Deep Sequence Learning in Traffic Prediction and Text Classification
Deep learning is a subset of machine learning that is modeled based on the human brain. It essentially teaches computers what comes naturally to humans (learning by examples). This blog discusses how deep learning models using background knowledge were used to achieve sequence learning on traffic and natural language. We also introduce the deep learning tool, TensorLayer.
Jingqing Zhang, a 2nd –year PhD candidate at the Department of Computing, Imperial College London, introduced two projects during HPCC Systems Tech Talk 15. The Traffic Prediction with Auxiliary Information Project (accepted by KDD’18) led to the release of a new large-scale traffic dataset with auxiliary information, including search queries from the Baidu Map app, and proposed hybrid deep learning models to achieve state-of-the-art traffic prediction accuracy. In the Zero-shot Text Classification with Knowledge Graph project, knowledge graphs and a two-step classification policy were used to achieve zero-shot learning.
In this blog, we:
- Discuss deep learning and sequence learning.
- Introduce the Traffic Prediction with Auxiliary Information Project.
- Explore Zero-shot Text Classification with Knowledge Graph, using knowledge graph to achieve zero-shot classification.
- Introduce the TensorLayer tool. TensorLayer is a deep learning tool developed by the Data Science Institute (Imperial College London).
Deep Learning
 Deep learning is a subset of machine learning that uses a layered structure of algorithms, called an “artificial neural network,” to analyze data. Like machine learning, these algorithms parse data, learn from that data, and then apply whatever is learned to make informed decisions. But, the distinction from machine learning is that the deep learning model is designed to continually analyze data with a logic structure similar to how a human would conclude. The “artificial neural network” can learn and make intelligent decisions on its own.
Deep learning is a subset of machine learning that uses a layered structure of algorithms, called an “artificial neural network,” to analyze data. Like machine learning, these algorithms parse data, learn from that data, and then apply whatever is learned to make informed decisions. But, the distinction from machine learning is that the deep learning model is designed to continually analyze data with a logic structure similar to how a human would conclude. The “artificial neural network” can learn and make intelligent decisions on its own.
Machine learning models become progressively better at their functions but are limited. In machine learning, an outside source is required to make adjustments if an algorithm returns an inaccurate prediction. With a deep learning model, an algorithm can determine on its own if a prediction is accurate or not, using its “neural network.”
The Deep Learning apparatus consists of the following:
- Multiple layers of artificial neurons simulating the human brain
- The neuron connections getting stronger or weaker depending on input data
- The observed data is generated by the interaction of the different layers
- Multiple types of training depending on the requirement
- Data that could either be labeled or unlabeled
- The machines getting smarter with each set of data
- The ultimate stage is the machines getting cognitive
Sequence Learning
Everything in life depends on time, and therefore represents a sequence. We live in a world that is full of sequential data. Examples of sequential data include text, video, weather, stocks, etc. Humans gain understanding by learning a sequence of behaviors, consciously or unconsciously, therefore sequence learning is believed to be a fundamental human ability. But, sequence learning can be difficult for computers.
The sequence itself can be very informative. Statistical models, such as ARMA family (Autoregressive-moving Average model), SVR (Support Vector Regression), and Gaussian Process are often used to analyze temporal patterns of sequence. Today, many forecasting products and decision strategies use temporal patterns as strong indicators. However, for impractical scenarios, the sequence information is usually not enough, and background knowledge is important.
Now, let’s take a look at how deep sequence learning was applied to achieve traffic prediction.
Traffic Prediction with Auxiliary Information
 Traffic congestion is a major problem in many cities throughout the world. It is affected by a myriad of different factors, which makes it difficult to properly define and predict. Air pollution, long commute times, traffic bottlenecks, unpredictable public transportation, and traffic accidents are some of the major issues associated with traffic congestion.
Traffic congestion is a major problem in many cities throughout the world. It is affected by a myriad of different factors, which makes it difficult to properly define and predict. Air pollution, long commute times, traffic bottlenecks, unpredictable public transportation, and traffic accidents are some of the major issues associated with traffic congestion.
Accurate traffic prediction is essential for a smart city. A smart city is an urban area that uses information and communications to manage assets and resources efficiently. Accurate traffic prediction enables the calculation of more efficient routes and reduces travel time.
The objective of this research was to use the impact of online search queries to predict traffic speed. A major challenge for this project was a limited dataset. Most traffic data is low scale, focused on highway traffic data, or lacks ancillary information.
Both online and offline information can be used to predict traffic conditions, particularly, search queries on map apps. Road networks and public holidays can also be used to predict traffic conditions.
The graphs below show the correlation between the number of search queries and the traffic speed in a large urban area. The left figure shows the average speed and the figure on the right shows the query count. The blue lines indicate normal traffic speed (query counts), and the red lines show unusual traffic speeds (query counts). According to these graphs, a dramatic increase in query count leads to a decrease in traffic speed.
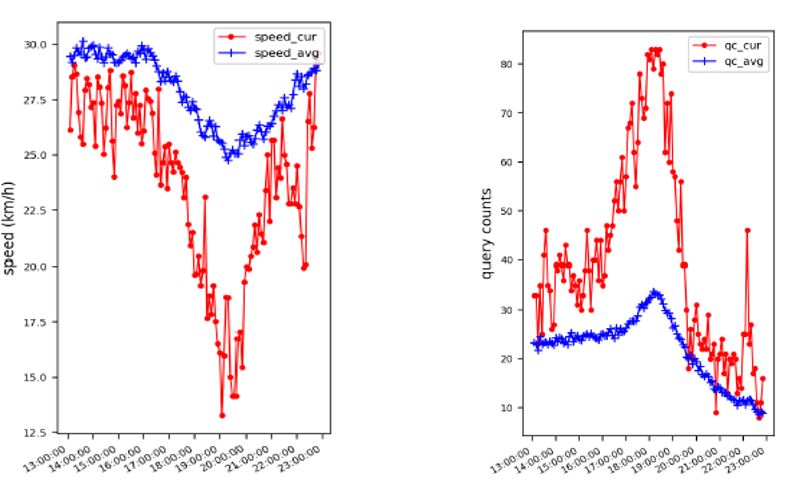
Solutions:
An effort to improve the research of traffic prediction resulted in:
- Release of a large-scale traffic dataset – “Q-Traffic (query traffic).”
- Proposal of a hybrid deep-learning model to incorporate all auxiliary information, including:
– offline attributes – Used Wide and Deep Networks for model
– spatial dependencies – Used Graph CNN for model
– online search queries – Devised an algorithm to calculate impact
The original work was accepted by KDD 2018. The project, “Deep Sequence Learning with Auxiliary Information for Traffic Prediction,” can be found at the following links:
https://github.com/JingqingZ/BaiduTraffic
Deep Sequence Learning with Auxiliary Information for Traffic Prediction Poster
Q-TrafficDataset
Q-Traffic is a large-scale prediction dataset that is publically available. The Q-Traffic dataset collects traffic data in Beijing, China, and has offline and online information. The data is provided by the Baidu Map App.
The Q-traffic dataset is much larger than previous datasets and has a larger scale. It also provides more domains of information, including road information, road network, online query number, road information for highways in urban areas, and availability for download.
The Q-Traffic dataset consists of three sub-datasets: a query sub-dataset, traffic speed sub-dataset, and a road network sub-dataset.
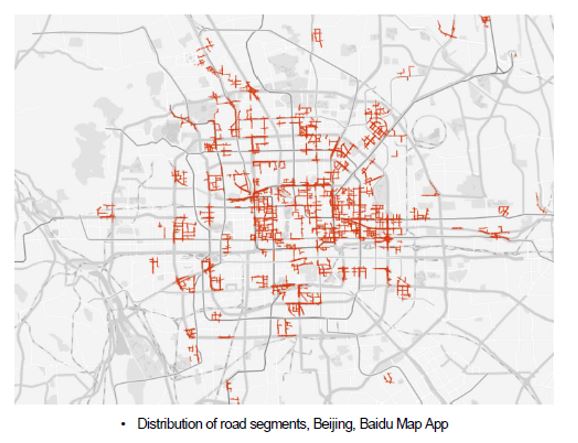
The figure below shows the spatial distribution of road segments in Beijing.
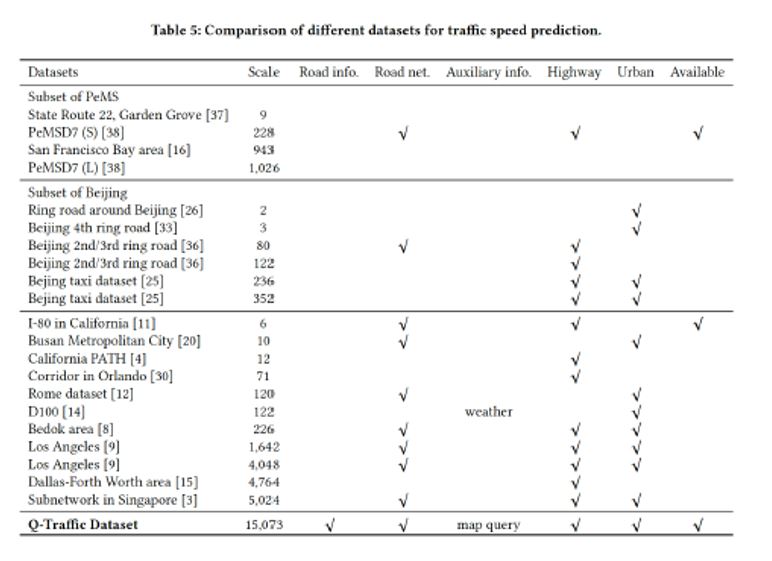
The table below compares the Q-traffic dataset with other popular datasets used for traffic speed prediction. The release of Q-Traffic should lead to an improvement in the research of traffic prediction.
To access the Q-Traffic dataset, go to the following link and follow the instructions: Q-Traffic Dataset.
Now that the Q-Traffic dataset has been introduced, we will discuss the concepts used in the proposed algorithm for event discovery. The algorithm uses query records to identify public events.
Discovery of Events by Query Records
It is assumed that queries can help predict traffic in a region affected by public events. A quick surge of search queries in a short period of time is usually caused by public events, including concerts, forums, places of interest, and anniversaries, etc.
During public events, traffic can be unusually heavy. These conditions cannot be captured by pure temporal models but can be indicated by the number of search queries.
An algorithm was proposed to discover the events using query records. There are two concepts used for this algorithm: The first concept is “Moment,” which measures the number of queries at a given location during a specific time span. If the number of queries over a period of time is higher than queries during normal conditions, it is called Moment. The time span for Moment is searching time (ts).

The second concept is “Event,” which is defined as the time period during which the time spans are all Moments. The time span for Event is the estimated time (td) of each search query.
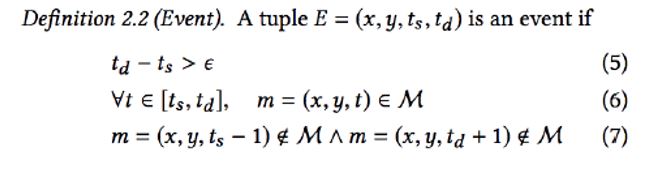
The combination of Moment and Event calculations can show the occurrence of a public event.
The figure below shows a flowchart of the mining of potential traffic in queries. In this flowchart, a set of map queries is segmented into grids. The arrival time at each query’s destination is estimated, consequently constructing an arrival time tensor. An event discovery algorithm is used to discover the events from the arrival time tensor.
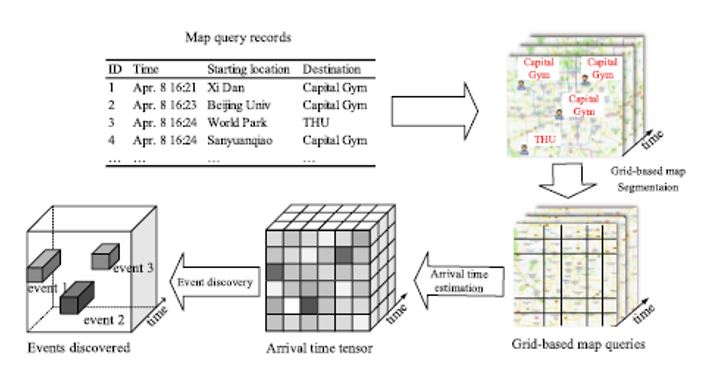
To this point, the correlation between query counts and traffic speed, as well as the association between increased search queries and events has been demonstrated. We will now look at the proposed algorithm used to measure the influence of queries on-road segments. The name of this algorithm is “Query Impact.”
Modelling of Query Impact
The Query Impact (QI) is:
- Calculated based on query counts and the spatial region that the query will influence.
- Defined to measure the influence of queries on-road segments.

Following is a demonstration of the Hybrid deep learning model. This is the proposed model for traffic prediction.
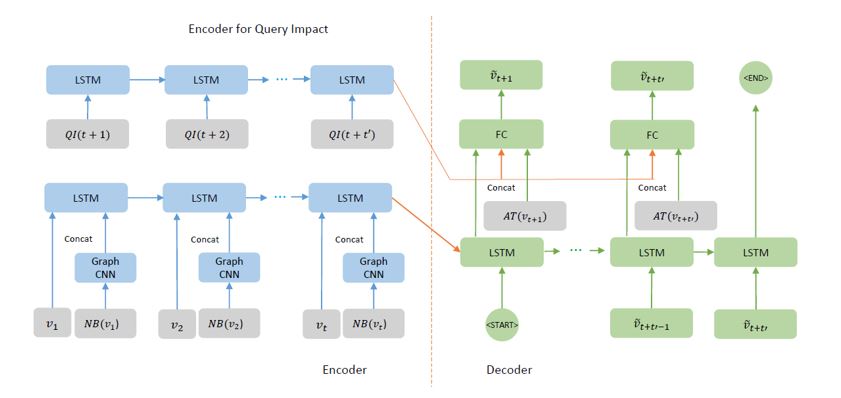
Hybrid Model
The Hybrid Model combines auxiliary information from three domains, including attributes AT(vt), spatial relation NB(vt), and query impact QI(l,t). The base model is the Seq2Seq model. The hybrid Seq2Se1 model incorporates the offline geographical and social attributes Seq2Se + AT, spatial dependencies Seq2Seq + NB, and online crowd queries Seq2Se1 + QI with a deep fusion.
For the Hybrid model:
- Given a sequence of previous traffic speeds, the model predicts the traffic speed in the near future.
- A graph CNN (Convolutional Neural Network) is used to encode spatial dependencies within a local row network.
- The Wide and Deep module is used to encode attributes into the model. The attributes include public holidays, road information, speed limit, the number of lines, etc.
- The Query Impact is also included.
Results
The tables below show that the Hybrid model is the best option.
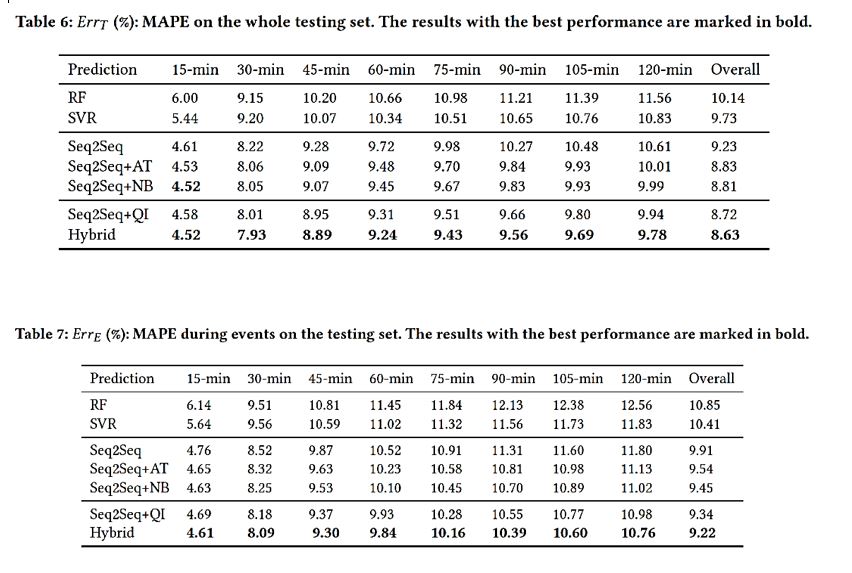
The results show that the mean absolute percentage error (MAPE) rate is lower if Query Impact is applied.
In addition to the traffic project, deep sequence learning with background knowledge is being applied to text classification.
Let’s look at an example. Which category does the following paragraph belong to? The categories are Science, Business, or Person.
“This removes bulky ions, such as magnesium and sulfate, as well as bacteria and other large particles.” – The Economist
We can easily identify that the category is Science. It is believed that humans can identify the category a document belongs to because of background knowledge. In this example, some keywords clearly indicate a specific category.
Zero-shot Text Classification with Knowledge Graph
The objective for Zero-shot learning (ZSL) for text classification is to classify documents of classes that are absent from the learning stage.
In testing scenarios, the traditional assumption of closed-world classification is that the classes in testing data must be seen during training. This thinking cannot adapt to the dynamic open world. Insufficient training data of rare and/or emerging classes is a big challenge of many classification tasks. Therefore, Zero-Shot learning is necessary.
Problem Definition:
In Zero-shot test classification:
- There are two classes: A set of seen classes and unseen classes
- Training set: { 1, 1, 2, 2,…}, ∈ , where t refers to task, and y refers to class. The task belongs to the set of seen classes, only, during testing.
- Testing set: same format as the training set, except ∈ ∪
- (The classes of tasks can be either seen or unseen).
Solution:
- It is believed that background knowledge can help machines better understand natural knowledge.
- ConceptNet was used to achieve Zero-shot test classification.
- ConceptNet is a knowledge graph of general human knowledge, designed to help computers understand the meanings of words that people use.
To solve the problem, a two-phase framework was proposed: Confidence Prediction and Two-step classification.
Framework
Phase1: Confidence Prediction – predicts with confidence that ti belongs to each class. 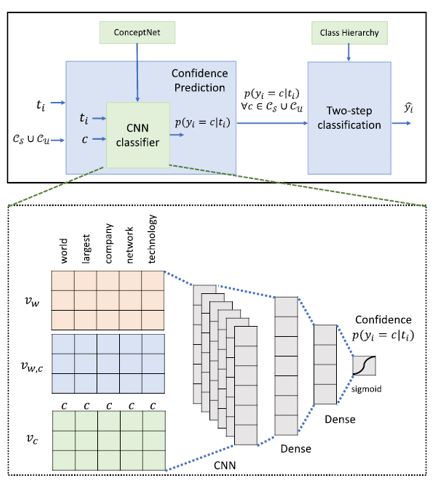
- In Confidence Prediction, CNN classifier is used together with a relation vector, extracted from ConceptNet.
- Relation vectors are calculated based on the distance between the class labels and each word in ConceptNet.
- So, the closer the word is connected with the class labels, the higher the value of the relation vector.
- Word vector vwvc: GloVe
- Relation vector vw,c: path from w to c in ConceptNet
Phase2: Two-step classification – based on the confidence predicted in the first phase
- In two-step classification, if the task, if accepted by any of the seen classes, the class that has the highest confidence, will be the final prediction.
– Confidence in seen classes is more reliable
– Check to see if ti belongs to any of the seen classes
– argmax ( = | ), c ∈
– If the task is rejected by all of the seen classes, then an unseen class that the task ti belongs to
must be found, using class hierarchy
- So, in order to transfer learned knowledge from seen to unseen classes, a score function is defined, based on the class hierarchy.
- The unseen class that has the highest score will be selected as the final prediction.
- argmax ∑ ′∈ ∪{ } , ′ = , ∈
Results
The following are the results of Confidence Prediction and Two-step classification. The table below shows the average results.
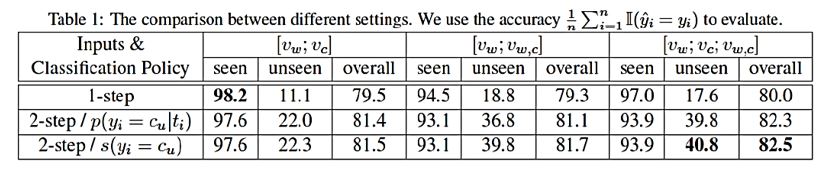
- After applying the Framework onto a DBPedia ontology dataset, it was found that 75% of the classes are seen, and 25% are unseen.
- Using knowledge graph significantly helps the framework classify instances of unseen classes correctly. Using [ ; ; , ] produces the best results.
- Two-step classification slightly undermines the accuracy of classifying seen classes but doubles the accuracy on unseen classes and results in better accuracy overall.
- Using the new confidence measure, which uses class hierarchy, improves the accuracy of unseen and overall, but insignificantly.
A paper on this project was published in “Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2019.”
Updates for this project can be accessed using the following link:
Integrating Semantic Knowledge to Tackle Zero-shot Text Classification
In addition to datasets, algorithms, and hardware, efficient development tools are essential for the success of deep learning.
TensorLayer and HPCC Systems
Deep learning has enabled many AI systems to exhibit unprecedented performance even beyond human  capabilities, such as natural language processing, computer vision, medical imaging, gaming, etc.
capabilities, such as natural language processing, computer vision, medical imaging, gaming, etc.
TensorFlow is one of the most popular and powerful tools used to develop deep neural networks, but it is difficult to use.
TensorLayer is a Deep Learning (DL) and Reinforcement Learning (RL) library that provides popular DL and RL modules that can be easily customized and assembled for tackling real-world machine learning problems. It was developed by the Data Science Institute.
TensorLayer, is a high-level wrapper of TensorFlow and naturally supports low-level APIs of TensorFlow. TensorLayer is designed to make the development of neural networks as easy as possible.
TensorLayer is open-source on Github. More information can be found at the following link: https://github.com/tensorlayer/tensorlayer
Future work includes:
Text mining research
- Classification is just the beginning.
- Background knowledge can help machines to understand natural language.
- Summarization of a scientific document and a collection of documents is a real challenge in the near future.
High performance platform: Future plans include the integration of
- TensorLayer with HPCC Systems.
- HPCC Systems provides outstanding computation capability, which can be useful for parallel training of neural networks to find best parameters and hyper-parameters.
- HPCC Systems provides efficient data delivery.
- TensorLayer is an easy-to-use deep learning tool.
Summary
Deep learning with background knowledge is extremely useful in tackling real-world problems. The projects discussed in this blog utilized deep learning models using background knowledge to create and release a large-scale traffic dataset (Q-Traffic), develop a Hybrid model for traffic prediction, and use a knowledge graph and a two-step classification policy to achieve zero-shot learning in text classification.
In addition, the open-source, deep learning tool, TensorLayer was introduced.
About Jingqing Zhang
Jingqing Zhang is a 2nd-year PhD (HiPEDS) at the Department of Computing, Imperial College London, London, UK, under the supervision of Professor Yi-Ke Guo. His research interests include Natural Language Processing, Text Mining, Data Mining, and Deep Learning. Jingqing received his MRes degree in Computing from Imperial College with Distinction in 2017 and BEng in Computer Science and Technology from Tsinghua University in 2016.
Acknowledgments
A special thank you to Jingqing for his excellent presentation, “Deep Sequence Learning in Traffic Prediction and Text Classification” during HPCC Systems Tech Talk 15.
Listen to the full recording of Jingqing Zhang’s presentation on “Deep Sequence Learning in Traffic Prediction and Text Classification.”
Summary of Link References
- https://github.com/JingqingZ/BaiduTraffic – Article on “Deep Sequence Learning with Auxiliary Information for Traffic Prediction” (KDD 2018).
- Deep Sequence Learning with Auxiliary Information for Traffic Prediction Poster – Poster for “Deep Sequence Learning with Auxiliary Information for Traffic Prediction” project (KDD 2018).
- Q-Traffic Dataset – Link to the Q-Traffic dataset
- Integrating Semantic Knowledge to Tackle Zero-shot Text Classification TensorLayer – TensorLayer webpage
- Listen to the full recording – “Deep Sequence Learning in Traffic Prediction and Text Classification” video clip from HPCC Systems Tech Talk 15 webcast