ECL Tips – A Tiny Trove of TABLE Tidbits
 This ECL Tip spotlights the Enterprise Control Language (ECL) TABLE function. The TABLE function is a versatile tool for ETL (extract, transform, load) operations, and was one of the first ECL statements available, well before the family of TRANSFORM functions.
This ECL Tip spotlights the Enterprise Control Language (ECL) TABLE function. The TABLE function is a versatile tool for ETL (extract, transform, load) operations, and was one of the first ECL statements available, well before the family of TRANSFORM functions.
Bob Foreman, a technical trainer at LexisNexis Risk Solutions, spotlighted the ECL TABLE function during HPCC Systems Tech Talk 22, as part of his monthly “ECL Tips.” Bob is a frequent contributor to our Tech Talks, and provides valuable information on programming with Enterprise Control Language (ECL).
In this blog, we:
- Discuss ECL TABLE function basics and fundamentals
- Examine data aggregation using the ECL TABLE function
- Provide code examples for the ECL TABLE function
ECL TABLE Basics
The TABLE function is the most commonly-used data aggregation function in ECL. Data aggregation is the process where raw data is gathered and expressed in summary form for analysis. Following are a few of the capabilities of the ECL TABLE function.
An ECL TABLE function can:
- Expand an existing recordset. – This consists of taking a recordset of fields and adding new fields, and enhancing current data.
- Reduce an existing recordset. – One of the fundamentals of ECL is to work only with essential data.
- Transform or standardize an existing recordset.
- Create Cross Tabulation (Grouped By) Reports – These reports are a great way to profile and analyze data.
Now that we’ve described some of the basic characteristics, let’s discuss the ECL TABLE function in more detail.
TABLE Function Fundamentals
The TABLE function is similar to OUTPUT, but instead of writing records to a file, it outputs those records into a new memory table (a new dataset in the HPCC Cluster). The new table inherits any implicit relationality the recordset has unless an expression is present. The new table is temporary, and exists only while the query is running.
TABLE(recordset, format [,expression [,FEW|MANY] [, UNSORTED]] [,LOCAL][,KEYED])
recordset – The set of records to process.
format – The RECORD structure of the output records. Fields must have default values!
expression – The “group by” clause for Crosstab reports. Multiple comma-delimited expressions create one logical “group by” clause.
FEW – Indicates that the expression will result in fewer than 10,000 distinct groups.
MANY – Indicates that the expression will result in many distinct groups.
UNSORTED – Indicates you don’t care about the order of the groups.
LOCAL – Specifies independent node operation.
KEYED – Specifies activity is part of an index read operation
MERGE – Optional. Specifies that results are aggregated on each node and then the aggregated intermediaries are aggregated globally. This is a safe method of aggregation that shines particularly well if the underlying data was skewed. If it is known that the number of groups will be low then, FEW will be even faster; avoiding the local sort of the underlying data.
Here is an example of building a vertical slice of a recordset using the TABLE function.
TABLE example (vertical slice)
Below, we have a table statement “Per_Name_State:= TABLE(Persons, Layout_Name_State)” that references the “Persons” recordset.
//"vertical slice" TABLE: Layout_Name_State:= RECORD Persons.LastName; Persons.FirstName; Persons.State; END;
Per_Name_State:= TABLE(Persons, Layout_Name_State);
No further parameters are required because it is simply reducing from the larger “Persons” recordset to a three-field table.
The vertical slice can also be expanded. In this example, we have the “seq” field defaulted to zero and the “string” field defaulted to “Bob.” When there is no distinct value for a field that is being added, a default value must be entered, as shown in the definition, “seq:=0;”.
Layout_Name_State:= RECORD seq:= 0; mynewstring:= ‘Bob’ Persons.LastName; Persons.FirstName; Persons.State; END;
The TABLE function can also be used for the purpose of data aggregation.
ECL: Aggregation via TABLE
TABLE is the most commonly-used data aggregation function in ECL. Data aggregation is a process in which information is gathered and expressed in summary form, for the purpose of simplification and analysis.
The following defines how the TABLE function is used for data aggregation:

GROUP Keyword
The GROUP keyword replaces the recordset parameter of any aggregate function used in the record structure of a TABLE definition where a GROUP by expression is present. Note that the GROUP keyword is not the same as the GROUP function.
The GROUP keyword is only used to generate a Crosstab report (set of statistics) on a recordset. The GROUP function provides similar functionality. A Crosstab report shows the relationships between three or more query items. Crosstab reports show data in rows and columns with information summarized at the intersection points.
Crosstab Report Code Examples:
In this query a Crosstab report is generated by state and gender. The report includes a COUNT of how many records are in each group.
// Create a crosstab report for each sex in each state R := RECORD Person.per_st; Person.per_sex; COUNT(GROUP); END; PerState:= TABLE(Person,R, per_st, per_sex);
The Crosstab report for this query returns a COUNT of the number of people in each state.
//"crosstab report" TABLE: Layout_Per_State:= RECORD Person.state; StateCount:= COUNT(GROUP); END; Per_Stat:= TABLE(Person, Layout_Per_State, per_st);
ECL TABLE can be used to parse and transform information in a table. Let’s take a look at TABLE as a transforming tool.
The Terrific Transforming TABLE
The table below contains a long string of information: the book of the Bible, the chapter, verse, and the actual text.

The code below uses TABLE to parse and transform the information in the original table.
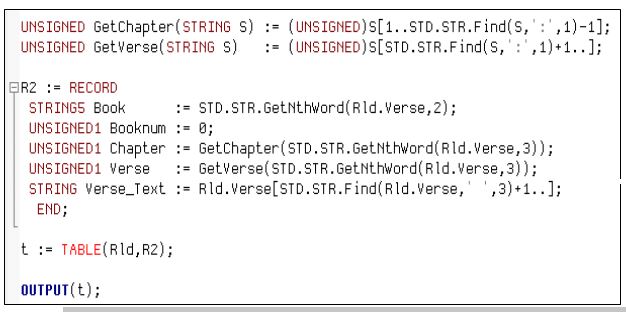
- Local functions GetChapter and GetVerse along with STRING are applied to the table.
- The field Booknum is initialized to “0” because there is no book number in the input record.
- The remainder of the verse information is parsed starting at a specific position in the string using the Find function, and parsing out through the remainder of the string.
The result of the parsing of the strings is that the original table is transformed into a table with the following fields: book, booknum, chapter, verse, verse_text. This makes the information much easier to read and understand.

Next, let’s look at using the TABLE function with PERSIST.
In-Memory Datasets using TABLE and PERSIST
The TABLE function can also be used with PERSIST. Saving a table as a PERSIST file allows the transformed table to be saved as a meta file on disk on the cluster to be used for future needs. The meta file only needs to be rebuilt if the underlying code or data has changed, or, the PERSIST EXPIRE parameter has exceeded it’s time limit set.
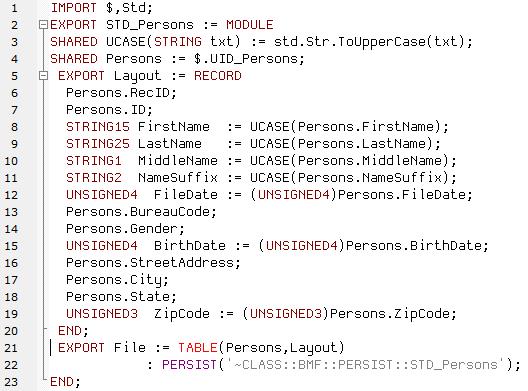
In this code example, the “Persons” recordset is used to create a table. In the table four strings are converted to UPPERCASE and standardized: FirstName, LastName, MiddleName, NameSuffix. The “FileDate” field is also standardized. The original string format for the “FileDate” field in the “Persons” recordset is converted from STRING8 to UNSIGNED4. The benefit of converting this field is that more date and time functions in the ECL standard function library can be applied. The table is exported and wrapped inside of a module, and subsequently saved as a PERSIST file.
Normally a table is created in memory and the area of memory is cleared when the code is finished. If you want to use this information as you move forward in your transformation of data, you can save it as a PERSIST file. The information will be stored globally for later use. For more information on PERSIST, see the HPCC Systems ECL Language Reference Manual. There is also an interesting blog on PERSIST that can be accessed via the following link: ECL Favorite Feature: PERSIST.
This code results in the output table below, with all names in uppercase.

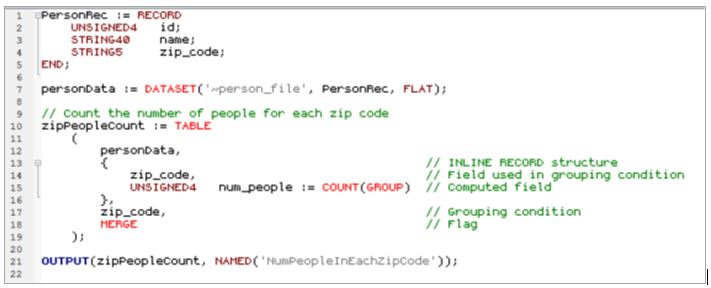
The final example shows code for creating an inline Crosstab report.
Inline Crosstab Report example
In this code example an inline Crosstab report is generated. The Crosstab report for this query returns a COUNT of the number of people in each zip code. The MERGE attribute is used to improve the performance of the Crosstab report results.
As stated earlier, the TABLE function existed before TRANSFORM functions. As a bonus ECL tip, let’s compare one of the most commonly used TRANSFORM functions (PROJECT) to the TABLE function.
TABLE VS. PROJECT
The TABLE and PROJECT functions are both used to transform data. The main difference between TABLE and PROJECT is that the PROJECT function has a TRANSFORM structure that allows records to be filtered, based on specific conditions; and incremental COUNTER values to be added as an additional field in the RECORD structure.
There are a number of ways to filter records within the TRANSFORM structure. One way to filter records is through the use of SKIP. The SKIP attribute in a TRANSFORM indicates when a record should not be generated into the output.

In this code example a TRANSFORM structure is defined to add a new “Sequence” field with incremental values only for the odd records (i.e., by skipping the even records).
For more information on SKIP, refer to the HPCC Systems ECL Language Reference Manual. The following blog is also recommended: Why SKIPing can be bad for your query.
SUMMARY
One of the main functions of the TABLE function is to extract data from a large dataset and organize the information into usable form. The examples in this blog demonstrate the use of the TABLE function for vertical slices, data aggregation, Crosstab reports, parsing, and transformation.
More information about the ECL TABLE function can be found in the HPCC Systems ECL Language Reference Manual.
About Bob Foreman
Since 2011, Bob Foreman has worked with the HPCC Systems technology platform and the ECL programming language, and has been a technical trainer for over 25 years. He is the developer and designer of the HPCC Systems Online Training Courses, and is the Senior Instructor for all classroom and WebEx/Lync based training.
If you would like to watch Bob Foreman’s Tech Talk video, “ECL Tip – A Tiny Trove of TABLE Tidbits,” please use the following link:
Acknowledgements
A special thank you goes to Bob Foreman for guidance and valuable contributions to this blog post.