Introducing the HPCC Systems Machine Learning Preprocessing Bundle

Vannel Zeufack joined the HPCC Systems Intern program in 2020 as a second year Masters Student at Kennesaw State University. The purpose of the preprocessing bundle is to provide some tools to perform some of the basic tasks of data preparation for use with various machine learning algorithms. The tools have been created in ECL and added to the HPCC Systems Machine Learning Library in the form of a bundle.
The current version of this bundle includes modules and functions allowing you to easily handle categorical features, scale your data and split it in various ways.
In this blog, Vannel Zeufack introduces each module and the functions provided.
Handling Categorical Features
Currently, there are two modules for handling categorical features, LabelEncoder and OneHotEncoder. These are described below with ECL code examples of how to use them.
LabelEncoder
LabelEncoder allows the conversion of categorical feature values into unique numbers in the range and is illustrated in the following diagram:
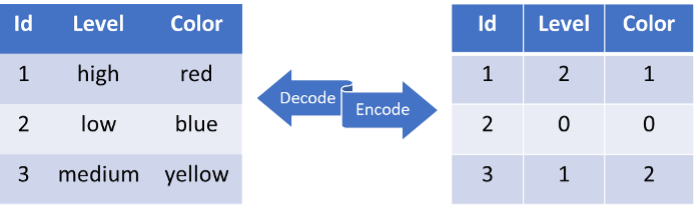
This module includes four functions GetKey, GetMapping, Encode and Decode which are described in more detail below.
GetKey(baseData, featureList)
This function computes the labelEncoder key. Encoding and decoding are done based on a key. The key stores the categories of each categorical feature in baseData.
- baseData is the data from which the categories of each feature in featureList are extracted.
- featureList is used to provide the names of the categorical features. For this parameter, a dataset of SET OF STRINGs is expected. Each SET OF STRING in the record structure must be identified by the name of a categorical feature. When constructing the featureList, the categories of some features for which you want to enforce the ordering must be provided
GetMapping(key)
This function gets the mapping between the categories of each feature in the key and the values assigned to them.
Encode (dataToEncode, key)
This function converts the values of the categorical features into numbers according to the key mapping. dataToEncode is the dataset to encode and can be any record-oriented dataset. key is the key generated through the GetKey function or has been manually built.
If an unknown category (i.e. a category not included in the key) is found, it is encoded to -1.
Decode (dataToDecode, key)
This function converts the values of the categorical features back into labels according to the key mapping. dataToDecode is the dataset to decode and can be any record-oriented dataset. key is the key generated through the GetKey function or has been manually built.
An unknown category (-1) is decoded to an empty string.
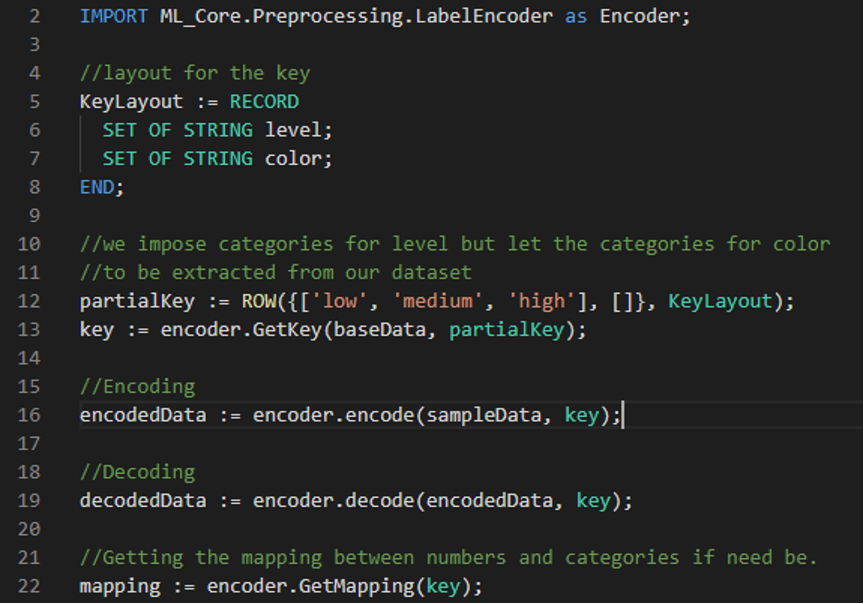
ECL Code Example
This code example shows the ECL required to use the LabelEncoder and the functions included:
OneHotEncoder
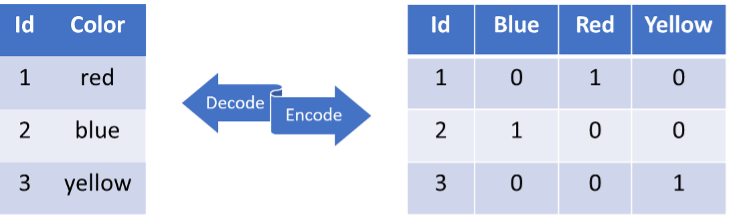
OneHotEncoding allows the conversion of categorical features into new binary features where a 1 indicates the presence of a value and 0 indicates its absence. The OneHotEncoder module has a constructor and 3 functions:
- GetKey
- Encode
- Decode
The following diagram illustrates how OneHotEncoding works:
OneHotEncoder(baseData, featureIds, Key)
The OneHotEncoder may be initialized either by passing the parameters baseData and featureIds, or by simply passing it a precomputed Key.
baseData is a NumericField dataset from which the categories listed in featureIds (SET OF UNSIGNED) are extracted.
GetKey()
This function gets the mapping between the features listed in featureIds and their respective categories.
Encode(dataToEncode)
This function performs OneHotEncoding on the given data. An unknown category is encoded to all zeros.
Decode(dataToDecode)
This function reverts the encoded data to their original values. If a value has been encoded to all zeros, it will be decoded to -1.
ECL Code Example
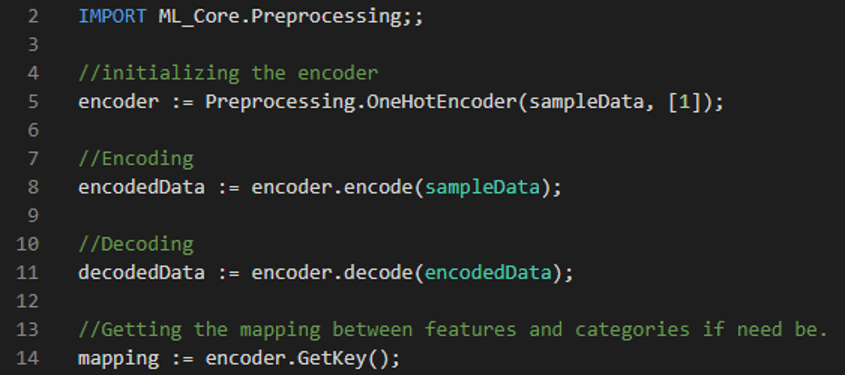
Using the Scaling modules and function
Currently, there are two modules for scaling, StandardScaler and MinMaxScaler. There is also a function for scaling, Normaliz. These are described below, including ECL code examples showing how to use them.
StandardScaler & MinMaxScaler
Standard scaling allows you to scale each feature such that they have a zero mean and standard deviation equal to 1. MinMaxScaler allows to scale the data in some range (default = [0,1]).
Constructors
The constructors for StandardScaler and MinMaxScaler are:
- StandardScaler(baseData, key)
The standard scaler could be initialized either by passing it baseData or a precomputed key. - MinMaxScaler(baseData, lowBound = 0, highBound = 1, key)
The MinMaxScaler can be initialized either by passing it baseData, lowBound (default = 0) and highBound (default = 1) or by passing only a precomputed key.
GetKey()
This function gets the scaler’s key. The StandardScaler key contains the means and standard deviation of each feature in baseData. The MinMaxScaler key contains the minimums and maximums of each feature in baseData.
Scale(dataToScale)
This function scales the given data and returns the scaled data.
Unscale(dataToUnscale)
This function reverts the scale operation.
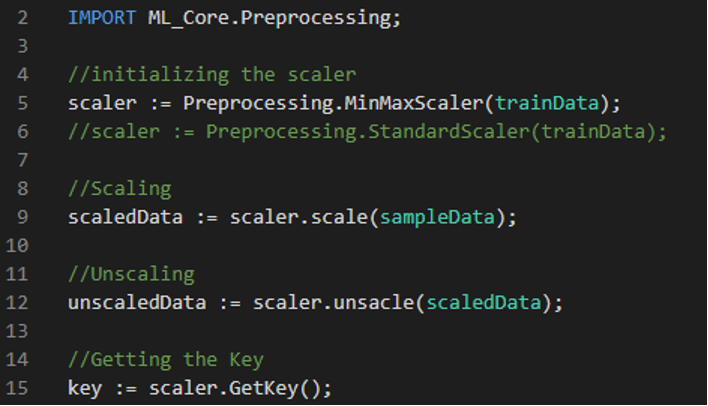
ECL Code Example
The following example shows ECL code using the scaling modules:
Using the Normaliz data splitting function
The Normaliz function scales in one of the following ways:
- Following the L1 norm, where every value is divided by the sum of absolute values of elements of its row
- Following the L2 norm, where every value is divided by the square root of sum of squares of elements of its row
- Following the L-infinity norm, where every value is divided by the maximum absolute value of elements of its row
This function takes the following parameters:
Normaliz (dataToNormalize, norm)
The first parameter is the data you wish to normalize and the second specifies the norm to use (default = “l2”).
Dataset Splitting
Currently, there are two dataset splitting functions, Split and stratifiedSplit. These are described below, including ECL code examples showing how to use them.
Split and StratifiedSplit
These functions split datasets into training and test sets.
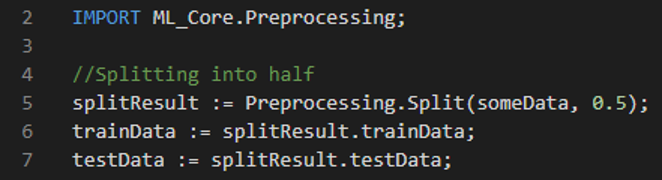
Split (dataToSplit, trainSize, testSize, shuffle)
To perform a simple split, provide either the trainSize or the testSize which are values in the range (0, 1). The shuffle parameter is a Boolean variable based on whether the data would be shuffled or not before splitting. The default value is set to False.
StratifiedSplit (dataToSplit, trainSize, testSize, labelId, shuffle)
StratifiedSplit splits the data while maintaining the proportions of a given feature.
For example, if your label feature has two values Yes and No with proportions 30% and 70%, using a stratified split will keep those proportions in both the training and test data.
When compared to the Split function, notice that StratifiedSplit has an extra parameter, labelId, which is the id of the field whose proportions must be maintained after splitting.
ECL Code Example
The following example shows ECL code illustrating the StratifiedSplit function:
How to install the HPCC Systems Preprocessing Bundle
The Preprocessing Bundle will be included into the ML_Core library. You can read about how to install the ML_Core library from. After installation the Preprocessing Bundle could be accessed through the following import:
IMPORT ML_Core.Preprocessing;
You can access the beta version of the Preprocessing bundle at https://github.com/vzeufack/ML_Core.
Future Development
The current version of the preprocessing bundle allows you to handle categorical features (LabelEncoder, OneHotEncoder), scale (MinMaxScaler, StandardScaler, Normaliz) and split data into training and test sets (Split, StratifiedSplit), which will help developers to speed up the data preparation of phase of Machine Learning projects undertaken on the HPCC Systems platform.
Future improvements will include the addition of more modules, such as an impute module for handling missing values. If you have any suggestions for new features and improvements to this bundle that would make it easier for you or others to preprocess your ML data, contact us or add a request into the HPCC Systems JIRA issue tracker.
More about this 2020 intern project
As well as this blog, there are some additional resources you can use to find out more about Vannel’s contribution to our open source project:
- Tech Talk Presentation Sept 2020
- Technical Poster Presentation 2020
- Vannel’s weekly blog journal about his project and internship experience
Vannel Zeufack was a returning HPCC Systems intern having joined the program for the first time in 2019. During his first internship withHPCC Systems, he developed a KMeans-based anomaly detection system applied to network systems’ log files. You can find out more about this project by watching his Tech Talk presentation. He also entered a poster into our 2019 Technical Poster Contest, where he placed third. His 2019 weekly Blog Journal also provides details about the progress made on his project as well as his HPCC Systems internship experience.
We thank Vannel for the contributions he has made to the HPCC Systems open source project over the last 2 years. These completed projects will be of huge benefit to community users who are using HPCC Systems Machine Learning.
We also thank his mentors, our LexisNexis RSG colleagues Lili Xu (Software Engineer III), Arjuna Chala (Senior Director, HPCC Systems Solutions Lab ) and Roger Dev (Senior Architect) who guided and supported Vannel as he worked on these successful machine learning related intern projects.
Vannel joins DataSeers
Vannel graduated with a Masters in Computer Science in 2020 and is now working as an ETL Developer with our business partners, DataSeers. DataSeers is an Atlanta-based FinTech company operating in the banking and payments space.
