Leveraging and evaluating Kubernetes support on Microsoft Azure with the HPCC Systems Cloud Native Platform

Yash Mishra is a Masters student studying Computer Science at Clemson University. He is a member of Dr Amy Apon’s research team which carries out research on Big Data systems, focusing on optimizations and improvements at both the data and network layers. HPCC Systems is a sponsor of their Data Intensive Computing Lab and Yash was introduced to HPCC Systems as a result of attending their Cloud Computing Architecture class
Yash has been involved in identifying different configuration options to deploy HPCC Systems on the commercial cloud. Last year, he worked on a project looking at auto-provisioning HPCC Systems on AWS and entered a poster illustrating this work into our 2019 Technical Poster Contest (View Poster / Read Extract). More recently, he has moved on to using HPCC Systems on Microsoft Azure and spoke about deploying onto this cloud provider using our bare metal version in our January 2020 Tech Talk Series (Watch Recording / View Slides).
Yash’s 2020 intern project involves using our new Cloud native platform to leverage the Kubernetes support for HPCC Systems. He is also focusing on performance measurements, cost analysis, looking at various configuration options. This, along with his previous work, will provide a comparison of running the HPCC Systems bare metal version and the new K8 support of cloud native HPCC Systems on Microsoft Azure.

Yash’s mentor was Dan Camper. Dan has been with LexisNexis since 2014 and is a Senior Architect in the Solutions Lab Group. He has worked for Apple and Dun & Bradstreet and also ran his own custom programming shop for a decade. He’s been writing software professionally for over 35 years and has worked on a myriad of systems, using a lot of different programming languages.
In this blog, Yash takes us through the work he has completed during his internship, sharing his thought process and findings as he demonstrates the steps used to setup and use HPCC Systems on the Microsoft Azure Cloud platform.
******
Diving into the cloud-native path has been very interesting so far, with new challenges and solutions to find. In the new Kubernetes version of HPCC Systems, several things appear to be different than in the legacy version. HPCC Systems components are converted to pods, completely decoupling it from the node-level architecture. Pods run the system processes that communicate with other pods in the cluster.
Cost Considerations
The main focus of this project was to work with the Azure Kubernetes Service to deploy an HPCC Systems K8 cluster. Using the Azure pricing calculator, it was easy to customize the Azure infrastructure components for HPCC Systems K8 based on cost considerations for experimenting with sample data in the K8 environment. This includes, selecting the right type and specific number of Virtual Machines for the node-pool in K8s and identifying which storage option (from the currently supported storage technology) would suit better.
Unlike the legacy version, the K8 version supports replica-sets for pods. This lets HPCC Systems pods roll over to a new (replica) pod in case a running pod fails. This means working with kubectl and helm to manage the HPCC Systems K8 cluster, review deployment logs, navigate within pods to identify volume types and mount points, providing new values for helm charts to modify cluster configuration as needed.
Navigating the K8 cluster resources effectively, meant taking some time to familiarise myself with the new world of deployments with Kubernetes and helm as it was relatively new to me and different from my previous experience with the HPCC Systems bare metal platform. This helped with tackling some of the initial challenges using the K8 environment. One of the first steps was to fork and review the HPCC System helm charts repo to get an understanding of the orchestration of components. The helm examples provided a good starting point to start off tackling challenges with Kubernetes.
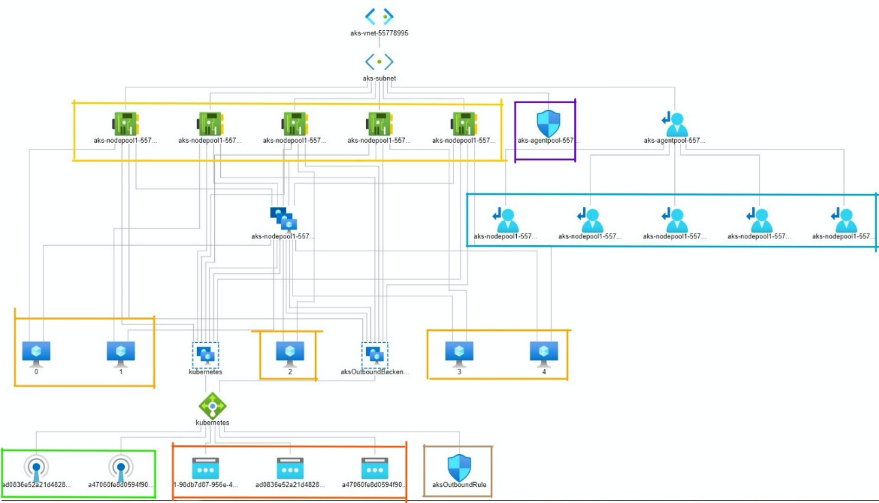
I took a look at mapping the new HPCC Systems architecture under the K8s deployment model, the underlying network topology on AKS looks like the figure below using the following key:
- At the very top is the virtual network that hosts the entire cluster
- Boxed in yellow are the 5 nodes in the VMSS node pool
- Boxed in orange are the 3 PV (persistent volume) storage mounted
- Boxed in purple is the Network security group associated with the virtual network
- Boxed in blue are the route tables associated
- Boxed in green are the health probes associated with the Kubernetes load balancer (green icon)
- Boxed in brown is the outbound rule associated with the load balancer
While small to mid-sized data may not take up a huge chunk of storage associated costs, working with Big Data incurs more costs depending on the size of data and the type of data disk being used in the underlying infrastructure. Compute and storage are two of the determining factors for costs (as shown in the figure below). As the size of data gets higher, an increase in storage costs and data-transfer costs are expected.
If there are different resource groups running different HPCC Systems K8 clusters, cost analysis provides logically isolated visualization for cluster costs in every resource group. For instance, in one of the resource groups it is clear to see which services cost more. The size of data is also a determining factor for real-time big sized data. Depending on the size of the data to be processed by Thor, the type of instance that best fits the budget can be chosen.
In the figure below, a K8 cluster in US East region was deployed, using Standard_DS2_v2 type general-purpose instance, which has 2 vCPU(s), 7 GB RAM and 14 GB Temporary Storage and costs $0.146/hr:
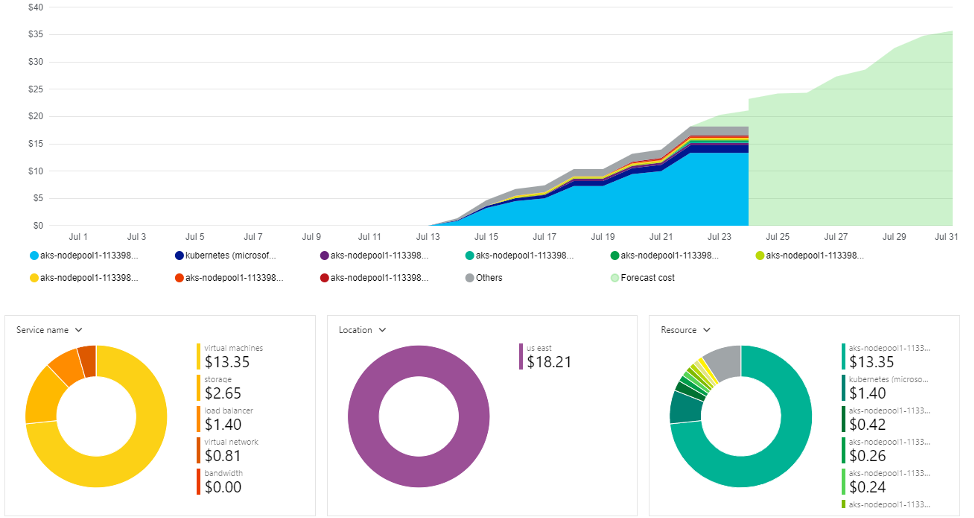
Note: Cloud costs vary by region. For example, Standard_D2s_v2 instance type costs $0.146/hour in the US East region, and costs $0.14/hr in West US region. Choosing a different region may be cheaper, but it would also impact the latency.
Handling Storage
For configuring storage in an HPCC Systems K8 environment, one challenge is to be able to persist data. One option is to create an AzureFile storage class through the corresponding Azure helm manifest. In this scenario, while the HPCC Systems storage classes (datastorage, dllstorage and dalistorage) can reference the persistent volume claim for AzureFile and execute ECL Workunits on the fly, it does not persist data at the moment. The idea is to make data persist longer than the helm chart by exploring alternative storage option like Azure Blob and comparing it with AzureFile storage. This is still a work in progress, coming soon in a future version, when the storage classes may also be extended to target Azure Data Lake storage.
Volumes Populated by a ConfigMap
Three storage accounts being used in HPCC Systems K8s. The HPCC Systems storage classes shown below, each have an associated storage account for corresponding persistent volumes:
- dataStorage
- dllStorage
- daliStorage
Each HPCC Systems storage class configured by persistent volume is referenced by persistent volume claim.
AzureFile represents an Azure File Service mount on the host and bind mount to the pod.
Azure storage class considerations for creating Persistent Volumes: Azure File | Azure Disk.
| Azure File | Azure Disk |
|---|---|
| Azure Files offers SMB access to Azure file shares.
It meets the requirement for shared data among dllStorage and dataStorage. |
|
| Challenge with using with HPCC Systems
Does not meet shared storage requirement for dataStorage and dllStorage classes. Azure Disks are mounted as ReadWriteOnce, so are only available to a single pod. For storage volumes that can be accessed by multiple pods simultaneously, use Azure Files. |
Encryption in K8s
| Encryption at Rest | Encryption in Transit |
|---|---|
| By default, all disks in AKS are encrypted at rest with Microsoft-managed keys. | https is supported between clients and the esp process, but at the moment it is not the default connection scheme. It does work but requires a bit of setup.
The HPCC Systems Cloud Native Platform is still under active development and changes are planned to make https the default. |
| Communication between cluster processes is not currently encrypted, however. | |
| Remote copy between clusters is also not encrypted at the moment. |
Landing Zone and Persistent Volume
As there is no landing zone in the K8s environment, another challenge is to continue finding workarounds to be able to get data in and out of the cluster. While this might take away the possibility to test an HPCC Systems K8 cluster with a real-time big sized data, generating synthetic data is an alternative solution to provide some level of performance testing in Kubernetes and comparing it with the legacy environment on Azure, from a proof-of-concept view. Implementing a more permanent solution for spraying data into the K8 environment is also a work in progress. Testing with various storage options on the cloud side for HPCC-K8 has been challenging but also very interesting at the same time as it provides the opportunity to think critically on how various cloud storage options work in a BigData platform.
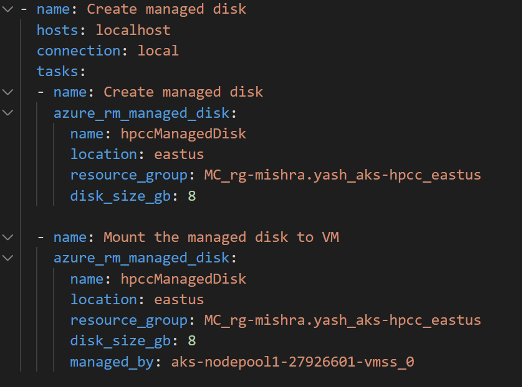
One potential solution for finding a workaround for data import was to create a separate managed data disk in the resource group and mount it to an existing node in the node-pool. While I got the disk attached and mounted to the desired spot in the K8 cluster, the persistent volume claim (PVC) object reference for the disk volume was missing. So, I created a new PVC for AzureDisk to test if the separately mounted disk worked, but this led to a few deployment errors. I am continuing to debug that and will update this blog with more information as it becomes available.
The figure below shows the snippet of the Ansible playbook I wrote to create, attach and mount the managed disk to the HPCC Systems K8 cluster node pool in the resource group:
Troubleshooting using the Service Map
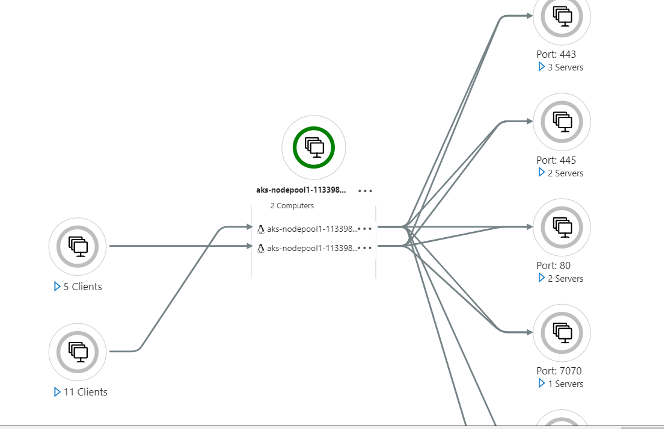
Upon successful deployment of the HPCC Systems K8 cluster on Azure and after working with the generated logs to troubleshoot pod issues and observing resource usage through kubectl, I routed some performance metrics through Azure Insights to get a visual representation of resource usage and monitoring. This also generates a Service Map which shows a network-map of the ports and services with which they communicate. While logs in K8 are ephemeral, this feature still provides fine-grained visual control, as long as the cluster is running.
For example, the figure below shows a Service Map from the HPCC Systems K8 cluster, running two nodes in the AKS node-pool. You can see the active ports and their corresponding service connections in the cluster. (The full service map, would have appeared too small to see on a screenshot and so the components have been enlarged and the rest of the figure has been trimmed, but it gives an idea of what it looks like and what to expect.)
Next Steps
Working hands-on on bleeding-edge technology has definitely been a great experience into the new deployment practices. As there may be new details emerging down the line, I look forward to continue working on existing and new challenges in an effort to accomplish the goals of my project.
The next steps in my project involve the following:
- Working alongside colleagues to find workarounds for getting data in and out of the clusterp
- Continue working towards persisting data storage options like Azure Blob and Azure Data lake.
- Comparing alternative storage with AzureFilep
- Fine-tuning the cluster configuration based on running job/nas/content/live/hpccsystems.
More information about Yash’s work on this project can be found in his weekly blog journal.
Find out more about our Cloud Native HPCC Systems Platform
Our Cloud Native big data platform, as Yash mentioned, is currently under development. If you would like to be an early adopter, all the resources you need to get started can be found on this wiki page.
We would like to hear about your experience. You can log any issues you find or suggestions for improvements using our Community Issue Tracker.