ECL Tip – DISTRIBUTE
This ECL Tip spotlights the Enterprise Control Language (ECL) DISTRIBUTE function. The ECL DISTRIBUTE function redistributes data across all nodes in a cluster. Using the DISTRIBUTE function can help prevent “cluster skew”, by distributing data evenly across all nodes. This function can be used on Thor or the ROXIE cluster.
For more information on the HPCC Systems platform architecture, please refer to the following link: Introduction to the HPCC Systems platform architecture.
Bob Foreman, a technical trainer at LexisNexis Risk Solutions, spotlighted the ECL DISTRIBUTE function and methods during HPCC Systems Tech Talk 23, as part of his monthly “ECL Tips.” Bob is a frequent contributor to our Tech Talks, and provides valuable information on programming with Enterprise Control Language (ECL).
In this blog, we:
- Discuss “Cluster Skew.”
- Introduce the ECL DISTRIBUTE function.
- Examine ECL DISTRIBUTE methods.
Cluster Skew
“Cluster skew” refers to a non-uniform distribution of records across nodes in a cluster, during the data refinery process. It results in an inefficient use of the nodes, which slows down the ECL process.
The following is an example of cluster skew.
Example:
In a 3 node training cluster with a 300 record recordset, the optimal distribution would be 100 records distributed on each node in the cluster. However, when we look at the numbers for this job, we see a skew of 200% and -100%. This means that one node is doing 200% more than it should be. All 300 records are on that node, and the other two nodes have no data.
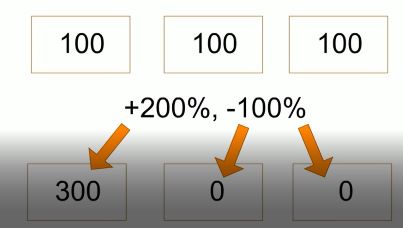
In a distributed data system, when we encounter cluster skew, the solution is to use the DISTRIBUTE function.
Distribute Function
DISTRIBUTE (recordset, expression)
- recordset – The set of records to distribute.
- expression – An expression that specifies how to distribute the recordset, usually using one of the HASH functions for efficiency.
The DISTRIBUTE function distributes records from the recordset across the nodes of the target cluster based on the specified expression. All records for which the expression evaluates the same end up on the same nodes.
Following the distribution process, all subsequent operations should be optimized by using LOCAL operation.
There are four types of DISTRIBUTE methods:
1. Random
2. Expression
3. Index
4. Skew
DISTRIBUTE Methods
1. “Random” DISTRIBUTE
DISTRIBUTE (recordset)
This form redistributes the recordset “randomly” across the nodes, but without the disadvantages the RANDOM() function could introduce. This is functionally equivalent to distributing by a hash of the entire record.
2. “Expression” DISTRIBUTE
DISTRIBUTE (recordset, expression)
“Expression” DISTRIBUTE is the most common form. This from redistributes the recordset based on the specified expression, typically one of the HASH functions. The HASH function is used as an expression to create a hash value from the list of fields passed to the hashing function in your DISTRIBUTE expression. Only the bottom 32-bits of the expression value are used, so either HASH or HASH32 are the optimal choices. Records with the same expression value end up on the same node. DISTRIBUTE implicitly performs a modulus operation if an expression value is not in the range of the number of nodes available. If the MERGE option is specified, the recordset must have been locally sorted by the sorts expressions. This avoids resorting.
For more information on the MERGE option, please refer to the HPCC Systems ECL Language Reference Manual.
The “‘expression” DISTRIBUTE method involves using HASH functions as an expression, so let’s take a closer look at these functions.
HASH Functions
The Hash function takes a group of expressions, typically just a list of fields in the recordset (called a key) and derives a 32 bit value (called the hash value or hash). The hash value is representative of the original data.
Below is a list of HASH functions:
HASH(expressionlist) – The HASH function returns a 32-bit hash value derived from all the values in the expressionlist. Trailing spaces are trimmed from string (or UNICODE) fields before the value is calculated (casting to DATA prevents this).
HASH32(expressionlist) – The HASH32 function returns a 32-bit FNV (Fowler/Noll/Vo) hash value derived from all the values in the expressionlist. This uses a hashing algorithm that is faster and less likely than HASH to return the same values from different data. Trailing spaces are trimmed from string (or UNICODE) fields before the value is calculated (casting to DATA prevents this).
HASH64(expressionlist) – The HASH64 function returns a 64-bit FNV (Fowler/Noll/Vo) hash value derived from all the values in the expressionlist. Trailing spaces are trimmed from string (or UNICODE) fields before the value is calculated (casting to DATA prevents this).
HASHCRC(expressionlist) – The HASHCRC function returns a CRC (Cyclical Redundancy Check) value derived from all the values in the expressionlist.
HASHMD5(expressionlist) – The HASHMD5 function returns a 128-bit hash value derived from all the values in the expressionlist, based on the MD5 algorithm developed by Professor Ronald L. Rivest of MIT. Unlike other hashing functions, trailing spaces are NOT trimmed before the value is calculated.
- expressionlist – A comma-delimited list of values.
***DISTRIBUTE only uses the lower order 32 bits of any HASH function used as its expression.
Example:
Domains_Dist := DISTRIBUTE(Domains_Seq, HASH(zip, TRIM(prim_name), prim_range)); YP_Cont_Dist := DISTRIBUTE(YellowPages_Contacts,HASH32(TRIM(company_name),TRIM(lname), zip));
Now that we’ve examined HASH functions, let’s continue the discussion of DISTRIBUTE Methods.
DISTRIBUTE Methods (continued)
3. “Index-based” DISTRIBUTE
DISTRIBUTE(recordset, index [, joincondition ])
This form redistributes the recordset based on the existing distribution of the specified index, where the linkage between the two is determined by the joincondition. Records for which the joincondition is true will end up on the same node.
- index – The name of an INDEX attribute definition, which provides the appropriate distribution.
- joincondition – Optional. A logical expression that specifies how to link the records in the recordset and the index. The keywords LEFT and RIGHT may be used as dataset qualifiers for fields in the recordset and index.
4. “Skew-based” DISTRIBUTE
DISTRIBUTE(recordset, SKEW( maxskew [, skewlimit ]))
This form redistributes the recordset, but only if necessary. The purpose of this form is to replace the use of DISTRIBUTE(recordset,RANDOM()) to simply obtain a relatively even distribution of data across the nodes. This form will always try to minimize the amount of data redistributed between the nodes.
- SKEW – Specified the allowable data skew values.
- maxskew – A floating point number in the range of zero (0.0) to one (1.0) specifying the minimum skew to allow (0.0=10%).
- skewlimit – Optional. A floating point number in the range of zero (0.0) to one (1.0) specifying the minimum skew to allow (0.0=10%).
The skew of a dataset is calculated as:
MAX(ABS(AvgPartSize-PartSize[node])/AvgPartSize)
If the recordset is skewed less than maxskew then the DISTRIBUTE is a no-op. If skewlimit is specified and the skew on any node exceeds this, the job fails with an error message (specifying the first node number exceeding the limit), otherwise the data is redistributed to ensure that the data is distributed with less skew than maxskew.
***The “skew-based” DISTRIBUTE method is used most commonly.
Summary
In this blog, we discussed “cluster skew,” defined the ECL DISTRIBUTE function, discussed DISTRIBUTE methods, and examined the HASH function.
More information about the ECL DISTRIBUTE function can be found in the HPCC Systems ECL Language Reference Manual .
About Bob Foreman
Since 2011, Bob Foreman has worked with the HPCC Systems technology platform and the ECL programming language, and has been a technical trainer for over 25 years. He is the developer and designer of the HPCC Systems Online Training Courses, and is the Senior Instructor for all classroom and WebEx/Lync based training.
If you would like to watch Bob Foreman’s Tech Talk video, “ECL Tip – DISTRIBUTE Function,” please use the following link:
Acknowledgements
A special thank you goes to Bob Foreman and Richard Taylor for their valuable contributions.