Adopting HPCC Systems and ECL – A User’s Perspective

Akhilesh Badhri has 14 year of experience in Data Engineering. At LexisNexis Risk Solutions in Mumbai, India, he started as data engineer and is now a Software Engineering Lead, leading a team of engineers who are passionate about data. Akhilesh has gained expertise across multiple tech stacks including linking and big data technologies.
He has been using HPCC Systems for around 5 years and is currently working in the Healthcare side of the business, focusing on data contribution and data delivery for the insurance domain in India. He has extensive experience of using the ECL language and Roxie (our data delivery engine) as well as MySQL, UNIX, Cloud and Git, which he uses alongside the HPCC Systems platform. On personal front he loves listening to music and enjoys playing the guitar.
Akhilesh is a great advocate for the HPCC Systems platform. By sharing his own user experience, he aims to provide colleagues and the wider Tech community in India with some first hand knowledge to help with adoption of the HPCC Systems platform. ************************************************************************
Throughout my career before joining LexisNexis Risk Solutions, I worked on data warehouse ETL using a database technology. So when the chance came to work with LexisNexis Risk Solutions using a technology called HPCC Systems, I was in two minds. I could definitely see the the positive side of working with a technology that was purpose built to process big data. However, since I had not heard of HPCC Systems before, I had a number of unanswered questions:
- How would this benefit my career going forward?
- Would I lose touch with technologies I have worked with for many years?
- What if I want to get back to my original technology (the bread winner technology)?
- I must learn a new technology and programming language from scratch, will this affect my productivity?
- How does it compare with what I am used to using, particularly with regard to my productivity?
Despite my initial concerns I decided to go ahead. I took the job and and started to try this platform which was completely new to me.
Learning a new technology, using it effectively and suggesting ideas of how to use it better takes time, patience and dedication. But it is definitely worth the investment. If you have a background in database technology, you will certainly have an advantage when learning the ECL language. ECL was created specifically for creating queries into big data, allowing you to create complex queries fast and in significantly fewer lines of code than would be required in a language like, for example, C++. Although, in case you don’t know, ECL is translated into C++ by the built-in code generator in the HPCC Systems platform. ECL is also a declarative language, which means that any queries you create can be leveraged by other queries as needed.
To get myself up and running with HPCC Systems, I used a number of different resources which also helped me to address my initial concerns. The following resources were particularly useful:
- HPCC Systems Documentation. Find out more about how to use the platform and the ECL language. There are a couple of tutorials available you can use to get some quick and practical experience.
- HPCC Systems Online Training Courses. These online courses are a very good source for learning about HPCC Systems and the ECL Language.
- HPCC Systems Community Forums. Using the Forums, you can ask questions and share your own knowledge about HPCC Systems. They a very good resource for getting the help you need.
- Introduction to HPCC Systems White Paper. I found this to be a good first reference for beginners. It provides a great overview, information about the architecture, data and code deployment details as well as a review of all the capabilities and performance statistics and a comparison with Hadoop.
- End to End Data Lake Management Solution White Paper. Reviews how HPCC Systems is a proven data lake solution, providing the answers to common problems associated with data lake management
- Download the HPCC Systems Bare Metal Platform – Including Plugins, ECL IDE and Client Tools
- HPCC Systems Machine Learning Library – The is also open source and includes bundles for a number of ML algorithms for supervised and unsupervised learned and Natural Language Processing.
I mentioned Hadoop above. HPCC Systems has actually been around longer than Hadoop. HPCC Systems was created in 2000 and for many years was used by LexisNexis Risk Solutions as a proprietary solution. In 2011, it went open source and is now available to all for free while it continues to be widely used by LexisNexis Risk Solutions. HPCC Systems celebrated its 10 year anniversary of being open source in 2021 and you can find out more about that in this blog and by watching developers and community users talk about HPCC Systems in this series of anniversary videos.
Learning becomes easy when working on a specific requirement and implementing a solution. I am a member of the data engineering team here at LexisNexis Risk Solutions in India and have been part of this team for a long time. During this time, I have gained good exposure to HPCC Systems, learning a wide range of best practices with regard to implementation. Many of these best practices are covered in our documentation, the various training courses referenced above and from the developers or other users in the HPCC Systems Community Forum. Here are a few of my own takeaways:
- Keep your ECL code as simple as possible
- Keeping functionality or common functionalities stored separately is the most convenient thing to do from a usability perspective
- Test individual components separately before doing an integration
- Use the workunit graphs in ECL Watch to identify issues like skews (data distribution) and other areas where improvements to the code may help with efficiency
The ECL Watch user interface allows you to observe workunit status and performance, manage data files across the landing zone and nodes as well as providing information about the status of the various system components. This felt like quite a different experience to a previous Oracle user, like me who was used to being able to see the output of my workunits directly. You can also get this experience by viewing your workunits and their generated graphs from within the ECL IDE, however, ECL Watch provides a much comfortable viewing experience. It also provides a dashboard of other features that make it easier to manage and manipulate everything you need to have a successful outcome. Find out more about ECL Watch here.
ECL IDE is the integrated development environment that HPCC Systems provides as standard (download ECL IDE and Client Tools here, Windows O/S only). ECL IDE is widely used to write ECL code and queries. I have been using it for the major part of my experience. HPCC Systems also provides an ECL Extension for VS Code, (available on the Visual Studio Marketplace) which is also being used by developers to write ECL code. I personally find VS Code to be more developer friendly than ECL IDE. If you have already started using the ECL IDE and want to transition to using VS Code, read this blog which provides guidance on how to make that switch.
During my earliest days of using the ECL language, the code version was integrated into the ECL IDE. A MySQL database would serve as the repository for my ECL code. In the last couple of years GitLab and GitHub have taken over the code repository. Along with code versioning, Git helps with streamlining code changes and the automated delivery of code to production post code quality control and review.
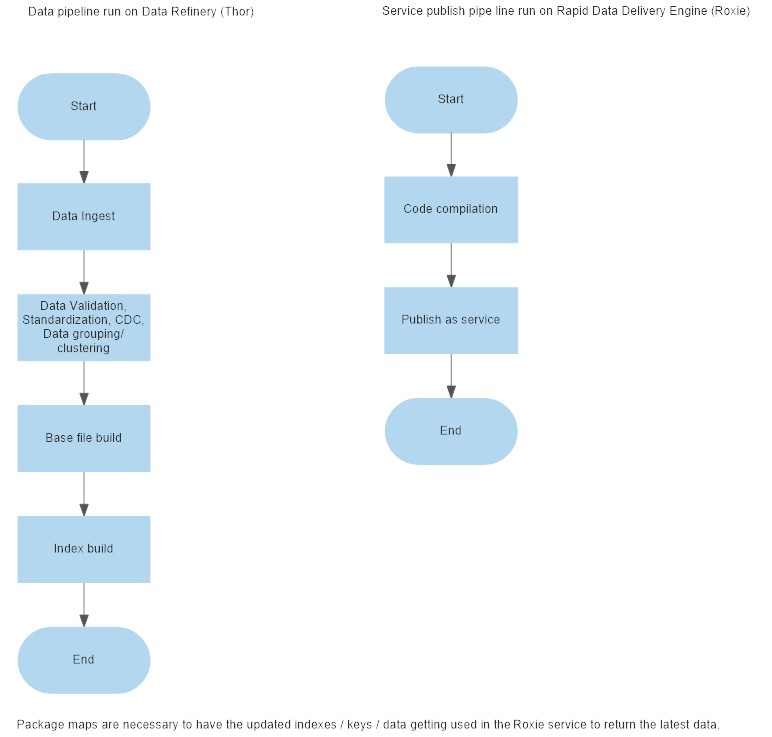
Your data, (structured and unstructured) will need to be ingested into HPCC Systems before you can use it. I have found that profiling helps provide a better understanding of the data received from the source. Data transformation/standardization, CDC and indexing of data needs to the done as per the business requirements. These activities are completed on the Thor cluster. Once the data has been cleaned and sorted, it is then ready to be used for the designated business purpose.
A lookup code is written, compiled and published to the Roxie cluster. This published code is referred to as a service and it feeds on this contributed data which has been indexed. The Roxie service is integrated with a front end application, which is accessed by the end user to derive insights from the contributed data.
The data contribution and service deployment can be automated using pipelines in GitLab and actions in GitHub. I have tried to represent the Build (data contribution) and Deploy (service deployment) stages in the following diagram:
HPCC Systems can be used to ingest and analyse any kind of data, the larger the better. So whatever the demands of your project, it is a great solution. One project I am particularly proud to have contributed to required the building of an application to identify people who might be involved in committing fraud against the Ayushman Bharat health scheme. This is a public national health insurance fund for low earners in India. The project requirements included analysing the data according to the business rules provided to identify fraudulent claims by people who were not eligible to receive financial assistance from the fund.
This all brings me round in a full circle to where I started this blog talking about my initial concerns as I began my HPCC Systems and ECL language journey. Knowing what I know now, this is how I would answer those questions:
- I have learnt an additional big data technology which is essential to my career journey
- I have not lost touch with the technologies I have used previously. I still get the opportunity to use and improve them and now I have another to add to the ever growing list
- As with most things, we move on. I am not sure it is relevant any more to think about going back
- Learning a new technology took time and I am sure during this learning phase my productivity may have temporarily declined. However, with any learning curve this is to be expected and it is not something that is relevant to me any more. I am comfortable with HPCC Systems and how it works and I am now in a position to support and encourage others who may be just starting using this platform.
- Having used HPCC Systems over time, I believe I am in a good position to say that this big data processing technology has the upper hand when it comes to processing huge volumes of structured and unstructured data
HPCC Systems continually adapts to changes and advances in technology. In 2021, a Cloud Native version was released which combines the usability of our bare metal platform with the automation of Kubernetes to make it easy to set up, manage and scale your big data and data lake environments. To find out more about using HPCC Systems Cloud Native visit our Cloud Native wiki to get access to blogs and videos designed to help you get started quickly. You can also visit our Helm Chart GitHub Repository to see some example Helm charts and deploy an entire HPCC Systems environment to a Kubernetes cluster.
If you are interested in using HPCC Systems with Azure and Terraform, read this blog by Godji Fortil, one of the developers on the HPCC Systems platform team, who takes you through how to do this step by step.
You can also find out more about using Azure spot instance and eviction by reading this blog contributed by Roshan Bhandari, who completed this research during his HPCC Systems internship in 2021 and is now a LexisNexis Risk Solutions Group employee.
Migrating to the Cloud Native platform is the next part of the HPCC Systems journey for me and I am pretty excited about it!