Leveraging the Spark-HPCC Ecosystem
 James McMullan, Sr. Software Engineer at LexisNexis Risk Solutions, gave an overview of the Spark-HPCC Plugin & Connector in a breakout session at the 2019 HPCC Systems Community Day. This presentation also included an introduction to Apache Zeppelin, a demonstration of a random forest model created in Spark, and a discussion about the future of the Spark-HPCC Ecosystem.
James McMullan, Sr. Software Engineer at LexisNexis Risk Solutions, gave an overview of the Spark-HPCC Plugin & Connector in a breakout session at the 2019 HPCC Systems Community Day. This presentation also included an introduction to Apache Zeppelin, a demonstration of a random forest model created in Spark, and a discussion about the future of the Spark-HPCC Ecosystem.
In this blog we:
- Give an overview of the Spark-HPCC Plugin & Connector – Basics of reading / writing to / from HPCC
- Introduce Apache Zeppelin
- Create a random forest model in Spark – Compare results to Kaggle competition leaderboard
- Discuss the future of the Spark-HPCC Ecosystem
Let’s kick things off with an overview of the Spark-HPCC Plugin & Connector.
Spark-HPCC – Overview
There are two main parts to the Spark HPCC integration.
1. Spark-HPCC Systems Connector
- A library for Spark written in Java
- Allows reading and writing to HPCC
- Can be installed on any Spark cluster
2. Spark Plugin
- A managed Spark Cluster that gets installed alongside your HPCC cluster
- Requires HPCC 7.0+
- Spark cluster that mirrors Thor cluster
- Configured through Config Manager
- Installs Spark-HPCC connector automatically
Spark-HPCC Connector – Progress
Since last year:
Added remote writing support in HPCC Systems 7.2+.
- Initially only writing co-located from the Spark cluster to the Thor or HPCC cluster. The user is now able to write to remote clusters.
Improved performance
- Last year, the user was only able to read in Scala and Java. The user would have to serialize it to the Python and R run times and de-serialize it on the other side. This high performance bottleneck was removed, resulting in a 3 to 4 exit improvement for Python and R.
- There is now uniform performance across Scala, Python and R.
Increased reliability through testing and bug fixes.
Added support for DataSource API v1, which provides a unified read / write interface.
Spark-HPCC Connector – Reading
The example below shows the DataSource API v1 unified read interface. In the past, there were different interfaces for each language. Now, the interfaces are very similar.

- The URL is the same as the URL for ECL Watch.
- In this example, the “clusterURL” is for a local virtual machine.
- The file name is “example::dataset,” and “df” is the data frame. (A data frame is a table or a two-dimensional array-like structure in which each column contains values of one variable and each row contains one set of values from each column).
- A new option in Spark, “limitPerFilePart,” limits the number of records read in per file part. So, if there is a 200 way cluster and 200 file parts, there will be a 100 records from each file part, which amounts to a total of 20,000 records. This option allows the user to pull in a subset of a large amount of data when doing data exploration. In this specific case, you get the same I/O for 100 records that you would get for 20,000 records.
- Another new option in the latest version of Spark is “projectList.” Many datasets have hundreds of columns, and a user may only want 5 to 10 of those columns when doing data analysis. With this option, the user provides the list of columns desired. This command is comma-separated and period-delimited. An example is using “field1.childfield” to get column name, “childfield.”
Spark-HPCC Connector – Writing
The example below shows the DataSource API v1 unified write interface.

- In this example, “mode” is important. If a user tries to overwrite a file, it will result in an error. The user must specify “overwrite.”
- The other option of note in this example is “cluster.” The user must specify the cluster group name.
- This interface is similar in Java and Scala.
Now that we’ve discussed the Spark-HPCC Plugin & Connector, let’s move on to Apache Zeppelin.
Apache Zeppelin – Overview
Apache Zeppelin is an open-source, multi-user, web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Spark, Python, etc.
Apache Zeppelin provides a front end force for submitting Spark jobs. Initially, when working with Spark, Data Scientists were required to open the command line to submit a job, which was not a good approach.
Zeppelin is collaborative, allowing multiple people to work in the same notebook together. Zeppelin is similar to Jupyter Notebook, but is multi-user by default. There is no need to go to Jupyter hub. Everyone is able to work in the same centralized environment. Zeppelin is easy to use, handles resource management, and handles job queuing and resource allocation.
Apache Zeppelin – Features
Apache Zeppelin provides the following features:
- Multi-user environment by default
- Built-in Version Control
- Interpreters are bound at a Paragraph level.
- Allows multiple languages in a single notebook – you can use libraries from different languages and move data between them.
- Built-in visualization tools
- Ability to move data between languages
- Credential management – essential for our security team. We do not want passwords in code, and Zeppelin helps out with that.
Next, let’s move on to our Random Forests model. This model will illustrate how to do data exploration using Machine Learning. Data patterns will not be used in these examples.
 Spark Machine Learning Model – Brief Intro to Random Forests
Spark Machine Learning Model – Brief Intro to Random Forests
Random Forests are an ensemble of decision trees that work together to answer a question. Averaging the output of multiple decision trees provides a better prediction. Random Forests require data to be numeric. For the purpose of creating a model, all data is converted into numeric types.
Spark Machine Learning Model – Bulldozers R Us
For the Spark ML Model, a Random Forest Model will be used to predict auction price, using an open source bulldozer auction dataset from Kaggle. The dataset can be found at: www.kaggle.com/c/bluebook-for=bulldozers
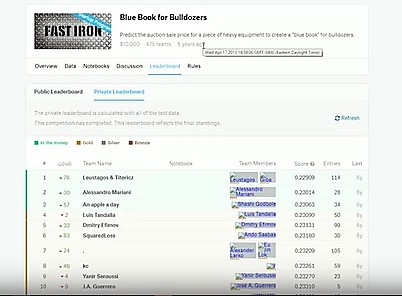
The results for this model will be compared against the Kaggle leaderboard results. The score is calculated using RMSLE (Root Mean Square Log Error). RMSLE provides a percentage based versus an absolute error
It is a little difficult in Machine Learning to know how good your model is, so comparing this model with those in Kaggle gives a good indication of how well the model works.
The picture below is the actual Kaggle competition page for the Bulldozer example.
Since this model uses open source data, there is a training set and a validation set.
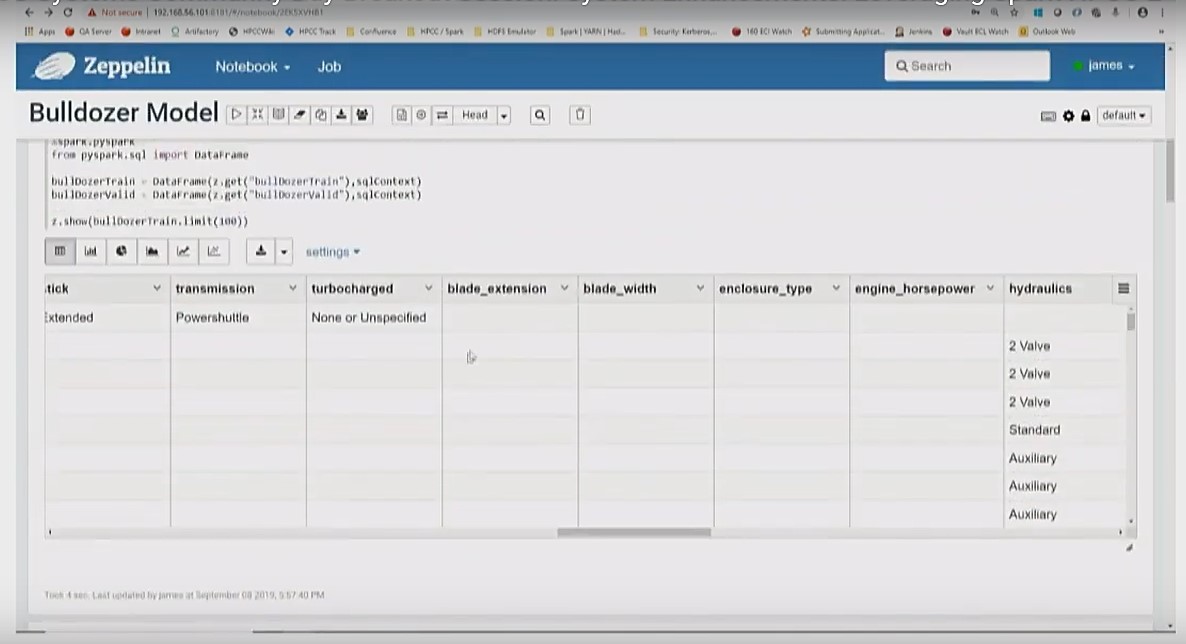
The datasets are uploaded to HPCC systems, as shown below.
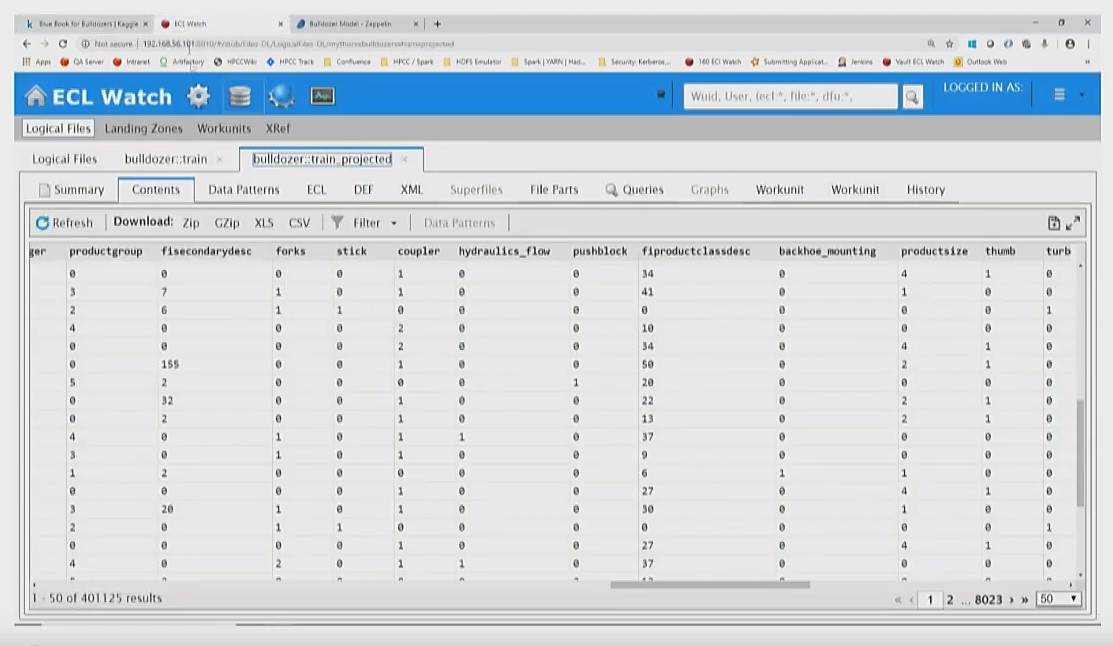
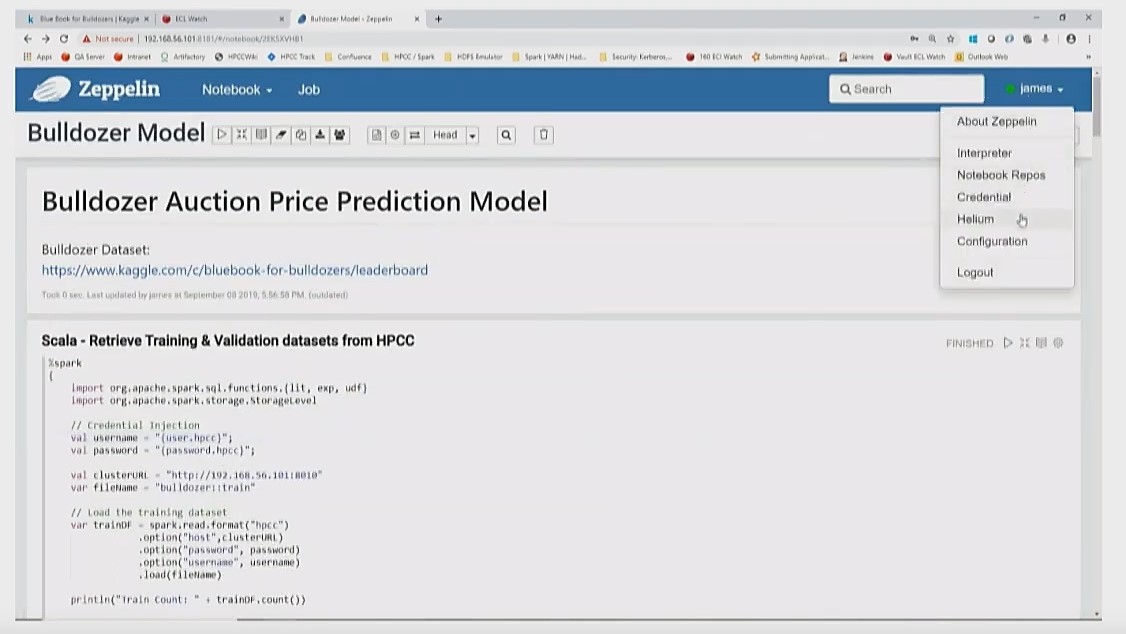
Scala – Retrieve Training & Validation datasets from HPCC
The validation and training datasets are retrieved from HPCC using Zeppelin.
An important thing to note are the following credentials:
//Credential Injection
val username = “{user.hpcc}”;
val password = “{password.hpcc}”;
Credential manager is built into Zeppelin, where credentials are entered by the user. An ADRUN time is “injected” wherever “user.hpcc” occurs in the code. Credential injection removes passwords from the notebooks and allows for collaboration.
Credential manager can be accessed using the pull-down menu, as shown in the image below, by selecting “Credential.”
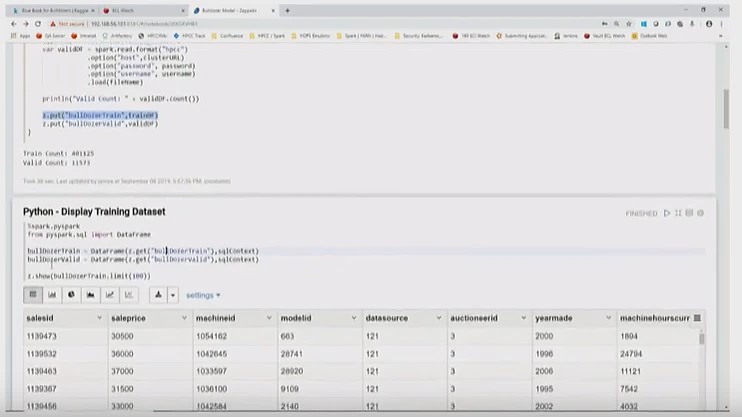
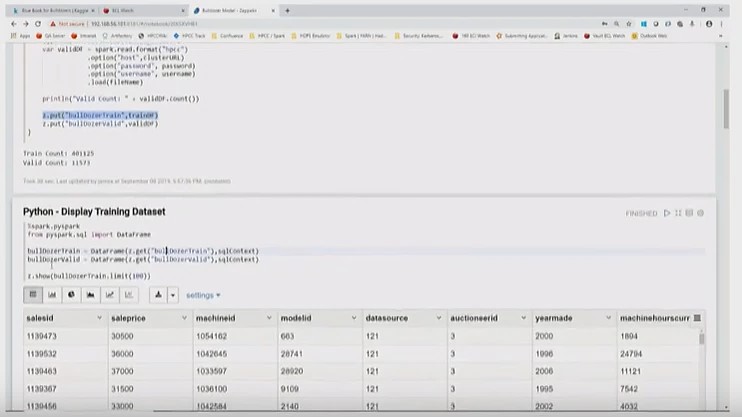
Zeppelin Functions
- Zeppelin function, “z.put,” places the “bulldozerTrain” dataset into Zeppelin context. This allows for transfer between languages (from Scala to Python).
- Zeppelin function, “z.get,” retrieves the dataset from Zeppelin context.
- Zeppelin function, “z.show,” displays the content of the dataset.
Dataset Pre-Processing
The bulldozer dataset has various datatypes, such as null values, strings, dates, etc.
Decision trees operate on numeric values, so it is necessary to process the dataset by getting rid of the null values, and converting the unsupported datatypes into numeric values.
It is also necessary to convert the “saleprice” to “log(saleprice)” for the RMSLE (Root Mean Square Log Error) calculation.
Scala – SQL UDF (User defined function)
In the code below, a new UDF (user defined function), “parseDate,” is registered. This function is used in subsequent code.
- Spark has SQL support, so the user can write SQL to query, create new tables, etc.
- A java simple date format is used in the code.
- It is best to write the code in Scala because of better performance. Python has some query optimization overheads.

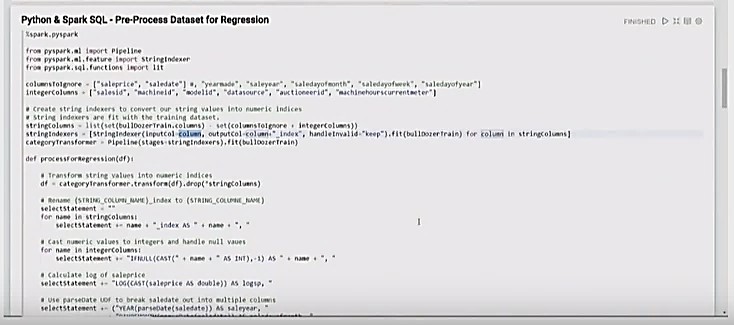
Python & Spark SQL – Pre-Process Dataset for Regression
The code below pre-processes the dataset for regression calculation:
- The “columnsToIgnore” command indicates columns to be removed from the dataset.
- The “log of saleprice” is calculated, and the “saledate” data is broken out into subtypes (year, month, etc.).
- The “integercolumns” data is converted to numeric values.
- The “stringcolumns” command shows the columns to ignore, and the integer columns removed from the total columns.
- The “categoryTransformer” combines everything into a pipeline. This is run on the dataset, and the transformation is completed.
- The “handleInvalid” takes a value that hasn’t been before, keeps it, and sets it to zero.
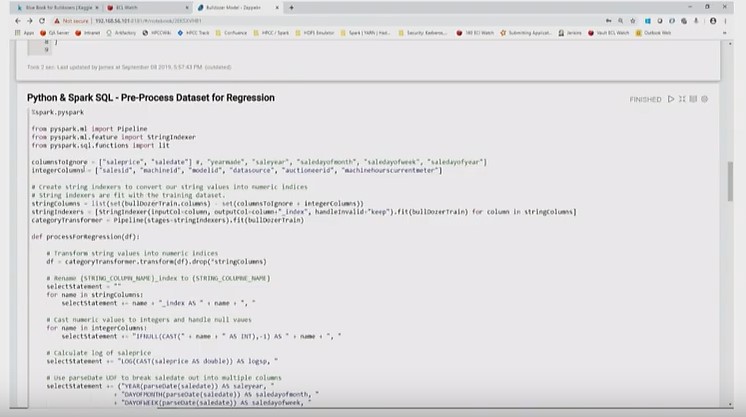
For each column in “stringcolumns” a “string indexer” is created, as seen in the image below.
In the “string indexer,” each unique value under the hydraulics column is converted to a numeric value.
Define Process for Regression – Highlight code and provide explanation
During the process for Regression:
- The “categoryTransformer” command is run to turn the string columns into index values.
- The old string columns are dropped using the “drop(stringColumns”) command.
- The new string column names are the original name with “_ index” attached.
- The new string column names are renamed with the original column names to maintain consistency.
- Numeric values are cast into integers and any null values are handled.
- The salesprice is cast to a log of saleprice.
- String SQL statements are concatenated together into one SQL statement that is run against the dataset.
- The Scala SQL UDF is broken out into “saleyear,” “salemonth,” etc. to make it easier for the system to analyze.
- A new view of the dataframe “df” is created.
- The “selectStatement” is run onto this to create a new table.
And finally, everything is written back to HPCC.
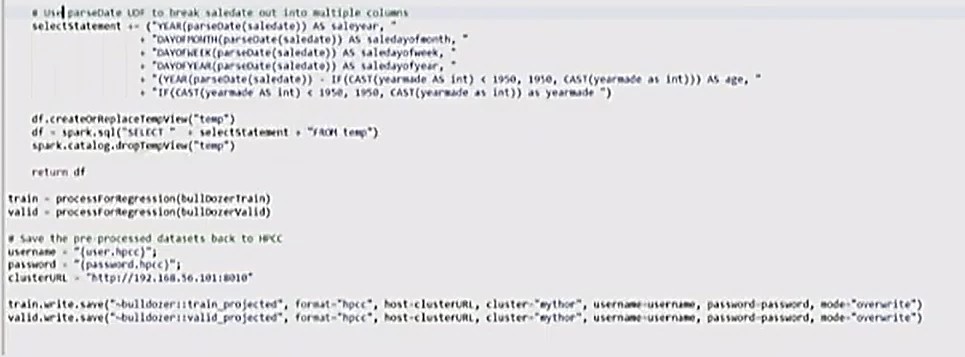
The images below show the dataset that is written back to HPCC. Everything has been converted to numeric values.
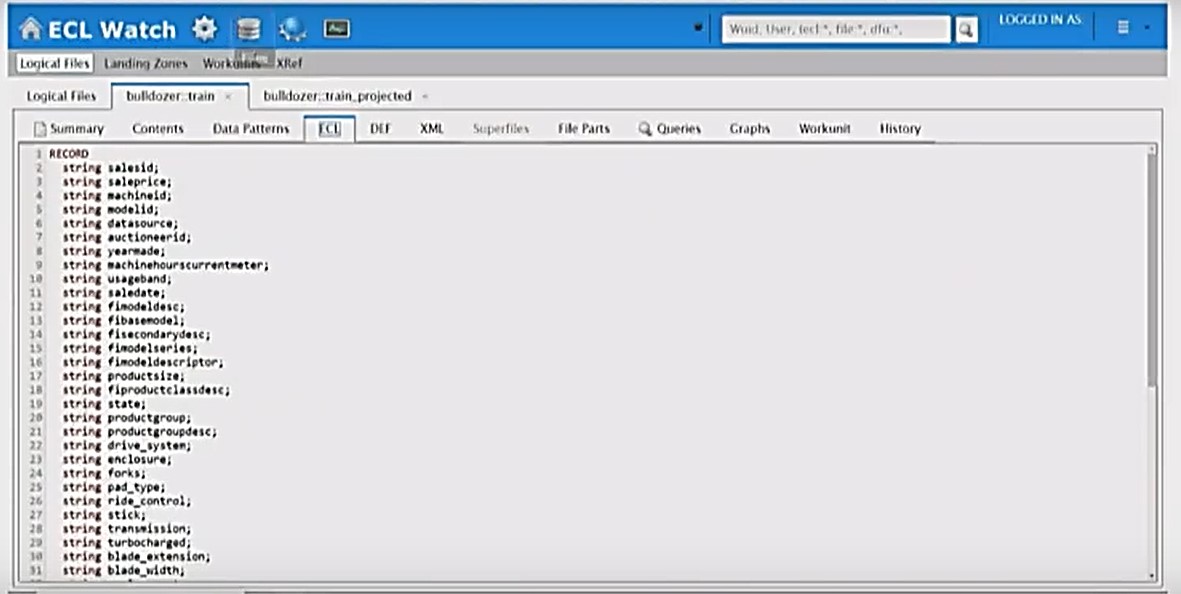
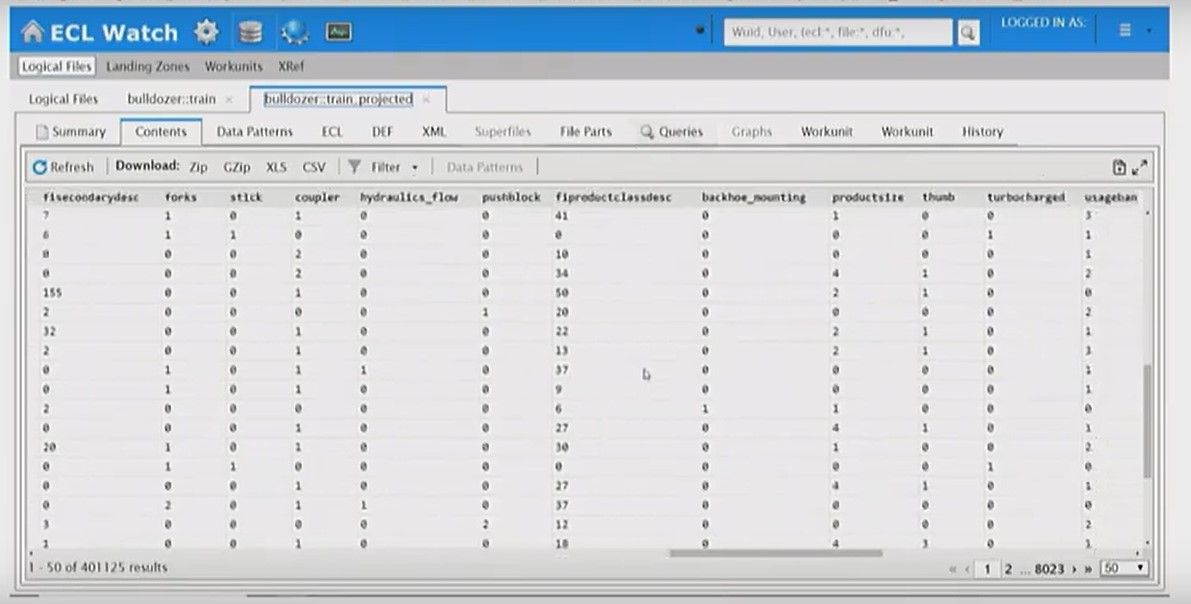
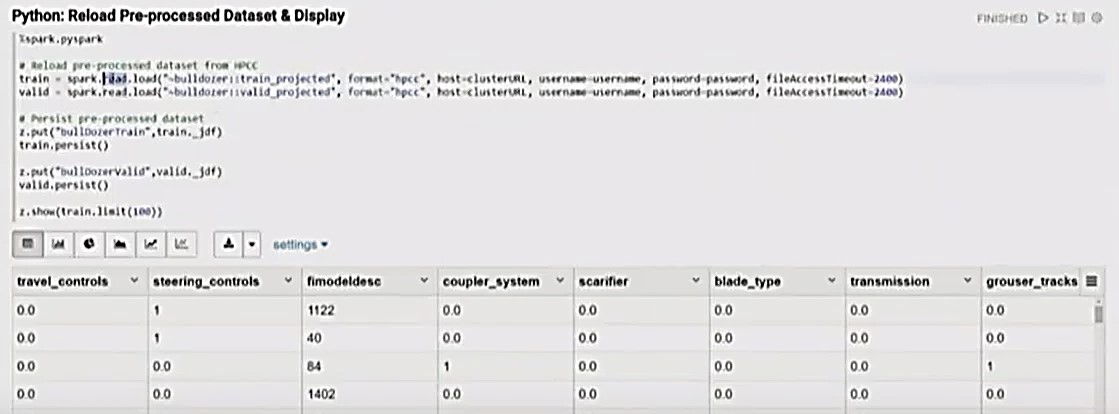
Python: Reload Pre-processed Dataset & Display
The information is then loaded back from HPCC, in Python, and put into Zeppelin context using the z.put command.
The “persist” command, in Spark, means that it is kept in memory.
Python – Train Model and Calculate Predictions
Next, in the process, is to train the model and calculate predictions.
- The random forest regressor does the work.
- The feature column and prediction column are broken apart.
- The “vectorAssembler” is used to put the feature column into one column called “features.”
- For the “vectorIndexor,” “maxCategories” is equal to 7.
- There are a few columns that have a lot of options. Since a maximum of 7 categories was specified, those columns with more than 7 unique values will be treated as a continuous variable for calculation purposes.
- For the “featureSubsetStrategy” function, each decision tree in Random Forest must be different. For this function, of the 52 columns, half of those will be taken (featureSubset = 0.5), and half will be randomly selected for each decision tree.
- The “numTrees” function indicates how many trees are built into the Random Forest.
- The “maxBins” determines how continuous values are split up.
- The “maxDepth” function is the depth of the trees. This value must be tuned.
- This information is assembled together into a pipeline.
- The result of the evaluation is an RMSLE of 0.2655963667370131.
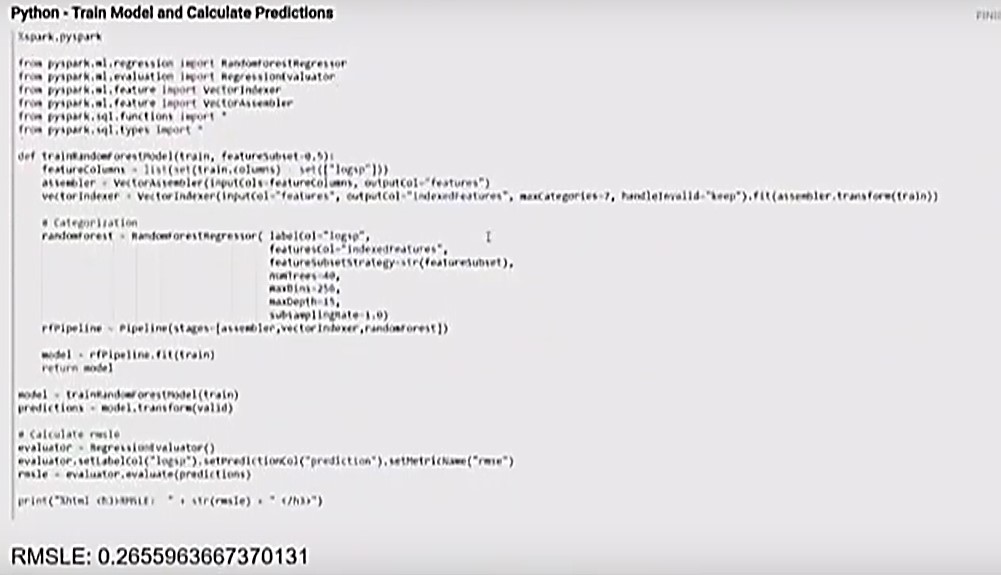
The results were compared to the results in Kaggle. The results for this model are in the top 11%. There was no feature engineering done for this model, and better results are possible.
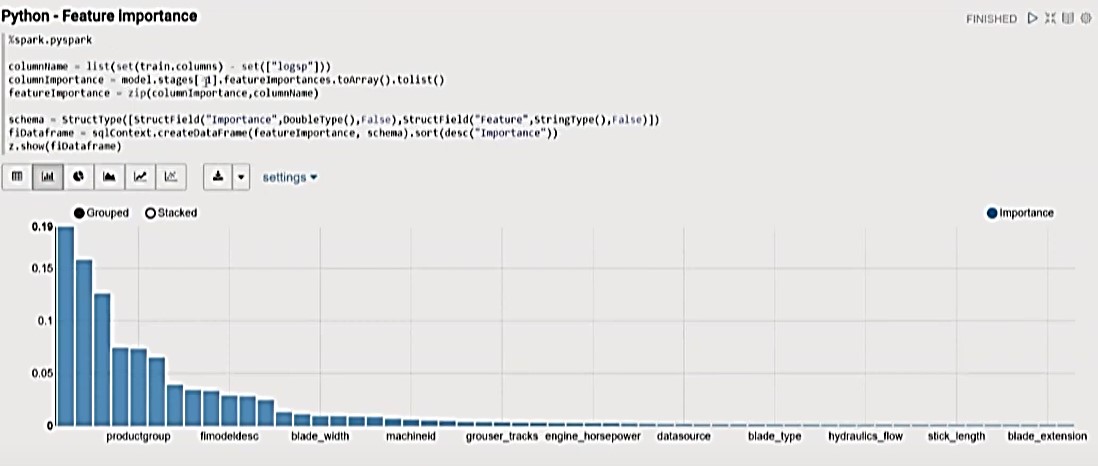
Python – Feature Importance
One of the cool features of Random Forest is that it alerts the user when something is important.
- For the visualization below, “featureImportance” from the Random Forest model is taken, sorted, and plotted.
- This shows which features are the most important.
- This visualization is built into Zeppelin.
PySpark / ScIPy – Feature Correlation
Another visualization to consider is the correlation between two columns.
For this feature correlation, a dendrogram is plotted using matplotlib from Python.
The further to the right that these features break apart and split, the more that they are correlated.
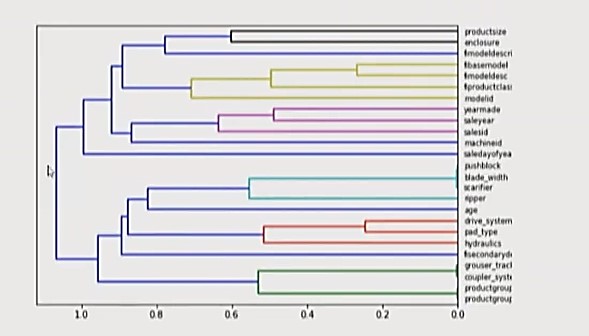
To improve a model, look at the top features and the correlations between features, increase the number of trees, and use them to make a better model.
Spark Machine Learning Model – Results
The results for this Spark ML model are an RMSLE ~ .26, which is around 50th out of 450 participants in the Kaggle competition. This was pretty good, considering that there was little to no feature engineering.
An RMSLE of ~.22 is possible with Random Forests, hyper parameter tuning, and feature engineering. Deep learning can achieve an RMSLE better than ~.22.
Spark-HPCC Systems – Future & Future Use Cases
The goal of this presentation was to illustrate how Spark and HPCC can be used together.
- There will be continued support and improvement in the Spark-HPCC Ecosystem.
- The Spark-HPCC Plugin & Connector leverages libraries in Spark, Python, and R.
- Optimus – Used for data cleaning for Spark.
- Matplotlib – Python 2d plotting library that is used for feature importance and feature correlation.
- Spark Streaming is good for IoT Events and Telematics. It solves issues when pulling in streaming data.
- Deep learning with Spark is Possible through external libraries.
- Spark 3.0 will support Tensorflow natively.
Summary
The Spark-HPCC Systems ecosystem provides new opportunities. There is access to an entire ecosystem of libraries and tools.
Apache Zeppelin is a great tool for data analytics and collaboration. It also provides a front-end source for submitting Spark jobs.
A Random Forest model was created in Spark to illustrate how to do data exploration using machine learning. Calculations were done using RMSLE (Root Mean Square Log Error), and the results were compared to Kaggle competition results. The results were in the top 11% with minimal feature engineering. A lower RMSLE score is possible using more decision trees, hyper parameter tuning, feature engineering, and deep learning.
Acknowledgement
A special thank you to James McMullan for his wonderful presentation, “SystemEnhancements. The Spark-HPCC Plugin & Connector,” during the 2019 Community Day.
Listen to the full recording of the presentation:
Leveraging the Spark-HPCC Ecosystem.