Developing and Training a GNN Model on Azure

Carina Wang joined the 2021 HPCC Systems Intern Program to complete a project focusing on processing student Images with Kubernetes by developing and training a HPCC Systems GNN model using our Cloud Native Platform. This project also contributes to the the ongoing progress of an autonomous security robot that is currently under development at American Heritage School (AHS) in Florida, where Carina is studying as a high school student.
Carina entered a poster in to our annual contest in 2021, winning the Best Poster in the Use Category (see poster resources). She also spoke at our Community Day conference, showcasing her work to the HPCC Systems Open Source Community (Watch Recording). Her work has also been recognised by the wider RELX family in this blog on Elsevier Connect. She is the third AHS student to join the HPCC Systems intern program in recent years. The completion of her intern project means that their school security robot can now recognize known faces from a database of images. It’s an amazing story which Carina tells in her own words in this blog.
************************************
Why develop an autonomous security robot
In order to foster a safe learning environment, measures to bolster campus security have emerged as a top priority around the world. The developments from my internship will be applied to a tangible security system at American Heritage High School (AHS). Processing student images on the HPCC Systems Cloud Native Platform and evaluating the HPCC Systems Generalized Neural Network (GNN) bundle on the cloud ultimately facilitated a model’s classification of an individual as either an AHS student or Not an AHS student. While running the trained model, this robot will:
- Help security personnel identify visitors on campus
- Serve as an access point to viewing various locations
- Give students permission to navigate school information
Goals of my intern project
The long-term goal is to process mass amounts of student, staff, and visitor images with HPCC Systems. To bring HPCC Systems one step closer to that stage, this project displayed results at a faster pace and increased overall accuracy rates. HPCC Systems now provides a Cloud Native Platform and this project leverages this new platform by using the HPCC Systems GNN models on Thor clusters in a cloud environment to train a dataset with 4,839 images.
The prevailing obstacles faced in Machine Learning include insufficient real-world data and developing CNN models from scratch. To combat these challenges, this project took an alternative approach to data collection and evaluated multiple well-known industry standard models to identify a model with peak accuracy levels and time efficiency. Instead of artificially augmenting photos of each student (e.g. fake background colors and manually adjusting angles), I obtained 4,000+ images by splitting a video into frames. This magnified the scope of the project by expanding the number of real images from the robot with consistent backgrounds and angles.
Image classification has matured over the years and more mature models are now available. This project evaluated five existing TensorFlow CNN models (to compare processing speed and accuracy) and the HPCC Systems GNN model. Using the latter, helped test the HPCC Systems Thor functionality by varying the parameters on the GNN model. The application cluster with Docker images of HPCC Systems Core with TensorFlow libraries was deployed on Microsoft Azure. Evaluating industry-standard models, helps users easily train a dataset with drastically better results. The MobileNet V2 model was the fastest and achieved 100% accuracy. Results show that pre-trained models with modifications can achieve optimal results instead of using those that have been developed from scratch.
I developed a standard procedure for collecting images and training a model with the HPCC Systems Platform on Cloud. This will help others to carry out similar tasks with larger datasets in future (e.g. photos from the entire school instead of a sample). The image classification model will be compatible and work in conjunction with devices mounted on our security robot for user convenience. The cloud-based student recognition model that has been developed in this project will allow a person to receive confirmation from the robot that they are in the student database and retrieve information as part of a larger, interactive security feature.
What is the Workflow?
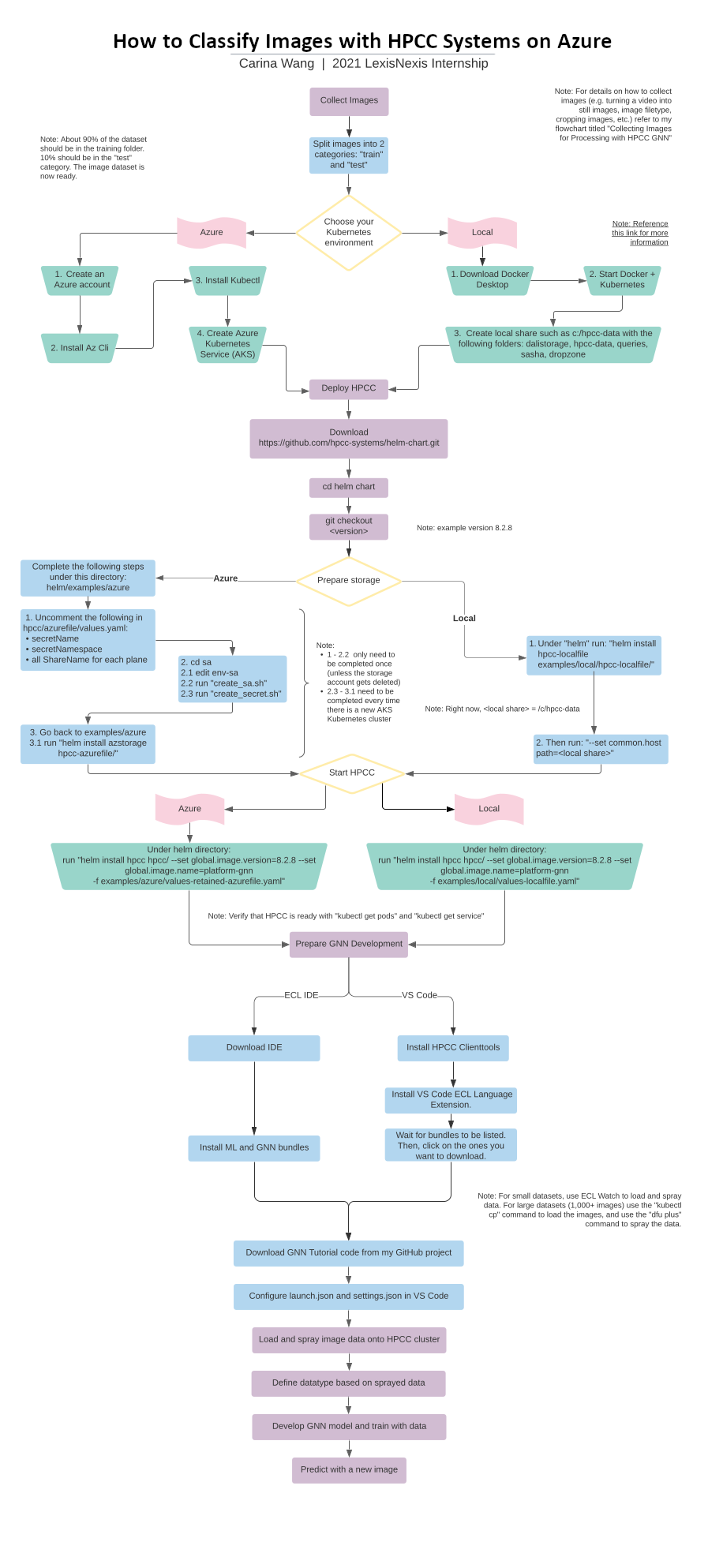
I created the following two flowcharts to reflect the findings of my internship and streamline a process for collecting images (specifically for the AHS dataset) and for classifying images with a GNN model on the cloud (applicable to all GNN users).
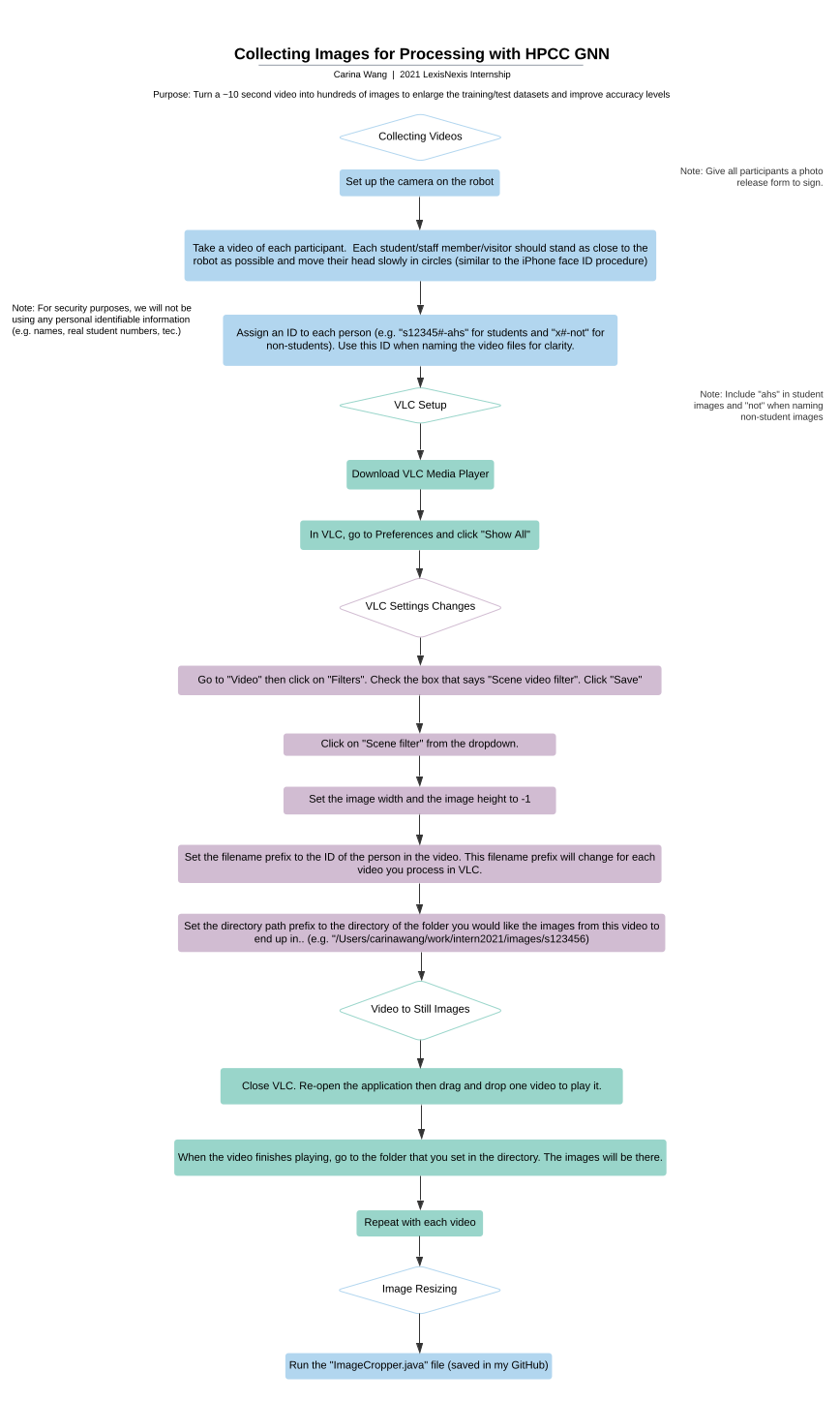
Collecting Images
What separates this project from standard machine learning procedures is the mechanism for obtaining data. Instead of artificially altering the angle of a person’s head tilt in the image, videos were taken using the camera on board the Security Robot. Within the ~10 second video, each person moved their head in circles, comparable to the process for setting up Face ID on an iPhone. The reasoning behind this was to simulate real images that the robot would capture from a consistent camera angle.
Thousands of photos were needed to build a large enough dataset to significantly test the HPCC Systems Thor functionality. The video to still-image processing was applicable because it produced 30 frames per second, setting up the long-term project by expanding the number of real images in the dataset. The images were specifically 224 x 224 (standard size for most image classification models) and BMP (the format currently supported by GNN). One option is to refer to the flowchart above and the ImageCropper.java code to alter image sizes.
Classify Images with HPCC Systems/GNN on Azure
The first step is to install the following prerequisites:
- helm
- kubectl
- Azure CLI
The Kubernetes Setup Process
The procedure listed below is based on my github repo. Remember to use the Docker image name platform-gnn and adjust Thor worker resources (cpu and memory).
Creating an Azure Kubernetes Service (AKS)
To see more details about this process, take a look at Carina’s GitHub Repo, which you can clone using the following command;
git clone https://github.com/carinaw26/HPCC-GNN-Cloud
Navigate to the correct directory:
cd Azure/AKS/ directory
Then edit the configuration file for the Azure Subscription, including the AKS resource group, region, node pool, etc.
Now you can start the Azure Kubernetes Service:
Run ./start.sh to start AKS // delete-aks.sh to delete
Deploying HPCC Systems on the Cloud Using Command Line Tools
Please Note: For other methods of deploying HPCC Systems on Azure, please reference the blog Getting Started with HPCC Systems Cloud Native Platform using Terraform.
First, download the HPCC Systems Helm Chart as follows:
-
git clone https://github.com/hpcc-systems/helm-chart.git
-
cd helm-chart/helm
-
git checkout <version>
Next, deploy the storage. You can do this with AKS lifecycle using the following command:
helm install azstorage examples/azure/hpcc-azurefile/
Alternatively, you can create a storage account and shares for a long term storage lifecycle (which can persist after AKS is destroyed).
cd examples/azure/sa
Edit env-sa
Here is an example:
SUBSCRIPTION=us-hpccplatform-dev
STORAGE_ACCOUNT_NAME=gnncarina
SA_RESOURCE_GROUP=gnn-carina-sa
SA_LOCATION=centralindia
Note: The SA_LOCATION should be the same as AKS otherwise there is a big latency.
Uncomment the shareName secretName and secretNamespace in the values.yaml file ( ../hpcc-azurefile/values.yaml)’. The run the following commands:
Run ./create-sa.sh
Run ./create-secret.sh
Next, go to the helm directory (type ../../../ at the command prompt) and run this command:
helm install azstorage examples/azure/hpcc-azurefile/
Now we are ready for the HPCC Systems Cloud Deployment
Please check the Update values.yaml file for more information on deploying the HPCC Systems platform on the cloud.
Setting global visibilities
The first step is to se the global visibilities as shown here:
global:
visibilities:
local:
annotations: service.beta.kubernetes.io/azure-load-balancer-
internal: "false"
Adding placements for Spot Instance Node Pool
Since our AKS (HPCC-GNN-Cloud/Azure/AKS/configuration) uses a Spot Instance user node pool we need to add tolerations, to allow HPCC Systems pods to be assigned to the node pool. Add following to the hpcc/values.yaml file:
placements:
- pods: ["all"]
placement:
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: "NoSchedule"
Changing Worker Resources
Create a parameter called globalMemorySize to control the amount of memory Thor workers can use.
Set it to the maximum number of GB that Thor and GNN will need. If you set the worker resources memory to 16 GB and the globalMemorySize to 10GB, there will be 6 GB left for TensorFlow. This will allow the OUTPUT functions to run properly. Here is an example for two Thor workers:
thor:
- name: thor
prefix: thor
globalMemorySize: 10000
# keepJobs: all
numWorkers: 2
maxJobs: 4
workerResources:
limits:
cpu: "4"
memory: "16GB"
Deploy
Now you are ready to deploy using the following command:
helm install hpcc hpcc --set global.image.version=<version> --set
global.image.name platform-gnn -f examples/azure/values-retained-azurefile.yaml
Get the ECLWatch IP
To find out the IP address and port for ECL Watch, use the following command:
kubectl get service
Uploading Files and Spraying Data using ECL Watch and via the Command Line
Normally you should prepare two sets of image files because 80% of the images should be used for training and the other 20% should be a test set. After spraying the data, you should have two logical files stored on the cluster.
For example:
ahstrain::cw //to use for training
ahstest::cw //to use for testing
Using ECL Watch
To upload files on to the Landing Zone in ECL Watch follow these steps:
- Click Files icon
- Click Landing Zones
- Click Upload to select the files you want to upload
To spray your files to the Thor cluster, follow these steps:
- Click Files icon
- Click Landing Zones
- From mydropzone select all the files you want to spray
- Click BLOB
- Fill Target Name with file name. For example ahstrain::cw
- In BLOB Prefix type: FILENAME,FILESIZE
- Click on the Overwrite check box.
- Press Spray button
Using the Command-line
With a larger dataset, it may be easier to upload and spray images through the Command Line or Terminal. To upload files you first need to find the dfuserver pod name, using the following command:
kubectl get pod
Now you can upload your directory or files, using the following command:
kubectl cp <source dir or files> <dfuserver pod name>:/var/lib/HPCCSystems/mydropzone/
To spray your files to the Thor cluster, use the dfuplus command as shown in the following example:
kubectl exec -t -- /opt/HPCCSystems/bin/dfuplus action=spray nolocal=true srcip=127.0.0.1
srcfile= <source filenames or pattern> dstname= <logical filename> dstcluster=data
overwrite=1 prefix=FILENAME,FILESIZE nosplit=1 server=<eclwatch cluster ip>:8010
Where <source filenames or pattern> are in the drop zone folder (/var/lib/HPCCSystems/mydropzone), for example:
/var/lib/HPCCSystems/mydropzone/two_folders/ahs/*.bmp
/var/lib/HPCCSystems/mydropzone/two_folders/notahs/*.bmp
And the logical file name is expressed as in the following example:
ahstrain:cw
HPCC Systems Client Tools and GNN bundle Setup
First, Install the HPCC Systems Clienttools.
Then, Install the following 3 Machine Learning Bundles:
GNN Model Development with VS Code
To install the VS Code ECL Plugins, visit the visual studio marketplace. Then go to GitHub and clone the carinaw26/HPCC-GNN-Cloud repository. Now follow these steps:
- Update the bundles path in vscode/model.code-workspace
- Open the VS Code editor and vscode/model.code-workspace
- Update the serviceAddress with your ECL Watch IP and port
- Modify the file, in this example this would be AHS_File_Images.ecl for trainImageData and testImageData with the logical files you sprayed. In this case that would be, ahstrain::cw and ahstest::cw. Save the file.
- Open the file AHS_Images.ecl and click View and Command Palette. Select ECL:Submit to run the code. This will create the datasets for training and testing.
- Open the file AHS_GNN_TL3.ecl. By default, MobileNetV2 is the selected model. You can change this to another model with function definition fdef, compiler options compileDef and parameters for GNNI. Fit. To run the code click View and Command Palette. Select ECL:Submit . To use MobileNetV2, you need to have the latest GNN function DefineKAModel. If you don’t have this, you can reference GNN Tutorial to define a simple sequential model.
Here are some samples of the code:
// Pick a Keras Application
modelName := 'MobileNetV2';
// Keras Application function definition
fdef := '''input_shape=(224,224,3),include_top=True,weights=None,classes=2''';
// compile definition
compileDef := '''compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.binary_crossentropy,
metrics=[)’acc’]) ''';
mod := GNNI.DefineKAModel(s, modelName, fdef, compileDef);
…...
mod2 := GNNI.Fit(mod, tensTrain, Ytrain, batchSize := 32, numEpochs := 5);
You can check the running progress from ECLWatch Workunit. You can also check the thor worker logs:
kubectl logs <thorworker pod name>
kubectl logs <thorworker pod name> | grep "===="
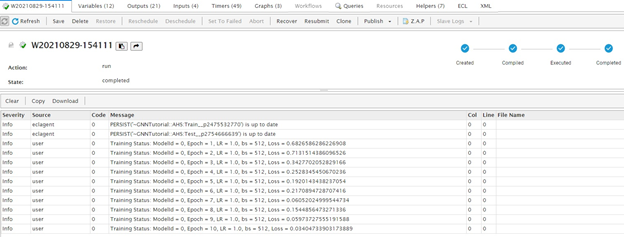
You can check outputs from the work unit for final training loss and accuracy.
If the training time takes too long, you can consider increasing the number thorworkers. You can also use trainToLoss to end the training. Reference GNsNI.ecl fit function for details.
Cleaning up
On Azure the easiest way to clean up is to delete the AKS resource group. There is a help script delete-aks.sh in my repo Azure/AKS/ directory. If you use a storage account, there is a help script delete-sa.sh in helm-chart/helm/examples/azure/sa/. You can always delete a resource group from the Azure Portal.
Known Limitations
I discovered a number of limitations during my work on this project which I thought would be useful to share with others.
TensorFlow 2 Support
Even though you can run GNN with TensorFlow 2, all of the TensorFlow 2 features are turned off in GNN. Essentially, you only can use the versions of existing models that are compatible with TensorFlow 1. Hopefully GNN will support TensorFlow 2 features in the near future such as supporting TensorFlow_Hub, Input Dataset format, new export formats and performance improvements, etc.
Exporting and Using the Trained Model
Currently you need to export the model and weights to JSON format separately and restore them in your application environment. In the future, it is suggested for GNN to support the H5 format or even be able to be saved as a TensorFlow 2 format.
Unable to use EfficientNet Models
EfficientNet series models are the latest (2019) CNN models in the Keras Application List. It takes advantage of previous models and makes lots of improvements and enhancements. Currently, EfficientNet models can’t run in GNN. I raised an issue on this in the HPCC Systems Community Issue tracker JIRA (see the issue here).
GNN Performance
We mainly compare the performance with pure Python/TensorFlow 2 which can be an ECL embedded python code. GNN’s relatively slow speed could be attributed to the following:
- User’s inefficient code. The sample code used in this project is mainly from the HPCC Systems GNN Tutorial.
- Difference between TensorFlow V1 and V2. GNN currently runs with TensorFlow V1
- GNN implementation
GPU support on Azure
I discovered a a general problem effecting parsing yaml (possibly JSON too), where the underlying ptree structure is being used for property formats it doesn’t support. An issue relating to this was raised in the HPCC Systems Community Issue tracker JIRA (see the issue here).
Troubleshooting
While working through some issues, I discovered these useful troubleshooting tips.
Terminate failed job
If your execution failed but thorworkers doesn’t terminate you can run the following code to delete them:
kubectl delete job --all
Index out of range for certain ECL OUTPUT commands
You may receive an Index Out of Range error when outputting training metrics and predictions (predDat). There is a JIRA ticket HPCC-26366 about this. This could be due to the fact that most models have a large number of parameters. Check https://keras.io/api/applications/ for the details. Normally you should increase outputLimit with OPTION(‘outputLimit’,100). 100 for MobileNetV2, 500 for InceptionResNetV2 and ResNet152V2 and 800 for VGG19. You also need set enough memory for the thorworker and Python/TensorFlow
Thorworker states OOMKilled
OOM stands for Out of Memory which means the thorworker pod doesn’t have enough memory to complete the task.
With my dataset, TensorFlow needs ~6 GB Memory. Thor and GNN need at least 6 more GB. The problem is that no matter what you set the memory to, Thor will use up most of it and not leave enough for TF. The solution is to create a parameter called global Memory size to control the amount of memory Thor workers can use. Set globalMemorySize to the maximum number of GB Thor and GNN will need
Congratulations to Carina Wang
It must be clear to anyone reading this blog that Carina is a talented technologist with a clear understanding of what was an ambitious and in depth project, using some advanced machine learning techniques. We have had high school students join the HPCC Systems Intern Program since 2017 and it is great to be able to offer them the opportunity to practice and develop the skills they already bring to the table. It is also great to see teachers in schools, like Taiowa Donovan, champion STEM related programs which encourage students like Carina, to have the confidence to have a go at contributing to challenging technology based projects.
You can find more information about HPCC Systems Academic Program and its collaboration with American Heritage school’s autonomous robotics projects by watching these presentations & videos.
The Director of the robotics program at (AHS) Taiowa Donovan and David de Hilster, Software Engineer for LexisNexis Risk Solutions Group mentored Carina during her internship. Both were clearly impressed to work with such an incredibly talented young person like and had this to say about her work:
“Carina’s work with the HPCC Systems Machine Learning Library exercised its performance capabilities and helped improve its processes.” – David de Hilster
“The evolution of our Autonomous Security Robot project has been huge with the addition of Carina Wang as Project Manager. Carina’s contributions have taken us to new heights and has specifically intertwined our project with HPCC Systems in a much more concrete way. Her work on the project during her internship with HPCC Systems has given our robot platform so much more substance with improvements in object recognition, facial recognition and the ability to process the large volume of data. Processing student images on the HPCC Systems Cloud Native Platform facilitated a model’s classification of an individual as an AHS student or Not an AHS student. The work Carina did during her internship will be a continued focus as the project moves forward in the years to come.” – Taiowa Donovan
“Besides embracing new technical directions to her original project plan, Carina took on what at first seemed as an insurmountable task. With persistence and encouragement, she got the school lawyers to draft a new likeness release form that included image processing. That was some real growth from Carina.” – David de Hilster
Congratulations and thanks to Carina for suggesting this project and executing on her project proposal to the very highest standard. She has made valuable contributions to both the HPCC Systems Open Source Project and the AHS Autonomous Security Robot that will continue to be used and built on for many years to come.