Understanding the Myriad Interface feature of HPCC Systems Machine Learning

This article assumes that you have a basic understanding of Machine Learning concepts and terminology, that you are familiar with the basics of using the HPCC Systems ML bundles, and that you have some experience programming in ECL.
If you would like a brief refresher on ML, please read my earlier article: Machine Learning Demystified. For an introduction to HPCC Systems ML bundles, please see Using HPCC Systems Machine Learning. You can learn ECL by reading our ECL documentation or taking an online training course.
The Myriad Interface
All of the production ML bundles support what we call the “Myriad Interface”. This means that you can perform multiple independent machine learning activities within a single interface invocation.
Why would I want to do that?
Suppose I would like to create a separate model for each major metropolitan area, so that I can make more granular predictions based on data from that area. With the Myriad Interface, I can invoke a single training (i.e. GetModel(…)) that returns thirty different models packed into one. Then, with a single invocation of Predict(…), I can make predictions regarding data from all 30 metropolitan areas, each against the appropriate learned model for that area. I can then assess the accuracy of the thirty models with a single call to Accuracy(…).
This is convenient from a programming perspective, but more significantly, it can better utilize the resources of an HPCC Systems cluster.
Invoking multiple activities at the same time allows us to more fully take advantage of the parallelism of the HPCC Systems cluster by executing all of the activities in one pass. Contrast this with serial invocation of each activity. If each activity cannot use the full set of HPCC Systems nodes, because it is of moderate size, or the particular algorithm cannot utilize all nodes at once, then many of the nodes will be idle for each activity. Executing the activities one at a time, will therefore allow many nodes to be underutilized during the whole operation. Invoking the activities in parallel, with the Myriad Interface, allows the activities to be balanced across all the nodes in the cluster, thereby maximizing the performance (i.e. minimizing the run-time).
Furthermore, many of the ML algorithms require multiple sequential steps to complete an activity. Each step requires synchronization among the nodes in the cluster. The more synchronizations required, the less optimal is the parallel processing within the cluster. Running multiple activities in parallel, does not increase the number of synchronizations versus a single activity, though each synchronization becomes larger (i.e. more data). While the larger synchronizations do impact performance, the impact is small compared to increasing the number of synchronization steps. This is due to latency (delays) in network communication. When waiting for responses from one node to another, no work can be done. Larger messages do not create such unproductive delays because there is no waiting, except for the actual time of the data transfer on the wire.
How does that work?
The magic of the Myriad Interface is embedded in the core record structures used by ML. If you recall, ML uses several main record types in its interfaces: NumericField is used to provide real-valued data in matrix form; DiscreteField is used to convey discrete (integer-valued) data; and Layout_Model is used to encode the Model that stores everything learned about the data. Each of these layouts has a field known as the work-item-id (“wi”). It is this id that provides isolation of the various independent activities across the interface.
When I provide my independent data, I can use a different wi for each metropolitan area’s data. The same can be done for the dependent training data. When I then call GetModel(…), the returned dataset will contain all of the separate models, each identified by the wi. The model that was trained by independent and dependent data with wi=1 will be labeled with wi=1. The same occurs for each wi. Now when I use the model(s) to predict a new dependent value (via Predict(…) or Classify(…)), the predictions will be based upon the model with the same wi as the independent data items. The same is true when I assess the models using Accuracy(…). In fact, every interface within the production ML bundles can handle multiple independent activities through the use of work-items.
The figure below illustrates the above data-flow.
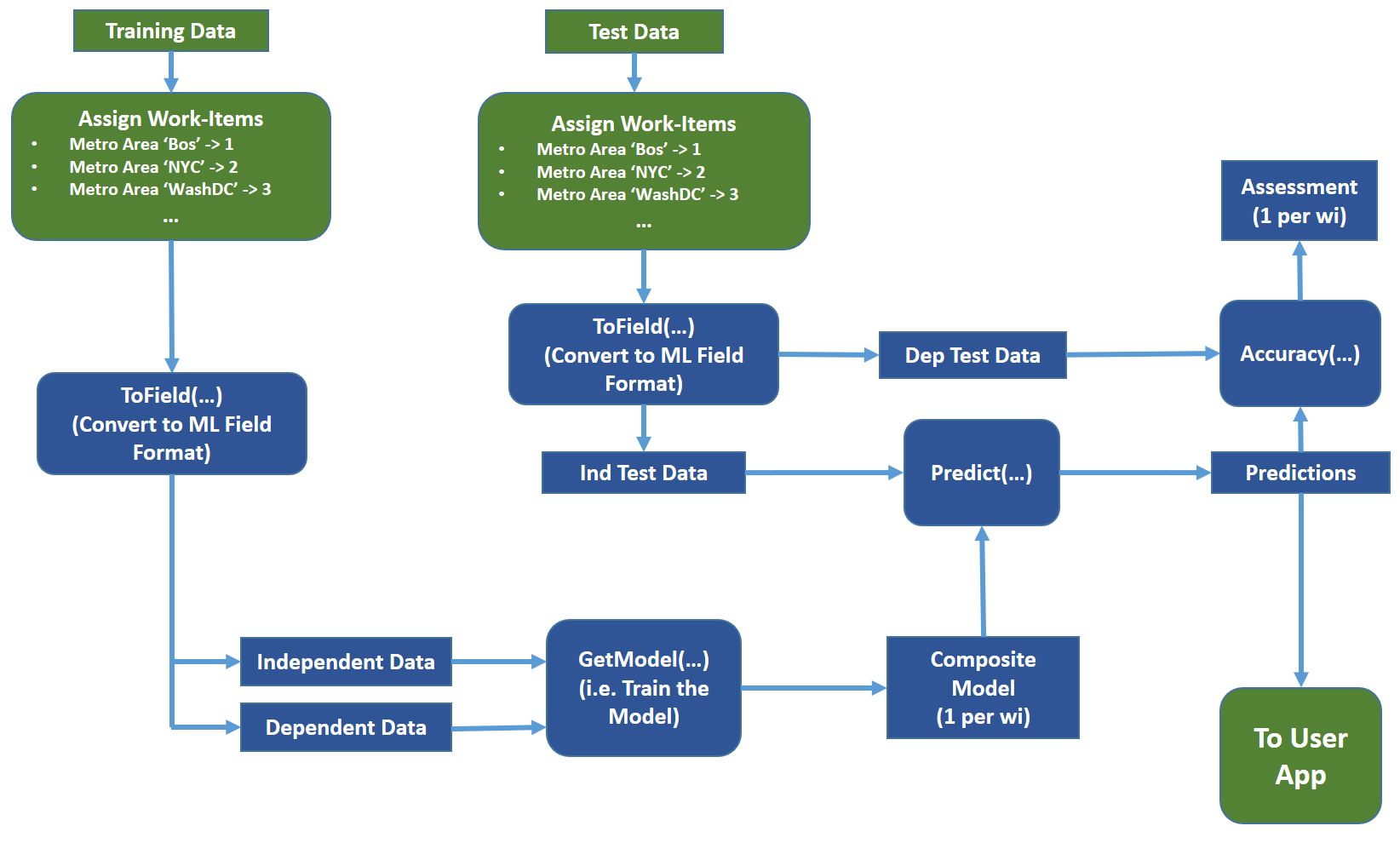
Now let’s look at an actual simplified example. We will follow the pattern from the above diagram.
Example
I have a dataset of measurements of trees in a forest
forestDat := RECORD UNSIGNED recordId; REAL height; REAL girth; REAL altitude; REAL age; STRING type; // 'HW' for hardwood, 'SW' for softwood END; myTrainDat := DATASET([...], forestDat);
We would like to predict the age, given height, girth, and altitude. Since hardwood and softwood trees have different growth characteristics, we would like a separate model for each.
The first thing I want to do is assign work-item ids based on the ‘type’ field.
// Record with wi_id added forestDat2 := RECORD(myFormat) UNSIGNED wi_id; END; // Transform to add a wi field forestDat2 Add_Wi(forestDat d) := TRANSFORM SELF.wi_id := IF(d.type = 'HW', 1, 2); // Use MAP if you have many types SELF := LEFT; END; myDat2 := PROJECT(myDat, Add_Wi(LEFT));
Now I can use ML_Core’s ToField macro to convert my data to the NumericField format used by ML.
Note that the ToField macro has an optional parameter to define which field contains the work-item-id.
ToField(myDat2, myDatNF, wiField:=wi_id);
Since we didn’t specify an id field, ToField will assume it is the first field.
We didn’t have to remove the ‘type’ field because ToField is smart enough to ignore any non-numeric fields. The resulting NumericField records will contain four fields: height, girth, altitude and age, assigned field numbers of 1, 2, 3, 4, respectively.
Now we can separate the independent data (height, girth, and altitude) from the dependent data (age).
indepTrainDat := myDatNF(number <= 3);
depTrainDat := PROJECT(myDatNF(number=4), TRANSFORM(RECORDOF(LEFT),
SELF.number := 1,
SELF := LEFT)); // We only have one dependent field, so make it 1
Now we can train the model. We’ll use a random forest regressor like in the previous article.
// Construct our learner
IMPORT LearningTrees; // Don't be confused by the fact that we are using Tree-based algorithms
// to learn about trees in a forest. Just a coincidence.
myLearner := RegressionForest(); // Almost always works well with default settings.
// Now train the model
mod := myLearner.GetModel(indepTrainDat, depTrainDat);
We now have a composite of two models — one for hardwoods and one for softwoods.
Now suppose I have some test data.
myTestDat := DATASET([...], forestDat);
I convert it in the same way I did for the training data
myTestDat2 := PROJECT(myTestDat, Add_Wi(LEFT));
ToField(myTestDat2, myTestDatNF, wiField:=wi_id);
indepTestDat := myTestDatNF(number <= 3);
depTestDat := PROJECT(myTestDatNF(number=4), TRANSFORM(RECORDOF(LEFT),
SELF.number := 1,
SELF := LEFT));
I can predict results using my independent test data.
predicted := myLearner.Predict(mod, indepTestDat);
And now I can assess the quality of the models using ML_Core’s Analysis module.
IMPORT ML_Core; assessment := ML_Core.Analysis.Regression.Accuracy(predicted, depTestDat);
Assesment now contains accuracy metrics for each of the two work-items (i.e. hardwood and softwood).
There is an alternative shorthand way that I could have done the above assessment.
assessment := myLearner.Accuracy(mod, depTestDat);
The learners provide built-in assessment functions that perform a Predict followed by a call to the appropriate ML_Core Analysis functions with the result of the Predict.
Now that I have created the composite model, I can use it to perform predictions of age on any new data I acquire, using the same Predict method as above. As long as the input records are tagged as softwood(‘SW’) or hardwood(‘HW’), ML will use the appropriate model to predict each sample.
Conclusion
We demonstrated how to train, predict, and assess multiple models at once using the Myriad interfaces.
Of course, we could have trained any number of models by assigning more work-items. In our example, all of the models were homogeneous — based on the same record layout and relating to the same dependent data. We could have used completely different datasets that had nothing to do with one another, or we could have trained models on completely different dependent data if we wanted to.
The Myriad Interface flows through all ML functions. We could have used it, for example, with PBblas to multiply independent sets of matrices, or in ML_Core to Discretize multiple sets of data at once. Myriad works in a consistent way across all of the production ML bundles and all of the attributes therein.
I hope that helps to illuminate the Myriad Interface, a powerful but potentially confusing, aspect of the HPCC Systems Machine Learning library.