. We expect to provide additional text vectorization algorithms and other extensions in the future. It is considered a production ready bundle, having gone through an extensive test cycle.
Parallel Neural Network Training
TextVectors is written in ECL with embedded C++ for maximum distributed performance.
The vectors are produced using a purpose-optimized, parallel Neural Network using Synchronous Batch Gradient Descent. That means that each node processes a different small portion (i.e. batch) of the training data (i.e. sentences in the Corpus) against the full set of Neural Network weights. After each node processes its batch, the nodes synchronize the weights by applying the set of updates from all nodes to the weights from the previous batch. In this way, all cluster nodes can be effectively utilized without the weights diverging too far from node to node.
The Neural Networks employed by TextVectors can be very large. For example, we have tested with a 100,000 word vocabulary and 200 length vector resulting in 40 million weights.
The TextVectors Neural Net uses a variety of optimizations to allow fast performance even at these scales.
One challenge with parallelized Neural Nets is to choose the right batch size. If the batch size is too small, the algorithm will run very slowly and spend most of its time synchronizing weights. If the batch size is too large, the nodes may fight each other with conflicting weight updates. When this occurs, the network may fail to converge, or may require very many “epochs” (i.e. iterations through the training data) to converge.
TextVectors provides a novel mechanism for automatically adjusting the batch size so that the user does not need to worry about it.
Another challenge is knowing how many iterations to run before training is considered complete. The number of iterations needed for effective training is dependent on a wide number of variables such as vocabulary size, average sentence length, and other training parameters. TextVectors solves this by training toward a fixed Loss value. Loss is another word for error-level. So a loss of 0.0 would imply that the Neural Network exactly predicts the probability of a word given its context. This is never achievable in practice. A loss of 5%, on the other hand, is achievable and usually results in high-quality vectors.
TextVectors allows you to set the target loss level and will usually work well with the default setting (5% loss). It will continue to train until the loss level is achieved or it can no longer improve on the loss.
These automatic features can be disabled by explicitly setting the number of iterations or the batch size.
Other Unique Features
Unknown Word Handling — When a new sentence is presented, it attempts to find the vector for each word in that sentence. If a new word is seen (never encountered in the training data), we would normally drop that word. With this feature, TextVectors will attempt to find the closest word in the vocabulary (typographically) using edit-distance rather than dropping the word. This is especially useful when there are frequent typos (e.g., maps “caninies” to “canines”) in the data. Additionally, this feature includes a special case for numbers. Typographically, the number 10 is only 1 edit away from 11, but is also only one edit from 910. Therefore we utilize numeric distance whenever we encounter unseen numeric text. It will, for example map 0000555 to 555 or 555 to 556.
Syntactic Mapping — In some applications, we may want to map sentences syntactically, but not semantically. Syntactic mapping will, for instance identify matching sentences regardless of word order, typos, or misspellings, but will not map word meanings. This is handy for more structured tasks such as business names, product names, etc. where someone may enter the wrong word order (e.g. “high performance cluster computing”) or may have a typo in their text, but where we don’t want to inadvertently map to an equivalent semantic meaning (e.g. “tall presentation gathering computer”). This is selected by simply setting the target loss to 1 (i.e. not training the Neural Network) and using the default (random) values that each vector is initialized to. The process of Unknown Word Handling combined with vector averaging will typically produce good results for the above types of usage.
Tutorial
Installation
- Be sure HPCC Systems Clienttools is installed on your system.
- Install HPCC Systems ML_Core
From your clienttools/bin directory run:ecl bundle install https://github.com/hpcc-systems/ML_Core.git
- Install the HPCC Systems TextVectors bundle. Run:ecl bundle install https://github.com/hpcc-systems/TextVectors.git
Note that for PC users, ecl bundle install must be run as Admin. Right click on the command icon and select “Run as administrator” when you start your command window.
Using TextVectors
Note that a sizeable Corpus is needed in order for TextVectors to produce meaningful results. It is difficult to construct a useful demonstration without such a Corpus. This section illustrates the mechanisms, but does not provide a real Corpus. You will need to replace the placeholder “sentences” with the set of sentences from your Corpus.
// Import the TextVectors module
IMPORT TextVectors AS tv;
// Import the Types TextVectors Types module
IMPORT tv.Types;
// Our input will be a list of sentences in Types.Sentence format.
// We just use some dummy sentences here. Needs real data.
Sentence := Types.Sentence;
// Note that capitalization and punctuation are ignored.
trainSentences := DATASET([{1, 'Dogs make good pets.'},
{2, 'My cat scratched my dog.'},
{3, 'His dog ate the mailman.'}], Sentence);
// Create a SentenceVectors instance. Use default parameters.
// Note that there are many parameters that can be set here, but all
// are optional and default values usually work.
sv := tv.SentenceVectors();
// Train and return the model, given your set of sentences
model := sv.GetModel(trainSentences);
// We could persist this model and use it later, but we're just
// going to use it in place.
// First lets define some words and sentences for testing.
Word := Types.Word;
testWords := DATASET([{1, 'dog'}, {2, 'cat'}, {3, 'sawmill'}, {4, 'piston'}],
Word);
testSents := DATASET([{1, 'My dog is the best'},
{2, 'My cat's not bad either'}], Sentence);
// Get the word vectors for the test words.
wordVecs := sv.GetWordVectors(model, testWords);
// Get the sentence vectors for the test sentences.
sentVecs := sv.GetSentVectors(model, testSents);
// Find the 3 closest words to each test word
closestWords := sv.ClosestWords(model, testWords, 3);
// Find the two closest sentences for each test sentence
closestSents := sv.ClosestSentences(model, testSents, 2);
// Find the 1 word that stands out from the rest.
leastSim := sv.LeastSimilarWords(mod, testWords, 1);
// Try an analogy of the form A is to B as C is to ?
// In this case: dog is to puppy as cat is to ?
// This could work, with a rich enough Corpus.
// Return the closest 2 solutions.
result := sv.WordAnalogy(model, 'dog', 'puppy', 'cat', 2);
// Get information about the training: Parameters used, Vocabulary
// size, Number of sentences in Corpus, etc.
trainingStats := GetTrainStats(model)
TextVectors provides a scalable, high-performance, and easy to use package for performing analysis, inference, and prediction on previously inaccessible textual data. It is able to automatically discern meanings of words and sentences without any input beyond the text itself. We are just beginning to uncover some of the potential applications of this technology, and we expect it to open vital new avenues of inquiry.
References
[1] Firth, J. R. 1957:11
[2] Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features” by
Matteo Pagliardini, Prakhar Gupta and Martin Jaggi (https://arxiv.org/abs/1703.02507)